










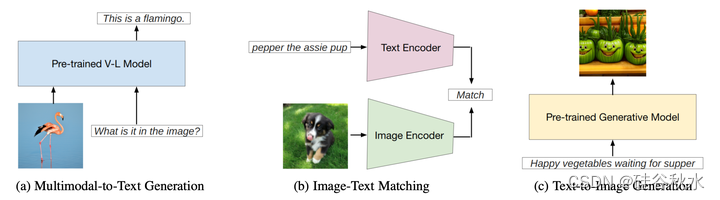
23年7月来自牛津大学牵头的几位高校学者撰写的综述论文“A Systematic Survey of Prompt Engineering on Vision-Language Foundation Models“。
提示工程是一种技术,涉及特定于任务的提示(称为prompts)来增强大型预训练模型,使模型适应新任务。提示可以手动创建为自然语言指令,也可以自动生成为自然语言指令或矢量表示。提示工程能够仅根据提示执行预测,无需更新模型参数,并且可以更轻松地在实际任务中应用大型预训练模型。过去几年,提示工程在自然语言处理中得到了很好的研究。最近,在视觉语言建模中也得到了深入研究。然而,目前缺乏对预先训练的视觉语言模型提示工程一个系统概述。本文旨在全面综述三类视觉-语言模型(VLM)的提示工程前沿研究:多模态-到-文本生成模型(如火烈鸟Flamingo)、图像-文本匹配模型(如CLIP)和文本-到-图像生成模型(如Stable Diffusion)。每种类型的模型,都总结和讨论了如简短的模型摘要、提示方法、基于提示的应用程序以及相应的责任和完整性问题。此外,还讨论视觉-语言模型、语言模型和视觉模型提示之间的共性和差异。最后总结了存在的挑战、未来方向和研究机会,促进该主题的未来研究。
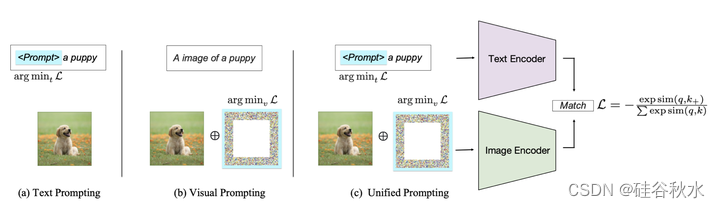
如图说明了提示方法的分类,即如下两类:硬提示,这是劳动密集型的,手动制作带有离散tokens的文本提示,以及软提示,可优化的可学习的张量,与输入嵌入连接,但由于与实际单词嵌入的不一致而缺乏可读性。

硬提示涉及手动制作的、可解释的文本标记,例如,在字幕任务的输入之前添加“照片”。硬提示可以进一步分为四个子类别:任务指令、上下文学习、基于检索的提示和思维链提示。需要注意的是,基于检索的提示通常用于选择样本进行上下文学习。
与硬提示不同,软提示的特征是连续的向量,可以用基于梯度的方法进行微调[6,41]。例如,此过程可能涉及将可学习向量与输入嵌入连接起来,然后优化,与特定数据集保持一致。新token是内部合并到模型架构中,还是简单地附加到输入,据此软提示可以进行分类。这种区别通常与两个特定策略有关:提示优化和prefix token优化。该文不涉及修改底层模型本身的提示方法,因此像P-tuning[13]和LoRa [14]这样改变模型的基本结构,不在这项研究的主要范围内。
基于匹配的VLM引入了一种新的训练范式,有助于获取联合多模态表示。该领域的著名模型,如CLIP [2],ALIGN [58],ALBEF [58]和Multi-Event CLIP [59],利用对比学习技术实现图像和文本的联合表示,其学习目标是使图像 - 文本对的表示更紧密,同时将非成对的进一步分开。
通过扩展训练数据集[2]并扩大模型参数,基于匹配的模型在大量的下游任务中表现出适应性,包括零样本基准和微调场景。
根据提示的目标,现有方法可以分为三类:提示文本编码器、提示视觉编码器或联合提示分支,如图所示。这些方法旨在提高VLM的灵活性和特定任务的性能。
文本-图像生成从自然语言描述中自动合成生动逼真的图像,引起了更多的关注。从开创性的工作DRAW [103]开始,文本-图像生成模型已经取得了许多突破。生成对抗网络(GAN)[104]随后用于设计端到端可微图像生成结构[105],还有许多工作[106,107,108]继续。此外,可变的自动编码器(VAE)[109]也适用于产生图像[110,111]。然而,这些模型是在小规模数据上训练的,缺乏泛化[112]。有提出的大规模数据集驱动的自回归方法,例如DALL-E [112]和Parti[113],并展示令人惊讶的零样本生成能力。
