










一个COE,是最灵活的万亿参数模型,能够处理每个用例,并具有小模型的性能。
动机
万亿级的大型参数模型对于一般知识具有令人难以置信的准确性,但很难适应企业特定的信息。 更糟糕的是,如果它们针对一种应用进行微调,那么在其他应用中可能会失去准确性。 较小的模型可以针对特定用例进行训练,但无法满足大型组织的广泛需求。
专家组合模型(COE)将最大模型中找到的知识广度和深度与小模型的可训练性、灵活性和性能相结合,解决这个问题,这是一个“两全其美”的解决方案。
专家组合(COE)
将任意数量的较小专家模型组合到一个大模型中
可以轻松快速地对模型进行微调
路由器模型将用户提示引导至适当的专家模型,并启用基于角色和规则的访问控制
仅查询相关专家模型进行推理,成本降低10倍
模型所有权
始终拥有自己的模型,这些模型根据自身数据进行过微调
提高实现承诺的能力
确保数据始终安全且私密
开源
利用最新的开源模型
消除对数据隐私和所有权的担忧
训练
使用私有数据快速轻松地微调模型,这对于大型单个模型来说成本过高
进行持续微调,使模型始终保持最新
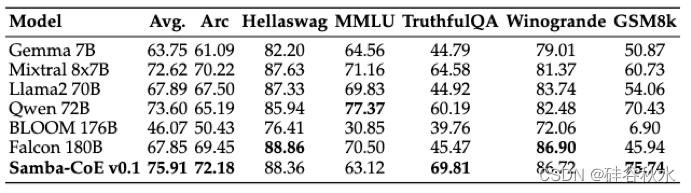
AI芯片创业公司SambaNova公司在24年1月推出 Samba-CoE-v0.1,一个Samba-1大模型 的缩小版,Samba-1 是专家组合 (CoE) 方法的最新模型。 Samba-CoE-v0.1 展示CoE 的强大功能,采用专家联系到一个模型的复杂路由技术。 用这种方法集成现有的开源模型,超越 Mixtral 8x7B 3.29%,超越 Gemma-7B 12%,超越 Llama2-70b 8%,超越 Qwen-72B 2%,超越 Falcon-180B 各种基准测试中提高 8%。 该模型还使用 GPT-4 作为裁判,对 GPT-3.5-turbo 取得了 75% 的胜率。 Samba-CoE-v0.1 实现推理的成本相当于两次调用 7B参数 LLM 模型。 CoE 方法代表一种更具可扩展性的方法,用于构建尖端LLM,其成本仅为以模块化方式构建大型语言模型 (LLM) 的一小部分(大约 1/10)。
表 1. 对从 MT-bench 和 UltraChat 采样的 123 个不同的精选查询进行 GPT4-Eval的结果

表 2. Samba-CoE-0.1 与 Mixtral 8x7B、Qwen 72B、Falcon 180B 的基准结果。
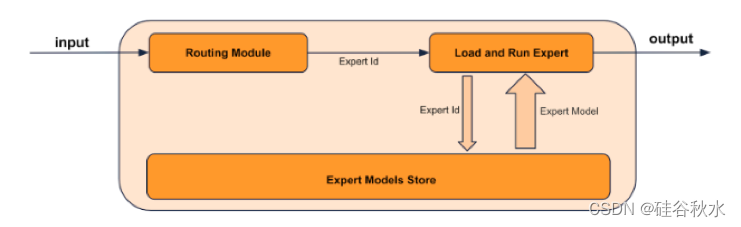
CoE 方法论
专家组合 (CoE) 方法提出了一种方法,将现有专家模型合并在一起,创建统一的交互体验。 这是通过两步方法来实现的——确定专家并构建路由器。 专家代表的模型在用户关心的任务上实现了极高的准确性。 路由器负责了解哪个专家最适合特定查询并将请求路由到该专家。 路由器应该对通用聊天机器人的提示、多轮对话以及其他特征等变化具有鲁棒性。 如果设计得当,这可以有效地创建一个由多个较小模型组成的单个大模型。 如图更形象地展示了该方法。
