






Conclusion Combined with chatgpt
Sinkhorn距离与算法
Sinkhorn是一个与概率分布和离散优化相关的数学概念和算法。这个名词通常与Sinkhorn距离和Sinkhorn算法相关联。
-
Sinkhorn距离:Sinkhorn距离,也称为Entropic Wasserstein距离,是两个概率分布之间的一种距离度量方法。它可以用来衡量两个分布之间的相似性或差异性。Sinkhorn距离引入了一个正则化参数,用于控制两个分布之间的匹配程度和“熵”的平衡。
-
Sinkhorn算法:Sinkhorn算法是一种用于计算Sinkhorn距离的迭代优化算法。它被广泛用于处理高维数据和大规模概率分布的匹配问题。Sinkhorn算法的关键思想是通过迭代调整两个分布的权重来逐渐逼近其Sinkhorn距离。这个算法在解决Wasserstein距离相关的优化问题时非常有用。
具体算法:
对于一个矩阵,先逐行做归一化,就是将第一行的每个元素除以第一行每个元素的和,得到
新的"第一行";对于每行都做相同的操作; 再逐列做归一化。 重复以上的两步,最终可以收敛
到一个行和为1,列和也为1的Doubly stochastic matrix
def sinkhorn_iter(self, log_alpha, n_iters=5, slack=True, eps=-1):
''' Run sinkhorn iterations to generate a near doubly stochastic matrix, where each row or column sum to <=1
Args:
log_alpha: log of positive matrix to apply sinkhorn normalization (B, J, K)
n_iters (int): Number of normalization iterations
slack (bool): Whether to include slack row and column
eps: eps for early termination (Used only for handcrafted RPM). Set to negative to disable.
Returns:
log(perm_matrix): Doubly stochastic matrix (B, J, K)
Modified from original source taken from:
Learning Latent Permutations with Gumbel-Sinkhorn Networks
https://github.com/HeddaCohenIndelman/Learning-Gumbel-Sinkhorn-Permutations-w-Pytorch
'''
prev_alpha = None
if slack:
zero_pad = nn.ZeroPad2d((0, 1, 0, 1))
log_alpha_padded = zero_pad(log_alpha[:, None, :, :])
log_alpha_padded = torch.squeeze(log_alpha_padded, dim=1)
for i in range(n_iters):
# Row normalization
log_alpha_padded = torch.cat((
log_alpha_padded[:, :-1, :] - (torch.logsumexp(log_alpha_padded[:, :-1, :], dim=2, keepdim=True)),
log_alpha_padded[:, -1, None, :]), # Don't normalize last row
dim=1)
# Column normalization
log_alpha_padded = torch.cat((
log_alpha_padded[:, :, :-1] - (torch.logsumexp(log_alpha_padded[:, :, :-1], dim=1, keepdim=True)),
log_alpha_padded[:, :, -1, None]), # Don't normalize last column
dim=2)
if eps > 0:
if prev_alpha is not None:
abs_dev = torch.abs(torch.exp(log_alpha_padded[:, :-1, :-1]) - prev_alpha)
if torch.max(torch.sum(abs_dev, dim=[1, 2])) < eps:
break
prev_alpha = torch.exp(log_alpha_padded[:, :-1, :-1]).clone()
log_alpha = log_alpha_padded[:, :-1, :-1]
else:
for i in range(n_iters):
# Row normalization (i.e. each row sum to 1)
log_alpha = log_alpha - (torch.logsumexp(log_alpha, dim=2, keepdim=True))
# Column normalization (i.e. each column sum to 1)
log_alpha = log_alpha - (torch.logsumexp(log_alpha, dim=1, keepdim=True))
