










24年5月北航的论文“Traj-LLM: A New Exploration for Empowering Trajectory Prediction with Pre-trained Large Language Models”。
预测动态交通参与者的未来轨迹是自动驾驶的一项基石任务,在场景认知和复杂交通语义的理解方面仍然存在差距。本文提出 Traj-LLM,研究用大语言模型 (LLM) 的潜力,无需明确的提示工程,即可根据智体过去/观察的轨迹和场景语义生成未来运动。Traj-LLM 从稀疏上下文联合编码开始,将智体和场景特征剖析成 LLM 可以理解的形式。在此基础上,探索LLM强大的理解能力,捕获一系列高级场景知识和交互信息。为了模拟类人的车道聚焦认知功能并增强 Traj-LLM 的场景理解能力,引入 Mamba 模块提供支持的车道-觉察的概率学习。最后,设计多模态拉普拉斯解码器以实现场景兼容的多模态预测。
本研究探索为轨迹预测任务配备LLM固有的先进功能,以新的方式预测智体运动提供更通用和适应性更强的解决方案。
轨迹预测的问题是预测目标智体在即将到来的时间范围 tf 上的时间序列未来坐标。形式上,令 Xi 表示智体 i 在指定时间范围 {−th +1,…,0} 内的 x 和 y 位置(其中 i = 0 表示目标车辆,i = 1 : N 表示周围车辆)。假设封装了场景信息的高清(HD)地图 M的可用性。两个智体的历史轨迹和车道中心线都被构造为矢量化实体,类似于一些已建立的研究范式[46][47]。
此外,为了确保智体位置的输入特征不变性,所有向量的坐标都被归一化为以目标智体的最近位置为中心。为了捕获复杂的车道信息,由折线提取的车道中心线被分为预定义分段。
Traj-LLM 的总体架构如图所示,其中包含四个完整组件:稀疏上下文联合编码、高级交互建模、车道-觉察的概率学习和多模态拉普拉斯解码器。本文探索LLM在轨迹预测任务中的能力,而无需显式的提示工程。稀疏上下文联合编码最初将智体和场景的特征解析为LLM可以理解的形式。随后,得到的表示被输入到预训练的LLM中以解决高级交互问题。为了模仿类人车道聚焦的认知功能,进一步增强 Traj-LLM 的场景理解,基于Mamba 模块提出了车道-觉察概率学习。最后,使用多模态拉普拉斯解码器来生成可靠的预测。
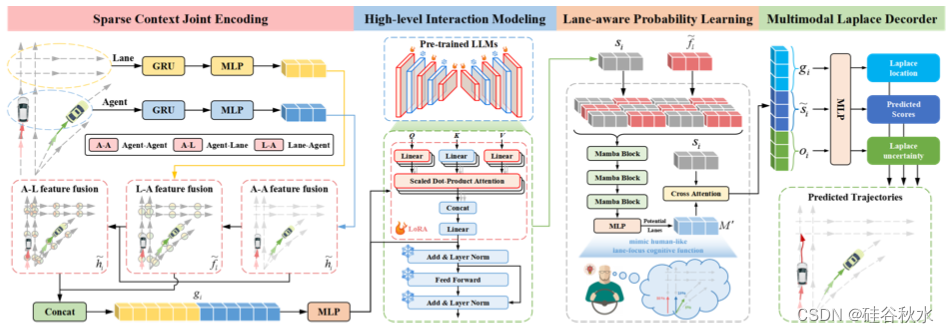
Traj-LLM 的第一步是对时空场景输入进行编码,例如智体状态和车道。对于它们中的每一个,都采用由 GRU 层和 MLP 组成的嵌入网络来提取高维特征。此后,得到的张量 hi 和 fl 被引导到融合子模块中,促进局部区域内智体状态和车道之间的复杂信息交换。此过程以类似tokens嵌入的方式执行,以与LLM的工作方式保持一致。
