









24年5月香港理工的论文“A Survey on Occupancy Perception for Autonomous Driving: The Information Fusion Perspective“。
3D 占据感知技术旨在观察和理解自动驾驶车辆的密集 3D 环境。该技术凭借其全面的感知能力,正在成为自动驾驶感知系统的发展趋势,受到工业界和学术界的高度关注。与传统的鸟瞰(BEV)感知类似,3D占据感知具有多源输入的性质和信息融合的必要性。然而,不同之处在于它捕获了 2D BEV 忽略的垂直结构。
该综述回顾了 3D 占据感知的最新研究成果,并对各种输入模态的方法进行了深入分析。具体来说,总结了通用网络流水线,重点介绍了信息融合技术,并讨论了有效的网络训练。在最流行的数据集上评估和分析最先进的占据感知性能。此外,还讨论了挑战和未来的研究方向。
参考文献列表:https://github.com/HuaiyuanXu/3D-Occupancy-Perception。
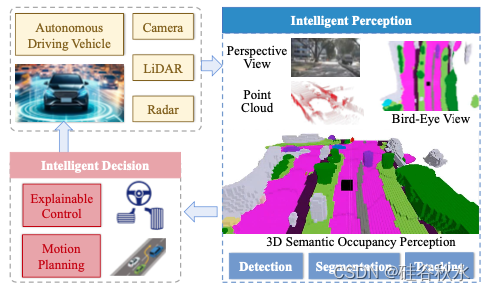
如图所示是一个自动驾驶车辆系统框图。来自摄像头、激光雷达和雷达的传感数据使车辆能够智能地感知周围环境。随后,智能决策模块生成驾驶行为的控制和规划。占据感知在3D理解、密度和无遮挡方面超越了基于透视图、鸟瞰图或点云空间的感知。
占据感知源自占据网格映射(OGM)[21],这是移动机器人导航中的经典主题,旨在从噪声和不确定的测量中生成网格图。该地图中的每个网格都分配有一个值,该值对网格空间被障碍物占据的概率进行评分。语义占据感知源自 SUNCG [22],它从单个图像预测室内场景中所有体素的占据状态和语义。然而,与室内场景相比,研究室外场景的占据感知对于自动驾驶来说是必要的。 MonoScene [23] 是仅使用单目相机进行室外场景占据感知的开创性工作。与 MonoScene 同期,特斯拉在 CVPR 2022 自动驾驶研讨会上宣布了其全新的仅摄像头占据网络[24]。这个新网络根据环视 RGB 图像全面了解车辆周围的 3D 环境。随后,占据感知引起了广泛关注,促进了近年来自动驾驶占据感知研究的激增。