if eps > 0:
if prev_alpha is not None:
abs_dev = torch.abs(torch.exp(log_alpha) - prev_alpha)
if torch.max(torch.sum(abs_dev, dim=[1, 2])) < eps:
break
prev_alpha = torch.exp(log_alpha).clone()
return log_alpha
M = sinkhorn_iter(M, n_iters=20).squeeze().exp() # M三维torch.logsumexp(torch.tensor([1.0, 2.0, 3.0]), dim=0):
两种分布之间的距离,通常有KL散度,JS散度,Wasserstein距离等计算方式。
- KL散度:
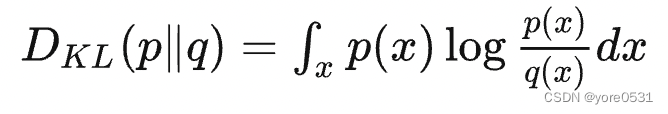
KL散度有弊端 :KL散度不对称:用p“指导”q,和p指导q,距离会不相等。
- JS散度:
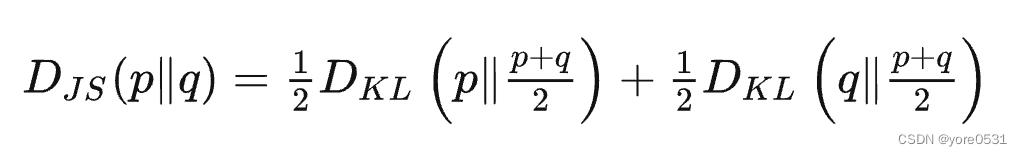
KL和JS都有一个共同弊端:当两个分布,如果不相交的时候,我们只能算出来KL距离是0。
或者两个分布之间的重叠区域很小,如何移动p、q之间的距离,JS和KL计算出来的结果都不变。
Wasserstein距离
Wasserstein距离又称挖土机距离(EMD:Earth Mover's distance)或Optimal Transport Distance。它不仅考虑两个分布之间的差异,还考虑如何将一个分布中的质量(物质、信息等)转移到另一个分布以匹配它。
假设有两堆土。每一堆都在不同的地方,有不同的形状和大小。你的任务是将一堆土移动并重新形状,使其与另一堆土的形状和位置相匹配。移动土壤的“成本”与你移动土壤的“距离”成正比。最优传输问题的目标是找到移动和重塑这些土堆的最便宜(或最优)方式,使得一堆土变得尽可能像另一堆土。这种移动的代价通常由一个成本矩阵(cost matrix)给定,它表示从一个位置到另一个位置的移动成本。
最优传输问题提供了一种强大的方法来测量和比较分布,尤其是当传统的距离度量(如KL散度或总变差)不适用或不足够的时候。
EMD缺陷:
1. 计算量太大 2.解比较稀疏
因此引入了Sinkhorn距离。
NP问题 "Nondeterministic Polynomial time"
P:可以快速解决的问题:这类问题的答案可以在合理的时间内直接找到。比如,你有一堆数,你想知道它们的总和是多少。即使这堆数很大,你还是可以在合理的时间内求出它们的总和。
NP:可以快速验证答案的问题:对于这类问题,即使你不知道如何快速地得到答案,但如果有人给你一个答案,你可以很快地检查这个答案是否正确。比如,一个非常大的拼图,你不确定如何迅速完成它,但如果有人告诉你它拼好后的样子,你可以很快地检查是否拼对了。
NP 的定义:对于问题的每一个正面答案(即答案为 "是"),如果存在一个多项式时间算法,该算法可以验证一个提供的证据(或解)是否正确,那么这个问题就属于 NP 类。
Quadratic Assignment Problem二次分配问题
假设成立一个新的公司的诸多部门,每个部门需要一个位置:
-
交流问题:有些部门之间需要频繁交流。例如,市场部和工程部可能需要经常会议,所以它们之间的距离越近越好。这种“需要多少交流”的信息可以放在一个“交流频率表”里。
-
位置问题:这块地上的建筑位置之间的距离各不相同。有些位置之间很近,有些则远。这种位置之间的距离可以放在一个“距离表”里。
QAP就是找出最佳的部门与位置的配对方式,以使得基于交流需求和位置距离的总成本最小化。
可以使用精确的方法来求解小的 QAP 实例,但对于较大的实例,我们通常依赖于启发式或近似方法
-
精确方法:
- 分支和界限法 (Branch and Bound):这种方法是通过构建解的部分序列并使用界限估计来排除那些不能产生最佳解的序列部分。
- 分支和剪枝法 (Branch and Cut):这是一个结合分支和界限法与切割平面方法的技巧。
-
启发式方法:
- 贪婪算法 (Greedy algorithms):构建解决方案的每个步骤都采取当前看起来最佳的选择。
- 局部搜索 (Local Search):从一个初始解开始,然后在邻域内迭代查找更好的解。
- 模拟退火 (Simulated Annealing):一种随机搜索方法,允许一些劣化的移动以跳出局部最优。
- 遗传算法 (Genetic Algorithms):模拟自然选择的搜索算法,结合了继承、变异、选择和交叉等机制。
- 禁忌搜索 (Tabu Search):一种局部搜索方法,使用记忆结构来避免回到近期访问过的解。
-
近似方法:
- 近似算法是为了得到问题的一个近似解,通常有一个已知的近似比率。
-
混合方法和杂交方法:
- 这些方法结合了上述的多种策略,例如结合遗传算法和局部搜索。
-
分解策略:
- 例如拉格朗日松弛 (Lagrangian Relaxation) 或 Benders 分解。
-
现代机器学习方法:
- 深度学习和强化学习近年来也已被应用于组合优化问题,包括 QAP。















 2348
2348











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