更具体地说,融合过程需要利用多头自注意机制(MultiSelAtt)进行智体特征融合,然后是门控线性单元[48](GLU)。此外,车道-智体和智体-车道特征的融合涉及通过具有跳连接的多头交叉注意机制(MultiCrossAtt)更新智体和车道表征。
最终,连接 hi 和 fl 来生成稀疏上下文联合编码 gi,它直观地具有与向量化实体之间的局部感受野相关的依赖关系。稀疏上下文联合编码旨在使LLM能够理解轨迹数据,从而提高LLM的高级能力。
轨迹转换遵循由场景中各种单元发出的高级约束控制模式。为了学习这些高级交互,本文探索LLM对轨迹预测任务中固有的一系列依赖关系进行建模的能力。尽管轨迹数据和自然语言文本之间有相似之处,但考虑到通用的预训练 LLM 主要是为文本数据处理量身定制的,直接利用 LLM 来处理稀疏上下文联合编码不太合适。另一种建议是对整个LLM进行全面的再训练,这一过程需要大量的计算资源,因此有些不切实际。另一个更有效的解决方案在于应用参数高效微调(PEFT)技术来微调预训练的LLM。通过调整或引入可训练参数,PEFT 展示大幅优化下游任务预训练 LLM 的出色能力 [49][50]。
本研究利用 NLP 预训练 Transformer 架构中的参数,特别关注GPT2 模型 [51],进行高级交互建模。冻结所有预训练的参数,并实施LoRA技术[52]注入新的可训练参数。LoRA应用于LLM中注意层的Query和Key。如图是预训练的LLM概览图:
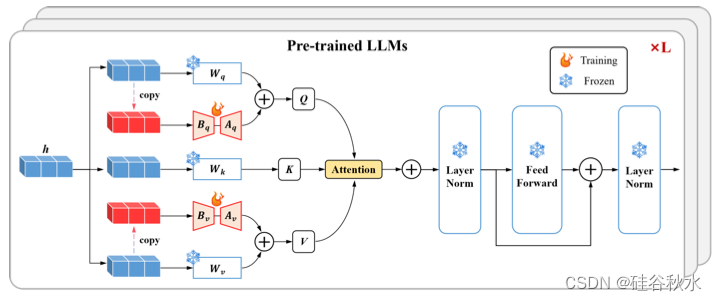
经过预训练的 LLM 处理后,输出表示 zi 通过 MLP 层进行转换以匹配 gi 的维度,从而产生最终的高级交互状态 si。
绝大多数有经验的驾驶员只关注少数潜在的车道线段,这对他们未来的运动产生显着影响。为了模仿这种类人的认知功能并进一步增强 Traj-LLM 的场景理解,采用车道-觉察的概率学习来持续估计运动状态与车道段对齐的似然,如算法总结的所示。

准确地说,在每个时间步 t ∈ {1, … , tf } 引入 Mamba 层将目标智体的运动与车道信息同步。作为选择性结构化状态空间模型(SSM),Mamba 擅长提炼和总结相关信息,而不是不加区别地遍历所有序列 [53]。它类似于人类驾驶员复杂的决策,他们明智地权衡关键信息线索(例如潜在车道),说明了他们的驾驶选择。
如图描述 Mamba 层,它由 Mamba 块、三个层归一化和逐位置前馈网络组成。
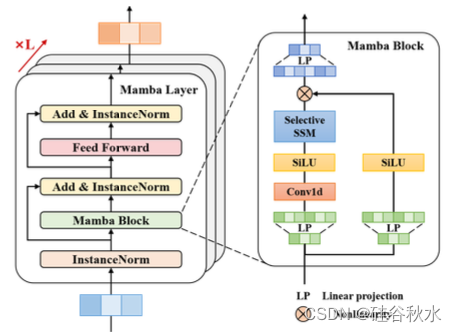
具体而言,如前面算法中描述的,Mamba 模块首先通过线性投影用膨胀系数 E 扩展输入维度,为两个并行处理分支(指定为 m 和 n)产生不同的表征。Mamba 块的核心涉及一个选择性状态空间模型(SSM),其参数基于输入进行离散化。
一个分支通过一维卷积和 SiLU 激活 [54] 处理,来捕获车道-觉察的依赖性 m‘,输出的是细化的车道-觉察特征 q;而另一个分支引入一个简单的 SiLU 激活来产生门控信号 n’,旨在过滤无关信息;最后,q 与 n’ 相乘,然后进行线性投影提供最终Mamba的输出 Q。