最近,扩散模型(DM)激发另一条线,用于文本图像生成的最先进模型[114]。扩散模型,也称为扩散概率模型[115],源自非平衡统计物理[116]和序贯蒙特卡罗[117],旨在适应任何数据分布,同时保持可处理性。去噪扩散概率模型(DDPMs)[118]首先在图像生成领域采用DM,并启发整个生成模型的社区。在推理中,DDPM构建了一个马尔可夫链,该链从有限过渡内的噪声数据生成图像,称为反向过程。在训练中,DDPM从前向过程中学习,其中噪声被添加到自然图像中并由模型估计。
结合额外的控制信息,以文本提示的形式,扩散模型中反向过程的有效性得到显着增强,控制生成结果而不是随机抽样。这种基于文本的一代巩固了其作为文本-到-图像生成领域的开创性基础地位。
如图展示了一个典型的文本图像生成框架,突出了其关键组件和功能,包括 (1) 固定或可学习的条件信息,例如硬文本提示或可学习的软提示。条件信息可以是文本形式或其他形式;(2)输入图像的编码器E;(3)生成模型,如扩散模型、自回归模型或GAN;(4)噪声注入或干扰;(5)潜空间或低分辨率图像中特征表示;(6) 用于图像解码的解码器D,或用于高保真生成的超分辨率。训练过程涉及数据集利用、损失函数和优化技术,训练模型根据文本提示生成连贯且具有视觉吸引力的图像。在推理阶段,利用训练的模型根据用户指定的提示生成图像。提示的制定起着至关重要的作用,控制着与模型通信并影响图像生成的预期结果。

下面从三个方面介绍提示的设计。
语义提示设计。提示语义技术对扩散模型中的图像生成有重大影响[119]。语言成分(如形容词、名词和专有名词)以不同但一致的方式影响图像生成。虽然描述符(简单的形容词)微妙地影响输出,但名词更有效地引入新内容。另外,使用艺术家的名字往往会产生明显偏离原作的图像,而加入照明短语可以极大地改变图像内容和情绪(mood)。因此,通过清晰的、基于名词的陈述、有效的种子和模仿艺术家风格,可以提高图像生成的质量。
通过提示实现多元化生成。除了语义方式直接手工制作单个提示外,最近的工作还尝试各种提示修整器M,重点是增强初始提示P的多样性。DiffuMask [120] 在提示修整器 M 中探索了两种策略,即基于检索的提示和带有子类别的提示,其中 P 设置为“街上汽车[子类]的照片”。具体来说,检索真实图像和字幕集[121,2],字幕作为生成合成图像的提示集。此外,根据主类从 Wiki 中选择子类。ImaginaryNet [122] 用 GPT2 [36] 作为 修整器M,具有目标物体的给定类别名 y,在前缀短语“A Photo of a”的指导下生成虚构场景的完整描述。提示用于为虚构监督目标检测任务生成多样化的逼真虚构图像。类似地,[123]用单词-到-句子的T5模型[22]作为M来生成针对特定标签空间y的详细提示,通过丰富提示的多样性最大化数据稀缺环境中合成数据的潜力。这些方法进一步从生成模型获得目标图像。
生成结果的复杂控制。由于扩散模型随机性中存在噪声注入和随机性,生成图像的产生通常不一致,因此在复杂可控生成领域出现了一些近期工作。为避免用户提供的掩码限制修改区域的可控性限制[124,125],基于提示的控制越来越受到关注。OneWord [126] 旨在解决生成具有特定主题的个性化图像问题,这些图像很难用纯文本描述。因此,一种提示方法指定一个占位符串 S∗ 来表示新概念,例如“海滩上 S∗ 的照片”及其相关的学习嵌入 v∗。类似的设计由DreamBooth完成[127]。 没有创建新单词,而是设计带有(唯一标识符,主题)对提示,其绑定T5-XXL tokenizer [22] 的少见标记作为特定主题的唯一标识符和主题的粗类名,例如“A [V] 狗”,其中 [V] 作为稀有标记标识符。