







与《【Mapreduce】利用单表关联在父子关系中求解爷孙关系》(点击打开链接)一样的键值对。
Tom Lucy
Tom Jack
Jone Lucy
Jone Jack
Lucy Mary
Lucy Ben
Jack Alice
Jack Jesse
Terry Alice
Terry Jesse
Philip Terry
Philip Alma
Mark Terry
Mark Alma只是这次是假设一个没有重复,也就是不会出现Tom Lucy-Lucy Tom这样的好友关系表。
任务是求其其中的二度人脉、潜在好友,也就是如下图:
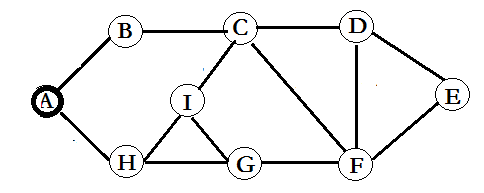
比如I认识C、G、H,但C不认识G,那么C-G就是一对潜在好友,但G-H早就认识了,因此不算为潜在好友。
最终得出的是,如下的一个,没有重复的,首字母接近A再前的,也就Tom Mary-MaryTom只输出Mary Tom,因为M比T更接近A:
Alice Jesse
Alice Jone
Alice Mark
Alice Philip
Alice Tom
Alma Terry
Ben Jone
Ben Mary
Ben Tom
Jack Lucy
Jack Terry
Jesse Jone
Jesse Mark
Jesse Philip
Jesse Tom
Jone Mary
Jone Tom
Mark Philip
Mary Tom思路如下:
首先,我们进行第一个MapReduce:
1、与《【Mapreduce】利用单表关联在父子关系中求解爷孙关系》(点击打开链接)相同,同样是一个输入行,产生一对互逆的关系,压入context
例如Tom Lucy这个输入行就在Map阶段搞出Tom Lucy-Lucy Tom这样的互逆关系。
2、之后Map-reduce会自动对context中相同的key合并在一起。
例如由于存在Tom Lucy、Tom Jack,显然会产生一个Tom:{Lucy,Jack}
这是Reduce阶段以开始的键值对。
3、这个键值对相当于Tom所认识的人。先进行如下的输出,1代表Tom的一度人脉
Tom Lucy 1
Tom Jack 1
潜在好友显然会在{Lucy,Jack}这个Tom所认识的人产生,对这个数组做笛卡尔乘积,形成关系:{<Lucy,Lucy>,<Jack,Jack>,<Lucy,Jack>,<Jack,Lucy>}
将存在自反性,前项首字母大于后项剔除,也就是<Lucy,Lucy>这类无意义的剔除,<Lucy,Jack>,<Jack,Lucy>认定为一个关系,将剩余关系进行如下的输出,其中2代表Tom的二度人脉,也就是所谓的潜在好友:
Lucy Jack 2
此时,第一个MapReduce,输出如下:
Alice Jack 1
Alice Terry 1
Jack Terry 2
Alma Philip 1
Alma Mark 1
Mark Philip 2
Ben Lucy 1
Jack Jesse 1
Jack Tom 1
Jack Jone 1
Alice Jack 1
Jesse Tom 2
Jesse Jone 2
Jone Tom 2
Alice Jesse 2
Alice Tom 2
Alice Jone 2
Jesse Terry 1
Jack Jesse 1
Jack Terry 2
Jack Jone 1
Jone Lucy 1
Jack Lucy 2
Ben Lucy 1
Jone Lucy 1
Lucy Tom 1
Lucy Mary 1
Ben Jone 2
Ben Tom 2
Ben Mary 2
Jone Tom 2
Jone Mary 2
Mary Tom 2
Alma Mark 1
Mark Terry 1
Alma Terry 2
Lucy Mary 1
Philip Terry 1
Alma Philip 1
Alma Terry 2
Philip Terry 1
Alice Terry 1
Mark Terry 1
Jesse Terry 1
Alice Philip 2
Alice Mark 2
Alice Jesse 2
Mark Philip 2
Jesse Philip 2
Jesse Mark 2
Jack Tom 1
Lucy Tom 1
Jack Lucy 2
这时,形式已经很明朗了,再进行第二个Mapreduce,任务是剔除本身就存在的关系,也就是在潜在好友中剔除本身就认识的关系。
将上述第一个Mapreduce的输出,关系作为key,后面的X度人脉这个1、2值作为value,进行Mapreduce的处理。
那么例如<Jack Lucy>这个关系,之所以会被认定为潜在好友,是因为它所对应的值数组,里面一个1都没有,全是2,也就是它们本来不是一度人脉,而<Alma Mark>这对,不能成为潜在好友,因为他们所对应的值数组,里面有1,存在任意一对一度人脉、直接认识,就绝对不能被认定为二度人脉。
将被认定为二度人脉的关系输出,就得到最终结果。
其实这个Mapreduce就是做了一件类似《【Mapreduce】去除重复的行》(点击打开链接)的事情,只是在Reduce增加的一个输出判断。
因此代码如下:
import java.io.IOException;
import java.util.ArrayList;
import java.util.Random;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class MyMapReduce {
//第一轮MapReduce
public static class Job1_Mapper extends Mapper<Object, Text, Text, Text> {
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
String[] line = value.toString().split(" ");// 输入文件,键值对的分隔符为空格
context.write(new Text(line[0]), new Text(line[1]));
context.write(new Text(line[1]), new Text(line[0]));
}
}
public static class Job1_Reducer extends Reducer<Text, Text, Text, Text> {
public void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
ArrayList<String> potential_friends = new ArrayList<String>();
//这里一定要用string存,而不是用Text,Text只是一个类似指针,一个MapReduce的引用
//换成用Text来存,你会惊讶,为何我存的值都一模一样的?