为增强鲁棒性,加入实例归一化(instance normalization)和残差连接得到隐状态,随后,用逐位置前馈网络来改进隐维中车道-觉察知估计的建模。还是通过实例归一化和残差连接获得车道-觉察学习向量 S,然后将其馈送到 MLP 层,从而得出第 l 个车道段在 t 时刻的预测分数。
熟练的驾驶员表现出对多个潜在车道段的敏锐关注,可促进有效的决策。为此,该方法挑选 top-c 分数 {p1, p2, …, pc} 的 top-c 车道段 {v1, v2, …, vc} 作为候选车道段,进一步连接形成 M’。车道-觉察的概率学习建模为分类问题,其中应用二值交叉熵损失来优化概率估计。
交通智体的预期移动本质上是多模态的。因此,采用混合模型框架来参数化预测分布,其中每个混合分量遵循拉普拉斯分布,符合既定方法[38]、[55]。对于每个预测实例,多模态拉普拉斯解码器将表征 ei 作为输入并输出一组轨迹。
该表征 ei 由稀疏上下文联合编码 gi、车道-觉察引导的高级交互特征 si~ 以及通过多元正态分布采样的潜向量 o 组成。特征 si~ 是通过 si 和 M’ 之间的交叉注意生成的,像熟练的驾驶员一样引导目标智体驶向候选车道线段。
为了预测混合系数,采用了 MLP 和 softmax 函数,同时用两个并排的 MLP 来生成 μi 和 bi。然后,用回归损失和分类损失来训练多模态拉普拉斯解码器,基于赢者通吃策略计算回归损失。
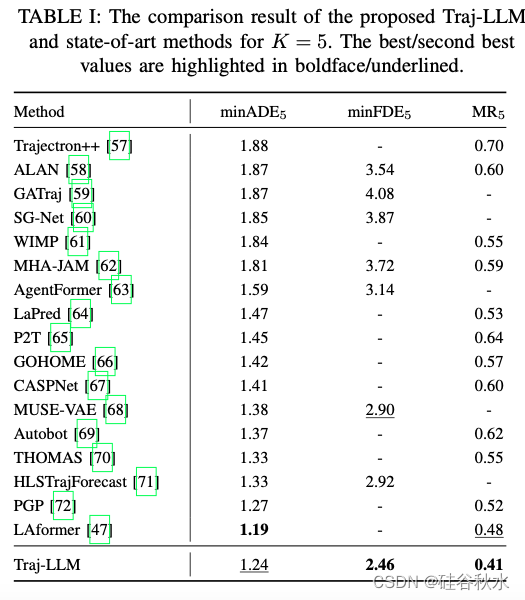
Traj-LLM 的评估是在广泛使用的基准 nuScenes 数据集 [56] 上进行的,用于轨迹预测。该数据集涵盖跨越不同城市(例如波士顿和新加坡)的 1,000 个驾驶场景,这些场景是通过车载摄像头和以 2 Hz 采样频率运行的激光雷达传感器收集的,详尽描述城市交通动态。遵循官方预测方案,Traj-LLM 采用 2 秒序列片段来预测后续 6 秒轨迹。此外,预测模态 K 设置为 5 和 10,这也与 nuScenes 数据集的规范和建议一致。
模型在 6 个 NVIDIA GeForce RTX4090 GPU 上使用 AdamW 优化器进行训练,其批量大小和初始学习率分别设置为 132 和 0.001。Traj-LLM的架构设计,首先是一层稀疏上下文联合编码模块,然后是高级交互建模模块,最后是三层的车道-觉察概率学习模块。所有特征向量的隐维度统一配置为128。
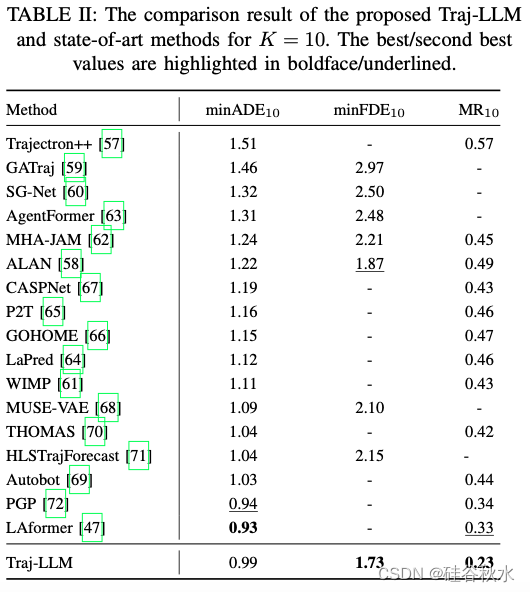
如下是K = 5和K = 10的实验结果对比:















 1750
1750











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