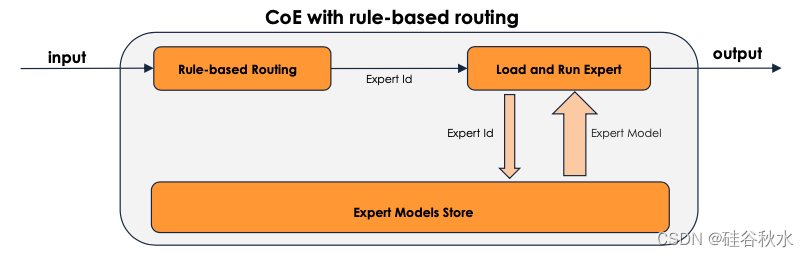
COE系统框图如下:
COE可以采用基于规则的路由,优点是:如下图所示
LLM的企业规模使用
精细访问控制/个性化LLM
多模态
其与开源模型的共生关系,带来两个优点:
加速模型的选取决策
无需昂贵的预训练,只需微调即可
还有一种智能路由的COE,采取基于经典 ML 的路由器和微调小专家,小专家自身训练快速,模块化结构可解释性强,无需回归来改进。

CoE具备以下特点:
在单个节点上以 300 个tokens/秒的吞吐量(7B 参数的专家)运行多个专家模型(高达 5T 参数)和高达 256k 序列长度的最佳 总拥有成本(TCO)。
对专家进行逐个训练,可以更快地实现价值并具备步进扩展。
接受新领域、新任务、新语言、新模态的训练,但现有能力不会变差。
提供了更高的安全性,确保模型内信息的访问控制。例如。会计专业知识只应提供给财务部门。这降低了普遍采用人工智能的风险。
Samba-CoE-v0.1 由五个专家模型和一个路由器组成。 五个专家分别是 ignos/Mistral-T5-7B-v1、cookinai/DountLM-v1、CultriX/NeuralTrix-7B-dpo、vlolet/vlolet_merged_dpo_7B 和 macadeliccc/WestLake-7B-v2-laser-truthy-dpo。 ignos/Mistral-T5-7B-v1 模型在数学任务中表现出色(GSM8K 基准),cookinai/DountLM-v1 模型在各个领域具有通用性(MMLU 基准),CultriX/NeuralTrix-7B-dpo 模型优先考虑精度(TruthfulQA 和 Hellaswag基准),而 vlolet/vlolet_merged_dpo_7B 和 macadeliccc/WestLake-7B-v2-laser-truthy-dpo 模型展示了它们在常识推理方面的专业知识,在 Arc Challenge 和 Winogrande 基准中表现出色。 该路由器利用 intfloat/e5-mistral-7b-instruct 作为文本嵌入主干,并经过训练以了解这些模型提供的各种专业知识的细微差别,并将用户查询稳健地路由给这些专家。
SambaNova系统
将 CoE 方法扩展到更多的专家,同时以较低的成本保持服务效率,需要一个能够容纳快速访问所有模型的系统。 实现这一目标的一种方法是将所有专家保留在 HBM 或 SRAM 中。 然而,在传统加速器上,这只能通过运行加速器的多个实例来创建可容纳所有专家的有效快速内存来实现。 在传统加速器中,快速存储器的大小与限制其可扩展性能力的计算单元相关。
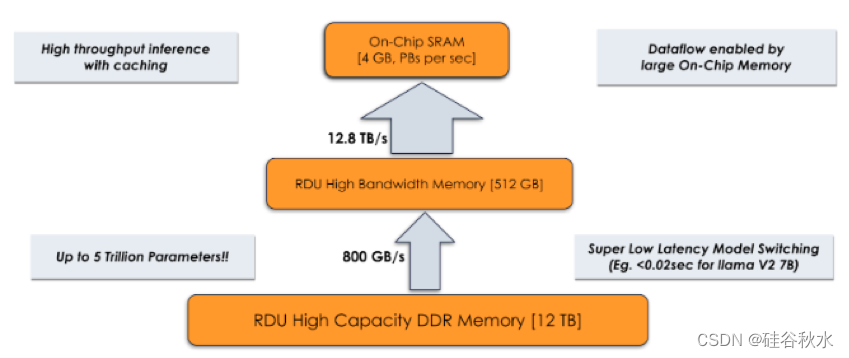
