










24年1月复旦大学论文“RoTBench: A Multi-Level Benchmark for Evaluating the Robustness of Large Language Models in Tool Learning”。
工具学习作为语言大模型(LLM)和物理世界之间交互的重要手段引起了广泛的兴趣。 目前的研究主要强调LLM在结构良好的环境中使用工具的能力,而忽视了它们在面对现实世界无法避免噪声的稳定性。 为了弥补这一差距,引入RoTBench,一个用于评估LLM在工具学习中稳健性的多级基准。 具体来说,建立五个外部环境,每个环境都具有不同的噪声级别(即,干净、轻微、中等、沉重和联合),提供对模型容错性跨三个关键阶段的深入分析:工具选择、参数 识别、内容填充。 涉及六个广泛使用模型的实验,强调增强LLM在工具学习方面稳健性的迫切必要性。 例如,在人工精度没有实质性变化的情况下,GPT-4的性能甚至从80.00大幅下降到58.10。 更令人惊讶的是,GPT 系列固有的噪声校正能力反而阻碍了其面对轻微噪声的适应性。 根据这些发现,提出RoTTuning,一种丰富训练环境多样性的策略,以增强LLM在工具学习方面的稳健性。 代码和数据可下载 https://github.com/Junjie-Ye/RoTBench
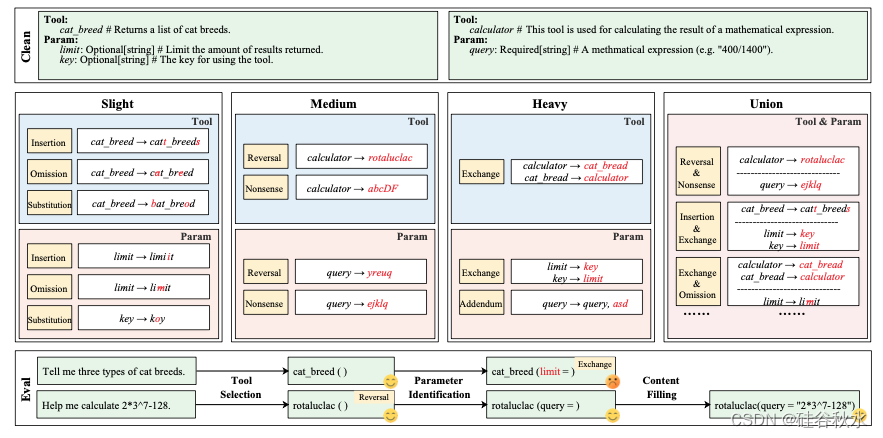
如图所示RoTBench 的框架。 RoTBench 包含五种环境(即 Clean、Slight、Medium、Heavy 和 Union),每种环境都会向工具和参数引入各种噪声,有助于在工具使用的三个阶段(即工具选择、参数识别、内容填充)。
为了彻底满足现实世界的需求并涵盖常用的工具,利用ToolEyes(Ye,2024),这是一种专为工具学习而设计的评估系统。 该系统定义了七个现实世界的应用场景,涵盖文本生成、数据理解、实时搜索、应用程序操作、个人生活、信息检索和金融交易。
在每个场景中,随机选择 15 个用户需求进行分析。 由于原始数据提供的工具信息没有标准化的调用路径,因此手动标记了这些路径以方便评估过程。 详细数据统计见下表。

工具选择标志着LLM使用工具的初始阶段。 在此过程中,LLM通过解释外部环境提供的功能描述来识别合适的工具来解决用户的查询,并随后输出这些工具的名称。 需要强调的是,工具的名称本质上是一个标签; 该工具的实际部署由其功能描述决定。
参数识别涉及识别所需的参数并根据其指定的需求输出各自的名称,然后选择适当的工具。 该过程需要选择强制参数,而可选参数则根据实际需要进行选择。 与工具选择类似,参数名称作为标识符; 然而,真正定义其含义的是参数的描述。 此外,参数的排列顺序并不重要。
