










24年4月Agile Loop和德国弗赖堡大学的论文“Training A Vision Language Model As Smartphone Assistant”。
为了解决能够执行各种用户任务的数字助理挑战,该研究重点是基于指令的移动设备控制域。 用大语言模型 (LLM) 的最新进展,本文提出一种可以在移动设备上完成各种任务的视觉-语言模型 (VLM)。 模型仅通过与用户界面(UI)交互来发挥作用。 它用来自设备屏幕的视觉输入并模仿类人交互,包括点击和滑动等手势。 输入和输出空间的这种通用性允许智体与设备上的任何应用程序进行交互。 与以前的方法不同,该模型不仅在单个屏幕图像上运行,而且在根据过去的屏幕截图序列以及相应动作创建的视觉语言句子上运行。该方法在具有挑战性的 Android in the Wild 基准测试中评估。
作者引入了一种专为 UI 环境设备控制而定制的视觉语言模型 (VLM)(GeminiTeam,2023;OpenAI,2023;Driess,2023)。 VLM 的主要功能是预测完成给定指令所需的后续操作。 其输入包括指令本身以及由屏幕截图和相关操作组成的历史记录,后者以自然语言格式化。
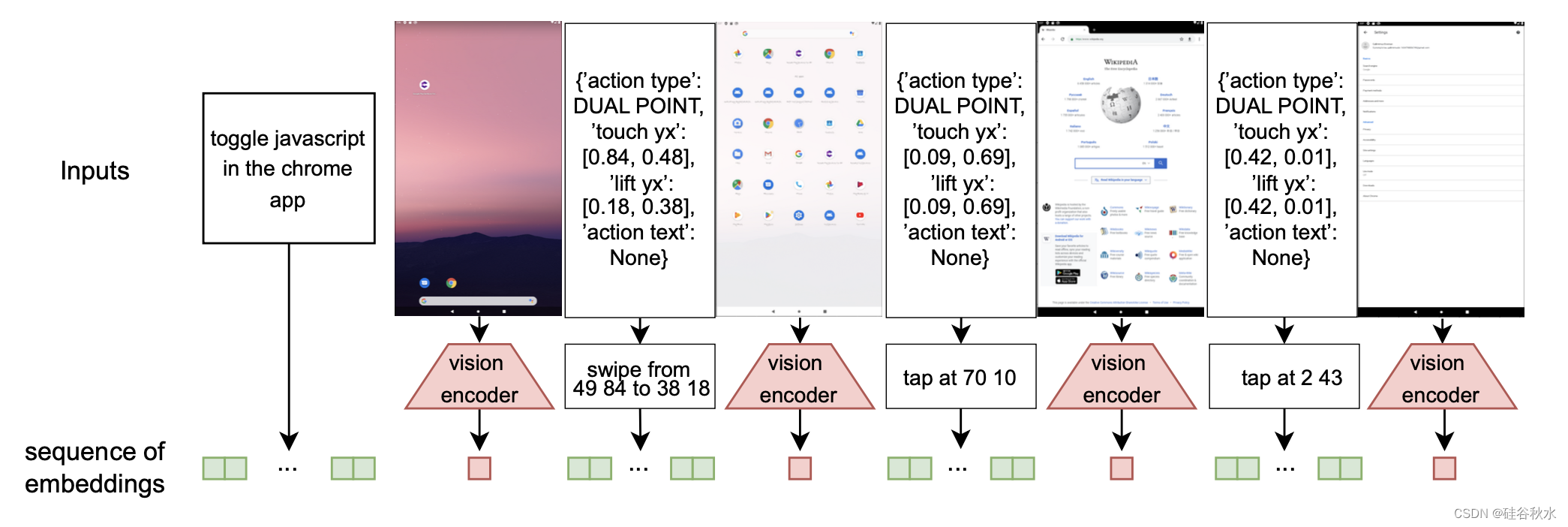
为了适应文本和视觉输入,将两种模式编码到统一的嵌入空间中。 语言模型中的tokens嵌入对文本组件进行编码,而视觉编码器将每个图像转换为低维表示。 可训练的线性投影将这些视觉嵌入与tokens嵌入的维度对齐。 随后,语言模型对这些嵌入的序列进行操作。 该序列从指令的tokens嵌入开始,然后是初始屏幕状态、第一个操作、后续屏幕状态等的嵌入。 这种方法能够将完整的轨迹表示为一系列嵌入序列,从而促进文本和视觉信息的无缝集成。
该方法的可视图解:根据指令、屏幕截图历史记录和动作历史记录为 VLM 创建一系列嵌入向量,这些向量首先被翻译为自然语言,然后被编码为tokens嵌入。 根据视觉编码器的不同,视觉嵌入向量的数量可能会有所不同。
对于视觉编码器,用预先训练的 Vision Transformer (ViT) 模型(Dosovitskiy et al., 2020),配置了 3.2 亿个参数,设计用于处理 384 × 384 大小的图像。输入分辨率的选择要确保识别精细细节,例如屏幕上出现的小文本。 使用可学习的投影矩阵将视觉编码器的输出投影到语言模型的tokens嵌入空间中。
对于语言模型,用 LLama-2-7B(Touvron,2023)。 选择仅解码器模型来自动回归文本生成的优先级,符合以文本形式预测动作的要求。 LLama-v2 模型以其在文本生成任务中的特征而闻名,这非常适合该应用程序。 使用 7B 参数版本的决定是出于计算效率的考虑,尽管更大的版本可能会产生更强大的性能。
值得注意的是,与以前的方法不同,该方法包含完整的历史状态,可以更全面地理解上下文并增强控制机制的稳健性。