早期的户外占据感知方法主要使用激光雷达输入来推断 3D 占据情况 [25,26,27]。然而,最近的方法已经转向更具挑战性的以视觉为中心的 3D 占据预测 [28,29,30,31]。目前,占据感知研究的主导趋势是以视觉为中心的解决方案,辅以以激光雷达为中心的方法和多模态方法。占据感知可以作为端到端自动驾驶框架内 3D 物理世界的统一表示 [7, 32],随后是涵盖检测、跟踪和规划等各种驾驶任务的下游应用程序。占据感知网络的训练很大程度上依赖于密集的 3D 占据标签,从而导致了多样化街景占据数据集的发展 [10,9,33,34]。最近,利用大模型的强大性能,大模型与占据感知的集成在减轻繁琐的 3D 占据注释的需求方面显示出了希望[35]。
下表详细介绍了自动驾驶占据感知的最新方法及其特征。 该表详细说明了每种方法的发布地点、输入方式、网络设计、目标任务、网络训练和评估以及开源状态。根据输入数据的形式将占据感知方法分为三种类型:以激光雷达为中心的占据感知、以视觉为中心的占据感知和多模态占据感知。
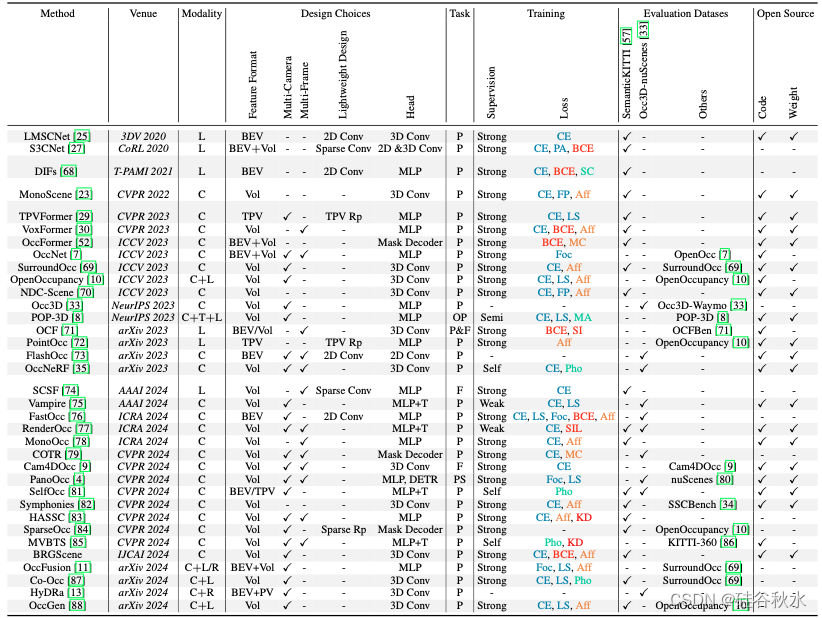
其中
模态:C——相机; L——激光雷达; R——雷达。
特征格式:Vol - 体积特征; BEV——鸟瞰图特征; PV - 透视图特征; TPV - 三透视视图特征。
轻量级设计:TPV Rp - 三透视视图表征;稀疏 Rp - 稀疏表征。
头:MLP+T - 多层感知器接着加阈值。
任务:P——预测; F——预测; OP——开放词汇预测; PS - 全景分割。
损失:[几何] BCE - 二元交叉熵,SIL - 尺度不变对数,SI - Soft-IoU; [语义]CE - 交叉熵,PA - 位置感知,FP - 平截头体比例,LS - Lovasz Softmax,Foc - 焦点; [语义和几何] Aff - 场景-类别亲和,MC - 掩码分类; [一致性] SC - 空间一致性,MA - 模态对齐,Pho - 光度一致性;【蒸馏】KD——知识蒸馏。
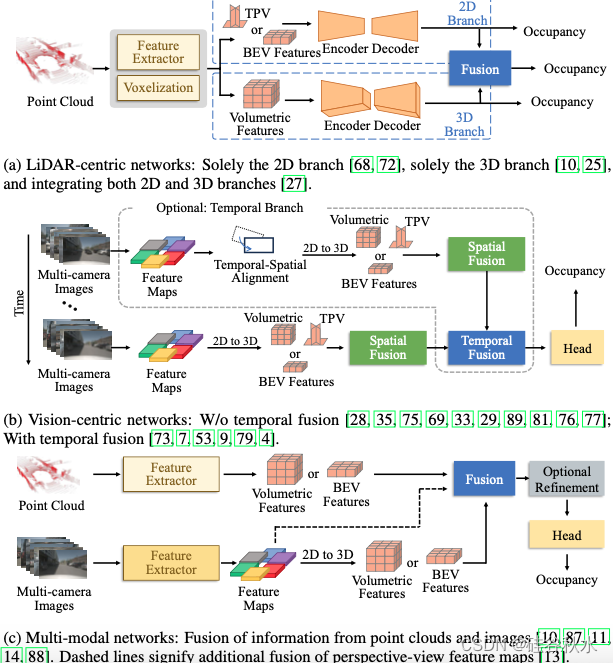
如图所示:占据感知的架构,(a)激光雷达为中心网络:2D 分支 [68, 72], 3D 分支 [10, 25], 2D-3D 分支 [27];(b)视觉为中心网络,无时域融合 [28, 35, 75, 69, 33, 29, 89, 81, 76, 77] 和带时域融合 [73, 7, 53, 9, 79, 4];(c)多模态网络:点云和图像 [10, 87, 11, 14, 88]。