然而,SambaNova SN40L 独特的内存系统设计方法特别适合部署此类模型。 SN40L 具有三层内存架构(如图所示),可有效存储专家数据并在需要时检索它们。 专家可以使用 SRAM、HBM 或 DDR 以及它们之间的专用 BW,而不会受到任何主机干扰,从而可以高效地切换专家,而无需任何开关成本。 DDR 内存的大小允许在多个专家中托管总共 5 万亿个参数。
SN40L三层内存系统如下
最近SambaNova 最近推出的 Samba-CoE v0.3 是机器学习模型效率和有效性的重大发展。 这一最新版的专家组合(CoE)系统在OpenLLM排行榜上超越了DBRX Instruct 132B和Grok-1 314B等竞争对手,展示了其处理复杂查询的卓越能力。
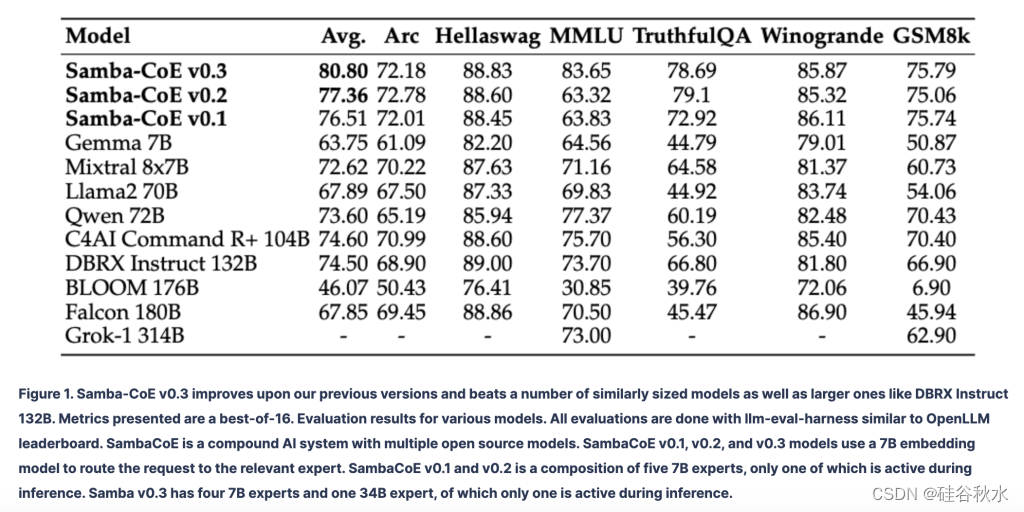
Samba-CoE v0.3 引入了一种新的、改进的路由机制,可以有效地将用户查询引导至其框架内最合适的专家系统。 这一模型基于其前身 Samba-CoE v0.1 和 v0.2 的基本方法,之前使用嵌入路由器来管理五个不同专家的输入查询。
Samba-CoE v0.3 最显着的功能之一是结合不确定性量化来提高路由器质量。 这一进步使得系统在路由器置信度较低时能够依赖强大的语言基础模型(LLM),确保即使在不确定的场景下,系统也能保持较高的准确性和可靠性。 对于需要处理各种任务而不影响输出质量的系统来说,此功能尤其重要。
Samba-CoE v0.3 由文本嵌入模型(称为 intfloat/e5-mistral-7b-instruct)提供支持,该模型在 MTEB 基准测试中展示了优秀的性能。 开发团队结合 k-NN 分类器进一步提高路由器的功能,这些分类器通过基于熵的不确定性测量技术得到了增强。 这种方法确保路由器不仅可以为给定的查询识别最合适的专家,而且可以非常准确地处理训练数据中的OOD提示和噪声。
尽管有其优点,Samba-CoE v0.3 也并非没有局限性。 该模型主要支持单轮对话,这可能会导致多轮交换期间交互效果不佳。 此外,专家数量有限且缺乏专门的编码专家可能会限制模型对某些专门任务的适用性。 此外,该系统目前仅支持一种语言,这可能会成为多语言应用的障碍。
然而,Samba-CoE v0.3 模型仍然是多个较小的专家系统集成到无缝且高效的大型模型中的先驱示例。 这种方法不仅提高了处理效率,还减少了与操作单一大规模人工智能模型相关的计算开销。
要点:
高级查询路由:Samba-CoE v0.3 引入不确定性量化的增强型路由器,确保各种查询的高精度和可靠性。
高效模型组合:该系统将多个专家系统有效集成到一个聚合单元中,提供模仿单个模型的统一解决方案。
卓越性能:该模型在 OpenLLM 排行榜上超越主要竞争对手,展示其处理复杂机器学习任务的能力。
改进地方:需要改进的地方,如对多轮对话的支持和扩展到多语言功能。
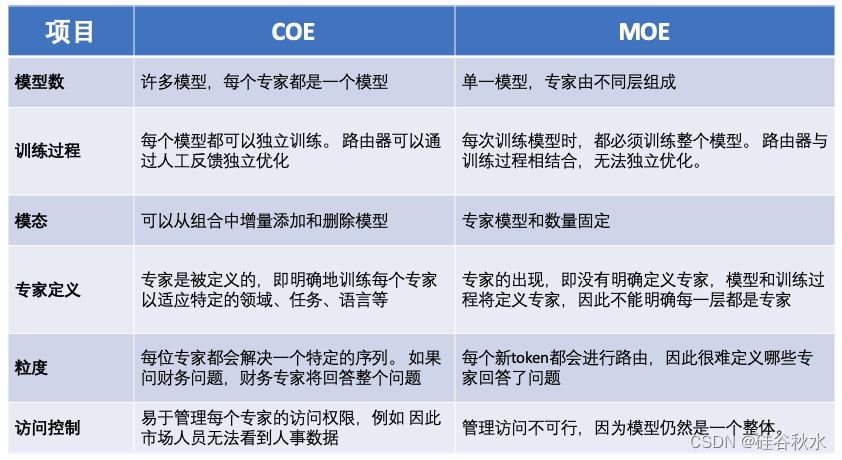
COE和MOE的比较:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