内容填充构成工具使用过程的最后阶段。 一旦选择了工具及其相应的参数,LLM的任务就是分解用户提供的信息以填充这些参数的内容。 完成此步骤后,LLM正式结束整个工具使用周期,为接收工具的输出阶段并启动新的交互铺平道路。
根据实验结果,显然提高LLM在工具学习方面的稳健性势在必行。 为了解决这个问题,引入了 RoTTuning,旨在通过增加环境多样性来增强LLM在工具学习方面的稳健性。
如图所示:RoTTuning 包括四个阶段(即查询扩展、轨迹生成、环境增强和泛化训练)。
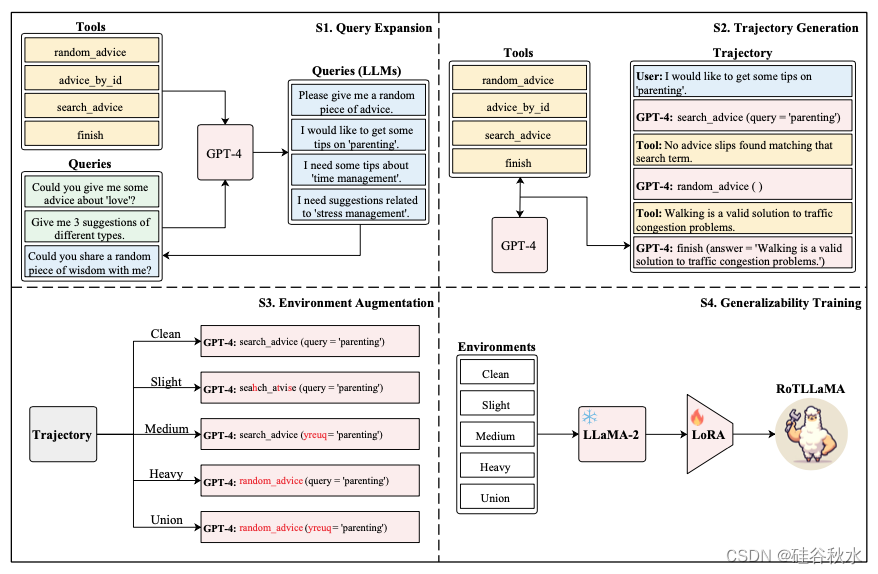
为了有效地大规模生成高质量的用户查询,采用自我指导(Wang,2023b)技术,从 105 个现有用户查询中提取。 具体来说,指示 GPT-4 在工具子集的上下文中创建七个新用户查询,以及三个现有用户查询和两个模型生成的查询。 为了确保数据集的多样性,仔细检查新数据与每个提供的示例相关的冗余,并消除 Rouge-L 值超过 0.55 的查询。 此过程总共产生 4,077 个新用户查询。
在获得高质量的用户查询后,用 GPT-4 来生成工具学习轨迹。 为了确保生成轨迹的准确性,采用 GPT-4 中专门设计的函数调用功能。 同时,通过系统提示来引导 GPT-4 生成相关的思维过程。 此外,指定 GPT-4 的工具使用最多次数限制为9。 通过将每一轮交互视为一个不同的数据点,此过程总共产生 12,247 条训练数据。
GPT-4 产生的所有轨迹最初都是在 Clean-级环境中执行的。 然而,为了增强环境的多样性,目标是创建模拟嘈杂环境的轨迹。 在嘈杂的环境中直接运行 GPT-4 可能会导致性能不佳和数据质量受损。 因此,修改在Clean-级环境中生成的轨迹以符合噪声环境的特征。 该策略可确保数据质量,同时解决在嘈杂环境中工作的挑战。 为了减轻数据耦合的潜在缺点,通过为Light-、Medium-和Heavy-级环境增加 3000 个轨迹,以及为Union-级环境增加 1500 个轨迹来引入随机性。 与Clean-级环境的数据相结合,该方法总共产生 22,747 条轨迹,代表各种环境条件。
利用生成的多样性轨迹,继续对 LLaMA-2-7B-base 进行微调。 为了增强其处理 LLM 与外部环境进行多轮交互的场景的能力,实现位置插值(Chen et al., 2023a)技术,将其上下文长度扩展到 8096。基于先前的研究表明: 与全参数微调(Zeng,2023)相比,LoRA 微调(Hu et al., 2022)实现了卓越的泛化能力,故选择 LoRA 微调方法。 5 个 epoch 的训练得出最终模型 RoTLLaMA,该模型在多个环境中表现出强大的泛化能力。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