以 激光雷达 为中心的语义分割 [90,91,92] 仅预测稀疏点的语义类别。相比之下,以 激光雷达 为中心的占据感知提供了对环境的密集 3D 了解,这对于自动驾驶系统至关重要。对于激光雷达传感,获取的点云本质上是稀疏的,并且会受到遮挡。这要求以激光雷达为中心的占据感知不仅能够解决场景从稀疏到密集的占据推理,而且能够实现目标从部分到完整估计[11]。
图(a) 说明了以 激光雷达 为中心的占据感知一般流程。输入点云首先进行特征提取和体素化,然后通过编码器-解码器模块进行表示增强。最终推断出场景的完整且密集的占据。
受特斯拉自动驾驶汽车感知系统技术的启发[24],以视觉为中心的占据感知已经引起了工业界和学术界的广泛关注。与以激光雷达为中心的方法相比,仅依赖于摄像头传感器的以视觉为中心占据感知代表了当前的趋势。主要有以下三个原因:(i)摄像头对于在车辆上大规模部署来说具有成本效益。 (ii) RGB 图像捕捉丰富的环境纹理,有助于理解场景和目标,例如交通标志和车道线。 (iii) 深度学习技术的迅速发展使得从 2D 视觉实现 3D 占据感知成为可能。以视觉为中心的占据感知可分为单目解决方案[97,51,23,48,49,30,52,82,78]和多摄像头解决方案[50,98,28,35,58,73, 95、29、75、7]。多摄像头感知覆盖了更广泛的视野,遵循如图 (b )所示的一般流程。它首先从多摄像头图像中提取前视图特征图,然后进行 2D 到 3D 转换、空间信息融合和可选的时间信息融合,最后得到一个推断环境 3D 占据的占据头。
如下是视觉占据网络的主要架构组件图:(a)2D-3D转换;(b)空域信息融合;(c)时域信息融合。
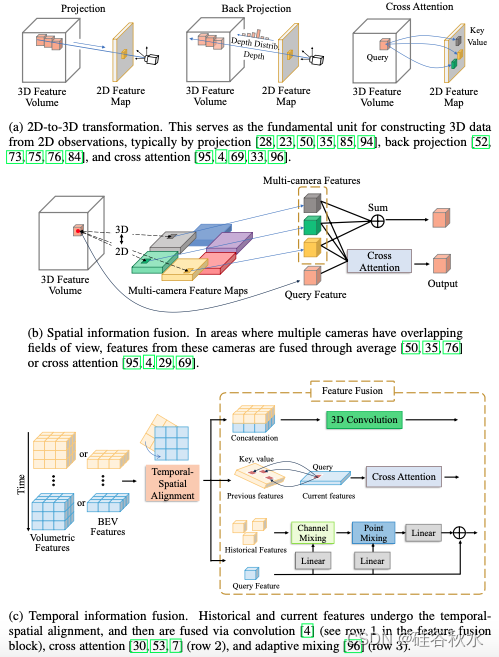
摄像头捕获的RGB图像提供了丰富而密集的语义信息,但对天气条件变化敏感且缺乏精确的几何细节。相比之下,激光雷达或雷达的点云对天气变化具有鲁棒性,并且擅长通过精确的深度测量来捕获场景几何形状。然而,它们只产生稀疏特征。多模态占据感知可以结合多种模态的优点,并减轻单模态感知的局限性。上上图(c)说明多模态占据感知的一般流程。大多数多模态方法[10,87,11,14]将2D图像特征映射到3D空间,然后将它们与点云特征融合。此外,在融合过程中结合二维透视图特征可以进一步细化表征[13]。融合表征由可选的细化模块和占据头(例如 3D 卷积或 MLP)进行处理,以生成最终的 3D 占据预测。可选的细化模块[88]可以是交叉注意力、自注意和扩散去噪的组合[108]。
如下表是多模态3-D占据数据集:
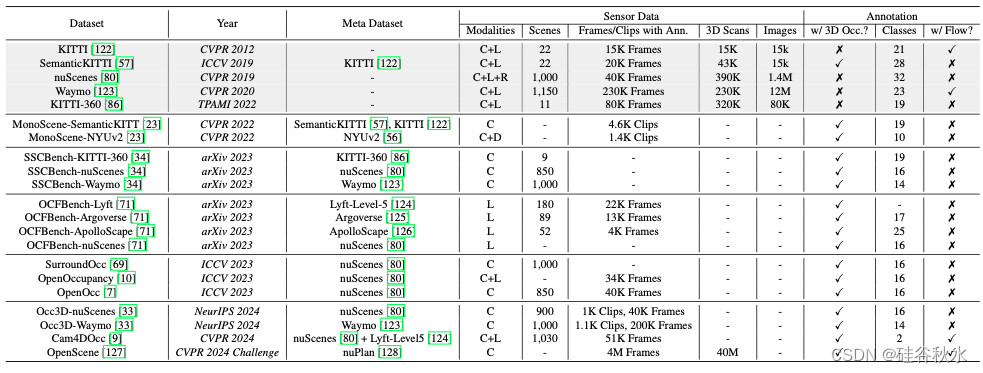
