










24年5月来自创业公司极佳、中科院、新加坡国立、上海AI实验室、迈驰智行、国防科大、西工大和清华等的论文 “Is Sora a World Simulator? A Comprehensive Survey on General World Models and Beyond”。
通用世界模型是实现通用人工智能 (AGI) 的重要途径,是从虚拟环境到决策系统等各种应用的基石。最近,Sora模型的出现因其卓越的模拟能力而引起了广泛关注,呈现出对物理定律的初步理解。
该综述对世界模型的最新进展进行了全面的探索,贯穿了视频生成中生成方法的前沿,其中世界模型是促进高度逼真视觉内容合成的关键结构。此外,对于自动驾驶世界模型的新兴领域,本文给出在重塑交通和城市流动性方面不可或缺的作用。此外,自主智体中部署的世界模型存在固有的复杂性,意味着在动态环境背景下实现智能交互的深远意义。最后,提到研究世界模型的挑战和局限性,以及潜在的未来方向。
如图所示,这里重点关注视频生成的世界模型、自动驾驶的世界模型以及自主智体的世界模型。视频生成世界模型专注于条件视频生成和各种视频编辑任务。这些视频生成技术有助于理解自动驾驶和自动智体世界模型中的复杂场景和决策过程。这些世界模型的应用非常广泛,从媒体制作和艺术表达到自动驾驶和智体系统中的动作预测。

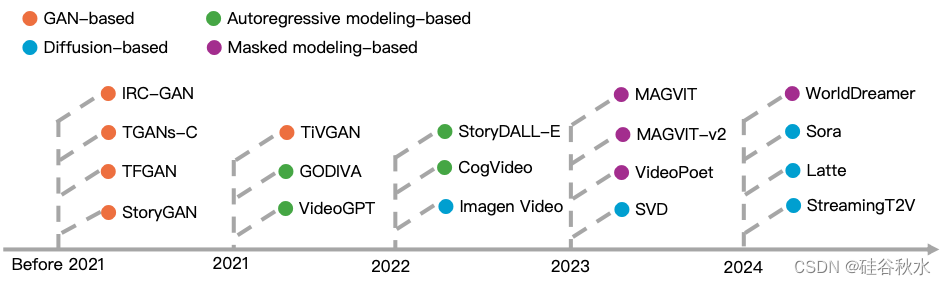
根据给定的条件(例如,类、音频、文本、图像或视频),在生成过程中,视频生成任务可以分为不同的类别,即GAN、扩散模型、自回归模型和掩码建模方法,如下图所示。以文本到视频的方法为重点,旨在生成在语义上与给定文本一致的视频,同时保持不同帧之间的一致性。在其他条件下产生想法的方法可以从文本到图像模型进行修改。

如图是视频生成模型的时间概述,包括近年来提出的代表性模型。 2021 年之前,基于 GAN 的模型将主导视频生成。之后,基于自回归建模、基于扩散和基于掩码建模的模型开始出现,并取得了令人惊讶的性能。
训练文本到视频生成模型需要大规模的视频文本对。在下表中,展示了几个流行的数据集。这些数据集也可用于训练多模态模型。

评估视频生成性能的指标有所不同。例如,Latte [143] 和 VideoGPT [229] 通过 Fre ́chet Video Distance (FVD) [203] 来衡量性能。 CLIP相似度(CLIPSim)[220]也是一种常见的评估方法。人类评估作为这些指标的补充在现有工作中也被广泛采用。由于评估分数与随机种子高度相关,因此不容易进行公平比较。此外,不同的方法可能采用不同的数据集来评估性能,这进一步加剧了这个问题。人类偏好的标注可能是视频生成评估的潜在解决方案。最近,为了比较公平性,提出了一些综合基准[97]、[133]、[134]。
Sora 是 OpenAI 开发的闭源文本到视频生成模型。除了能够生成一分钟的高保真视频外,它还展示了一些模拟现实世界的能力。它通过视频生成模型为世界模型指明了一条道路。
Sora 被认为是一种基于扩散的视频生成模型。它由三部分组成:1. 压缩模型,将原始视频在时间和空间上压缩为潜在表征;以及反对称模型,将潜在表征映射回原始视频。 2. 基于 Transformer 的扩散模型,类似于 DiT [164],在潜空间中进行训练。 3. 将人类指令编码为嵌入并将其注入生成模型的语言模型。
如图所示Sora的可能架构:

根据 OpenAI 的说法,Sora 可以充当世界模拟器,因为它可以理解动作的结果。比如Sora 生成了一个视频,画家可以在画布上留下新的笔画,这些笔画会随着时间的推移而持续存在。另一个例子是,一个人可以吃一个汉堡并留下咬痕,这表明Sora可以预测吃的结果。这两个例子表明Sora可以理解世界并预测行动的结果。这种能力与世界模型的目标非常一致:通过预测未来来了解世界。因此Sora背后的技术可以进一步激发人们对世界模型的探索。
驾驶需要应对不确定性。了解自动驾驶固有的不确定性对于做出安全决策至关重要,即使是一个小错误也可能造成致命的后果[89]。不确定性有两种主要形式:认知不确定性,源于知识或信息的缺乏;随意不确定性,植根于现实世界固有的随机性[57]。为了确保安全驾驶,必须利用世界模型中的过去经验来有效减轻任意和认知的不确定性。
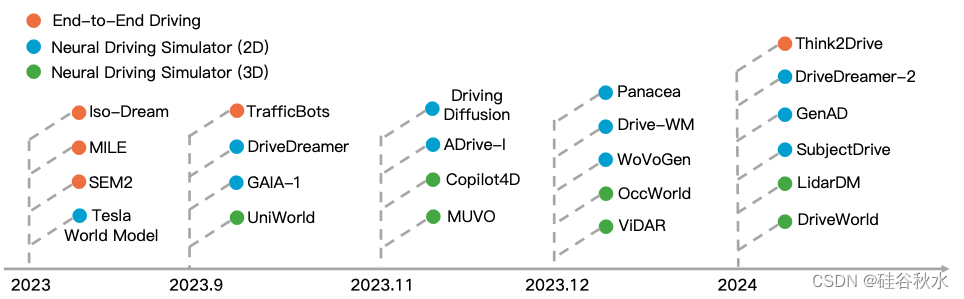
世界模型擅长通过预测未来变化来表示智体关于其环境的时空知识[115]。自动驾驶中存在两种主要类型的世界模型,旨在减少驾驶不确定性,即端到端驾驶的世界模型和神经驾驶模拟器的世界模型。在仿真环境中,MILE[90]和TrafficBots[248]等方法不区分认知不确定性和任意不确定性,将其纳入基于强化学习的模型中,增强其决策和未来预测的能力,从而为端到端自动驾驶的方式铺平道路。在真实环境中,Tesla [156] 以及 GAIA-1 [91] 和 Copilot4D [246] 等方法涉及利用生成模型构建神经驾驶模拟器,生成 2D 或 3D 未来场景以增强预测能力,从而减少任意不确定性。此外,生成新样本可以减轻有关罕见情况(例如极端情况)的认知不确定性。如图所示说明了自动驾驶中的这两种类型的世界模型。神经驾驶模拟器又可以进一步细分为两类:生成2D图像的神经驾驶模拟器和模拟3D场景的神经驾驶模拟器。
端到端自动驾驶方法[60]、[90]、[159]致力于通过最小化搜索空间并在 CARLA 模拟器上集成视觉动力学的显式求解来应对这些挑战[49]。现有基于世界模型的端到端驾驶方法的比较如表所示。在自动驾驶领域,世界模型的开发在努力构建环境的动态表示时发挥着至关重要的作用。对未来的准确预测对于确保在环境中安全操纵至关重要。然而,构建自动驾驶的世界模型提出了独特的挑战,主要源于驾驶场景中复杂的样本复杂性。