Qwen-VL(Bai,2023b)的视觉编码器利用 Vision Transformer(ViT)架构,以及来自 Openclip 的 ViT-bigG(Ilharco,2021)的预训练权重。 输入图像的大小调整为 448 × 448 的分辨率,并由视觉编码器处理,将它们分割成步幅14的块,生成图像特征。 为了减少特征序列的长度,Qwen-VL 引入位置-觉察的视觉语言适配器。 该适配器使用随机初始化的单层交叉注意模块进行初始化,使用可训练的查询向量和位置编码来压缩图像特征。 然后将长度固定为 256 的压缩特征序列输入到语言模型中,该模型使用 Qwen-7B 中的预训练权重进行初始化(Bai,2023a)。 该模型总共有 96 亿个参数。
Qwen-VL 已接受过多种视觉语言任务的预训练。 特别是,这包括OCR等任务以及涉及在图像中定位目标的任务。 这两者都有助于理解屏幕的预训练任务,因为这需要理解文本以及定位按钮。
利用 AITW 基准测试提供的动作空间,其中包括四个字段:类型、触摸点、抬起点(手势动作专用)和键入的文本(打字动作专用)。 在此框架内,定义了六种不同的动作类型:双点手势、打字、返回(go back)、回主页(go home)、输入(enter)、任务完成和不可能任务。 双点手势伴随着触摸和抬起参数。 如果触摸和抬起彼此不同,则它可以表示滑动;如果它们足够相似,则可以表示轻击。 触摸和抬起参数均由触摸或抬起屏幕上的 (x, y) 坐标给出。
通过最初声明的动作类型,以及用于区分轻击和滑动的双点手势之附加规范,将这些动作翻译成自然语言。 对于点击操作,包含由空格字符分隔的触摸点坐标,并将坐标离散化为范围从 0 到 99 的 bin。例如,点击操作可能表示为“在 7 90 处点击”。 滑动操作表示为“从 3 44 滑动到 40 48”。 键入操作被描述为“ 输入文本“txt” ”,其中 txt 代表键入操作的键入文本。 返回(go back)、返回主页(go home)、输入(enter) 动作前面有“press”,表示按钮按下动作,例如“press home”。 AITW 中的动作与其自然语言表示之间的详细映射如表所示。

在 LLama+ViT 的训练过程中,冻结 LLM 的视觉编码器和tokens嵌入,将训练工作仅集中在语言模型本身和投影矩阵 Wproj 上,其用于将视觉编码器输出映射到语言模型的嵌入大小。 对于 Qwen-VL 模型,冻结除语言模型之外的网络所有部分,因为视觉和视觉投影部分已经过预训练,可以为语言模型生成有用的输入。 为了减少计算和硬件需求,对这两个模型都采用 LoRA(Hu et al., 2021)。
训练数据集包括演示,以及通过下一个token预测和屏蔽自注意训练的完整模型。 这种方法反映传统的 LLM 对特定域数据集的微调,但在损失计算期间,忽略与指令和图像嵌入相对应的预测。 因此,LLM 经过训练,可以根据提供的指令以及迄今为止的操作历史记录和屏幕截图,准确预测与正确操作相对应的token。 通过这种方式,模型可以在包括指令的完整轨迹上进行训练,就像在完整的句子上进行训练一样。
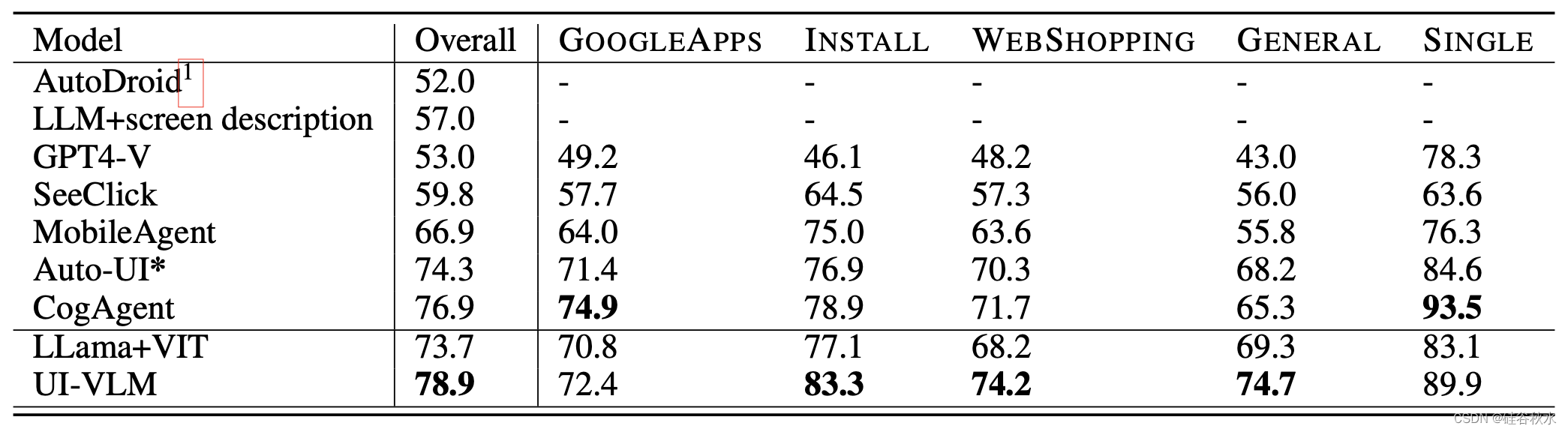
评估结果如下表所示,部分匹配得分对所有分组以及每个分组分别进行平均。 *请注意,由于正文中解释的动作表示不同,因此 Auto-UI 的结果不能直接与该方法进行比较。仍然包含这些结果以供参考。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