如下表是3D占据网络感知在SemanticKitti测试集的性能比较:
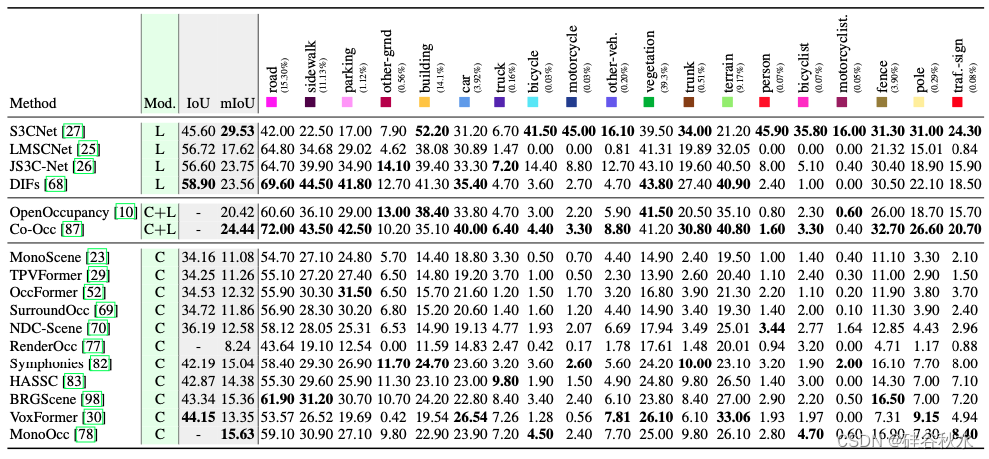
如下表是Occ3D-nuScenes数据集的3D占据感知性能:
存在的一些挑战性问题:
3D占据感知能够全面了解3D世界并支持自动驾驶中的各种任务。现有的基于占据的应用程序包括分割、检测、交通预测和规划。 (1)分割:语义占据感知本质上可以被视为3D语义分割任务。 (2)检测:OccupancyM3D [5]和SOGDet [133]是两个基于占据的实现3D目标检测的工作。 OccupancyM3D 首先学习占据率来增强 3D 特征,然后将其用于 3D 检测。 SOGDet 开发了两个并发任务:语义占据预测和 3D 目标检测,同时训练这些任务以相互增强。 (3)交通预测:Cam4DOcc[9]从占据的角度预测3D空间中的前景交通,并实现对周围3D环境变化的理解。 (4)规划:OccNet[7]将物理3D场景量化为语义占据,并训练共享占据描述符。该描述符被馈送到各个任务头以实现驾驶任务。例如,运动规划头输出自车的规划轨迹。
然而,现有的基于占据的应用主要关注感知层面,较少关注决策层面。鉴于3D占据比其他感知方式(例如鸟瞰感知和透视感知)更符合3D物理世界,3D占据在自动驾驶中拥有更广泛的应用机会。在感知层面,它可以提高现有轨迹预测、3D目标跟踪和3D车道线检测的准确性。在决策层面,它可以帮助做出更安全的驾驶决策,并为驾驶行为提供 3D 可解释性。
对于复杂的3D场景,总是需要处理和分析大量的点云数据或多视图视觉信息,以提取和更新占据状态信息。为了实现自动驾驶应用的实时性能,解决方案通常需要在有限的时间内完成计算,并且需要具有高效的数据结构和算法设计。一般来说,在目标边缘设备上部署深度学习算法并不是一件容易的事。
目前,已经尝试了一些关于占据任务的实时工作。例如, [76]提出了一种解决方案FastOcc,基于输入分辨率、视图转换模块和预测头的调整来加速预测推理速度。[96]提出了SparseOcc,一种没有任何密集3D特征的稀疏占据网络,以最小化基于稀疏卷积层和掩码引导稀疏采样的计算成本。[84]提出采用稀疏潜表示代替TPV表示和稀疏插值操作,以避免信息丢失并降低计算复杂度。然而,上述方法距离自动驾驶系统的实时部署还有一段距离。