世界模型对于理解和模拟复杂的物理世界至关重要[91]。最近的一些努力将扩散模型[85]引入自动驾驶领域,以构建作为神经模拟器的世界模型,以生成必要的自主2D驾驶视频[91]、[93]、[209]、[231]。此外,一些方法采用世界模型来生成描绘未来场景的 3D 占用网格或 激光雷达点云 [19]、[152]、[233]、[246]。下表概述了这些基于世界模型的神经驾驶模拟器方法,分为2D和3D两种。高质量的数据是训练深度学习模型的基石。虽然文本和图像数据很容易以低成本获得,但由于时空复杂性和隐私问题等因素,自动驾驶领域的数据获取面临着挑战。对于解决直接影响实际驾驶安全的长尾目标尤其如此。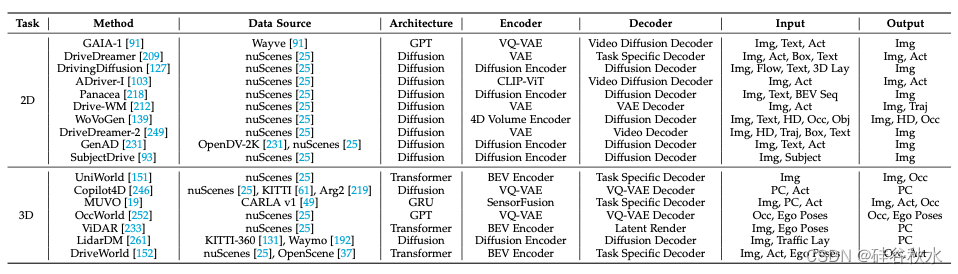
在人工智能中,自主智体是指能够通过传感器(例如摄像头)感知周围环境并通过执行器对其采取行动以实现特定目标的系统[58]。这些智体可以是物理的,例如机器人,也可以是虚拟的,例如在数字环境中执行任务的软件程序。
给定一个目标,智体需要规划一系列行动。已知环境中已经有许多成功的动态规划算法。然而,在大多数情况下,环境是复杂且随机的,因此很难根据人类经验进行明确建模。因此,该领域的核心主题是智体如何在未知且复杂的环境中学习规划。解决这个问题的一种方法是让智体直接从与环境的交互中积累经验并学习行为,而不需要对环境的状态变化进行建模(即所谓的无模型强化学习)。虽然这种解决方案简单且灵活,但学习过程依赖于与环境的许多交互,这可能非常昂贵,甚至是不可接受的。
世界模型 [69]是强化学习领域第一个引入此概念的工作,从智体的经验中对有关世界的知识进行建模,并获得预测未来的能力。这项工作表明,即使是简单的 RNN 模型也可以捕获环境的动态并支持智体学习和演化该模型中的策略。这种学习范式被称为想象中的学习[72]。通过世界模型,可以大大降低试验和失败的成本[222]。
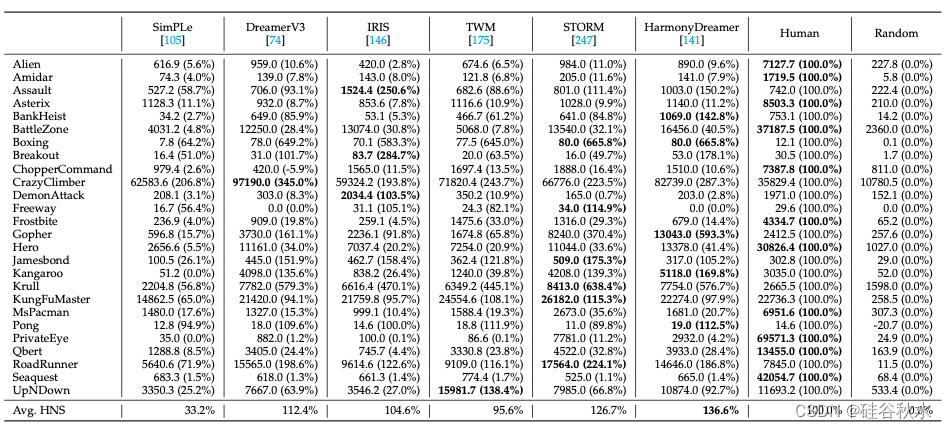
让人工智能系统学习玩游戏长期以来一直是一个有趣的话题。对游戏智体的研究不仅可以改善游戏体验,更重要的是帮助人们开发更先进的算法和模型。如下表是游戏智体得分的总结:
让智体学会操纵机器人是一项长期挑战。智体需要自主规划、做出决策并控制执行器(例如机器人手臂和腿),以完成与物理世界的复杂交互。常见的基本任务包括行走、跑步、跳跃、抓握、搬运和放置物体。一些更复杂的任务需要几个基本任务的组合,例如从抽屉中取出特定物品或煮一杯咖啡。
机器人与游戏智体的一个区别在于,机器人的目标是与真实环境进行交互,这不仅使得环境动态更加复杂和随机,而且大大增加了训练过程中与环境交互的成本。因此,在此类场景下减少与环境的交互步骤并提高采样效率就显得尤为重要。另外,执行器的控制是在连续的动作空间中,这与游戏环境中的离散动作空间也有很大不同。
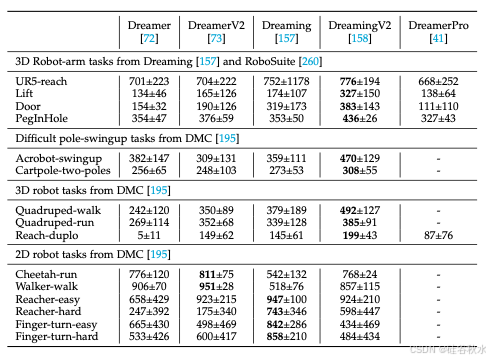
如表所示基于世界模型的机器人智体性能:
尽管最近对一般世界模型[23]、[69]以及自动驾驶等领域的特定应用的研究激增[91]、[103]、[139]、[152]、[209]、[212]、[ 231]、[246]、[252]和机器人技术[72]、[73]、[74]、[222],许多挑战和机遇等待进一步探索。
一般世界模型旨在表示和模拟各种情况和交互,就像在现实世界中遇到的情况和交互一样。生成模型的最新进展极大地提高了视频生成质量。值得注意的是,Sora 可以创建长达一分钟的高清视频,致密地模仿物理世界,显示出通用世界模型的巨大潜力。然而,解决现有问题和挑战对于未来的进步至关重要。
尽管人们对自动驾驶的世界模型进行了广泛的研究,但与熟练的人类驾驶员所拥有的心理世界模型相比,世界模型的当前状态仍然处于初级阶段。在动作可控性、3D 一致性和克服数据限制等领域仍然存在重大挑战。尽管如此,作者认为自动驾驶的基础模型将基于世界模型,实现对物理世界的有效交互和全面理解。
最后自主智体包括现实世界中的物理机器人和数字环境中的智体。世界模型不仅能够模拟物理世界的复杂性,还能模拟数字环境的细微差别。从自主智体的角度来看,世界模型提出了一些新的挑战和机遇。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