for (Text v : values) {
potential_friends.add(v.toString());
if (key.toString().compareTo(v.toString()) < 0) {// 确保首字母大者再前,如Tom Alice则输出Alice Tom
context.write(new Text(key + "\t" + v), new Text("1"));
} else {
context.write(new Text(v + "\t" + key), new Text("1"));
}
}
for (int i = 0; i < potential_friends.size(); i++) {// 潜在好友集合自己与自己做笛卡尔乘积,求出潜在的二度人脉关系
for (int j = 0; j < potential_friends.size(); j++) {
if (potential_friends.get(i).compareTo(//将存在自反性,前项首字母大于后项的关系剔除
potential_friends.get(j)) < 0) {
context.write(new Text(potential_friends.get(i) + "\t"
+ potential_friends.get(j)), new Text("2"));
}
}
}
}
}
//第二轮MapReduce
public static class Job2_Mapper extends Mapper<Object, Text, Text, Text> {
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
String[] line = value.toString().split("\t");//输入文件,键值对的分隔符为\t
context.write(new Text(line[0] + "\t" + line[1]), new Text(line[2]));//关系作为key,后面的X度人脉这个1、2值作为value
}
}
public static class Job2_Reducer extends Reducer<Text, Text, Text, Text> {
public void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
//检查合并之后是否存在任意一对一度人脉
boolean is_potential_friend = true;
for (Text v : values) {
if (v.toString().equals("1")) {
is_potential_friend = false;
break;
}
}
//如果没有,则输出
if (is_potential_friend) {
String[] potential_friends = key.toString().split("\t");
context.write(new Text(potential_friends[0]), new Text(
potential_friends[1]));
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args)
.getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
// 判断output文件夹是否存在,如果存在则删除
Path path = new Path(otherArgs[1]);// 取第1个表示输出目录参数(第0个参数是输入目录)
FileSystem fileSystem = path.getFileSystem(conf);// 根据path找到这个文件
if (fileSystem.exists(path)) {
fileSystem.delete(path, true);// true的意思是,就算output有东西,也一带删除
}
//设置第一轮MapReduce的相应处理类与输入输出
Job job1 = new Job(conf);
job1.setMapperClass(Job1_Mapper.class);
job1.setReducerClass(Job1_Reducer.class);
job1.setOutputKeyClass(Text.class);
job1.setOutputValueClass(Text.class);
// 定义一个临时目录,先将任务的输出结果写到临时目录中, 下一个job以临时目录为输入目录。
FileInputFormat.addInputPath(job1, new Path(otherArgs[0]));
Path tempDir = new Path("temp_"
+ Integer.toString(new Random().nextInt(Integer.MAX_VALUE)));
FileOutputFormat.setOutputPath(job1, tempDir);
if (job1.waitForCompletion(true)) {//如果第一轮MapReduce完成再做这里的代码
Job job2 = new Job(conf);
FileInputFormat.addInputPath(job2, tempDir);
//设置第二轮MapReduce的相应处理类与输入输出
job2.setMapperClass(Job2_Mapper.class);
job2.setReducerClass(Job2_Reducer.class);
FileOutputFormat.setOutputPath(job2, new Path(otherArgs[1]));
job2.setOutputKeyClass(Text.class);
job2.setOutputValueClass(Text.class);
FileSystem.get(conf).deleteOnExit(tempDir);//搞完删除刚刚的临时创建的输入目录
System.exit(job2.waitForCompletion(true) ? 0 : 1);
}
}
}需要注意的问题都写在注释的。
使用到多重Mapreduce其实很简单的,一句类似等待线程结束的job1.waitForCompletion(true)将其从原来的System.exit移出来,作为判断条件,再于里面的条件结构设定并提交job2,等job2完成,再结束这个程序即可。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