在动态且不可预测的现实驾驶环境中,感知鲁棒性对于自动驾驶车辆的安全至关重要。最先进的 3D 占据模型可能容易受到分布外场景和数据的影响,例如照明和天气的变化(这会引入视觉偏差)以及输入图像模糊(这是由车辆移动引起的)。此外,传感器故障(例如帧和相机视图丢失)也很常见。鉴于这些挑战,研究强大的 3D 占据感知非常有价值。
然而,对鲁棒 3D 占据的研究是有限的,主要是由于数据集的稀缺。最近,ICRA 2024 RoboDrive 挑战赛 [134] 为研究稳健的 3D 占据感知提供了不完善的场景。稳健 BEV 感知的相关工作 [135,136,137,138,44,45]可以启发稳健占据感知的研究。 M-BEV [136]提出随机掩码和重建相机视图,以增强各种丢失相机情况下的鲁棒性。 GKT [137] 采用粗投影来实现鲁棒的 BEV 表征。在大多数涉及自然损坏的场景中,多模态模型[138,44,45]通过多模态输入的互补性优于单模态模型。此外,在3D LiDAR感知中,Robo3D[139] 将知识从具有完整点云的教师模型提炼到具有不完善输入的学生模型,从而增强了学生模型的鲁棒性。基于这些工作,实现稳健的 3D 占据感知可以包括但不限于稳健的数据表示、多种模态、网络架构和学习策略。
3D 标注成本高昂,而且对现实世界进行大规模 3D 标注是不切实际的。在有限的 3D 标记数据集上训练的现有网络泛化能力尚未得到广泛研究。为了摆脱对 3D 标签的依赖,自监督学习代表了通向广义 3D 占据感知的潜在途径。它从大量未标记的图像中学习占据感知。然而,当前自监督的占据感知的性能[81,35,85,28]很差。在 Occ3D-nuScene 数据集上(见表 4),自监督方法的最高准确度大幅低于强监督方法。此外,当前的自监督方法需要使用更多数据进行训练和评估。因此,增强自监督广义 3D 占据感知是未来的一个重要研究方向。
此外,当前的 3D 占据感知只能识别一组预定义的目标类别,这限制了其通用性和实用性。大语言模型(LLM)[140,141,142,143]和大视觉-语言模型(LVLM)[144,145,146,147,148]的最新进展展示了推理和视觉理解有前途的能力。事实证明,集成这些预训练的大模型可以增强感知的泛化能力[8]。 POP-3D [8] 利用强大的预训练视觉-语言模型 [148] 来训练其网络,并实现开放词汇 3D 占据感知。因此,采用 LLM 和 LVLM 对于实现广义 3D 占据感知来说是挑战也是机遇。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