在训练目标中引入扩展的类-先验保存损失,进一步保留提示中类名的表示。Custom Diffusion[128]将定制扩展到多概念场景中,其中多个个性化概念在同一生成的图像中组合,例如同一家庭照片的家庭成员。为此设计提示,每个概念 i 用唯一的修正器token Si∗,不同的稀有标记初始化并位于类别 namex 之前。多年来,仅文本提示无法满足图像处理任务的特定需求,可控的文本-到-图像生成越来越受到关注[129,130,131]。在ControlNet [133]的工作中,将各种特定于任务的输入条件(例如由图像编码器[132]编码的canning edge)与可训练的网络架构一起添加到扩散模型中。附加的任务特定条件cf添加到整个训练目标中。值得注意的是,为了提高编码器从控制图中的语义识别能力,并优化ControlNet的性能,即使没有显式提示,ControlNet的训练将一半的文本提示随机替换为空字符串。也可以在生成过程之后使用提示的编辑方法控制合成结果。为了绕过用户定义的空间固定掩码[124,125]的常见需求,Prompt-to-Prompt[134]可以仅替换单词、指定样式、更改形容词等编辑提示,这样可以编辑图像。注入交叉注意图来渗透操作,在扩散步骤期间这些图控制哪些像素关注提示文本的哪些标记。基于提示、仅修改文本提示的图像编辑方法,可提供更直观的编辑体验。
挑战和机会
多模态-到-文本生成的提示模型。除了视觉和文本模式之外,还可以纳入音频和热力等其他模式。解决这些模式之间固有的异质性至关重要,其中包括数据格式、规模和结构的变化。
图文匹配中的提示模型。尽管由匹配损耗所提示的预训练编码器已被广泛用于下游任务的适配,但对预训练编码器视觉提示的探索仍然相对未被研究。与学习文本提示无缝适应文本编码器类似,视觉提示研究是一个有趣的领域,可以解锁涌现(emergence)能力,尤其是在密集目标、目标幻觉和现代VLM的适应等困难场景中。将来,必须解决有关必不可少的特定视觉提示类型以及这些提示引入的语义信息问题。通过深入研究这些咨询,可以更深入地了解视觉提示的作用和影响,从而进一步推动该领域的发展。
文本图像生成的提示模型。在文本-到-其他模态的生成模型提示领域,特别是在文本-到-视频(T2V)和文本-到-3D(T2-3D)模型的情况下,一个重大挑战是对文本-到-图像(T2I)模型的依赖。这些模型通常具有相同的顾虑,因为其性质是T2I扩散模型的扩展。例如,T2I模型中输入控制图的不一致会导致由此生成的视频和3D目标出现错误,从而影响这些扩展场景的整体性能和可靠性。
提示方法从单模态推广到多模态。提示工程在纯视觉和纯语言模型中的应用,可以激发多模态研究的进一步研究。当与指令调优方法相结合时,纯语言模型已经实现诸如ChatGPT [50]之类的惊人应用程序。这些方法的潜力,如人类反馈的强化学习(RLHF)[180]和人工智能反馈的无害[204],可以在多模态模型中进一步探索,如最近的几项研究[203,205]。Constitutional AI是[204]中提出的一种通过自我完善来训练无害AI助手的方法,没有任何识别有害输出的人类标签。尽管已经在语言模型方面做出了一些努力[204],但如何在多模态领域实现Constitutional AI仍然是一个悬而未决的问题。
提示的负责任 AI 考虑。多模态-到-文本生成和文本-到-图像生成,都有一些关于伦理问题的研究。视觉语言模型提示工程的完整性和伦理问题需要更多的关注。一个可能的方向是在下游提示适应期间防止从预训练模型继承的偏差和后门攻击[96,206,207,208]。由于大模型通常在网络规模的数据集上进行预训练,这可能会保留有偏见的知识或敏感的隐私信息,因此通过提示工程执行的部署后程序应该能够控制潜在风险。
不同 VLM 提示之间的关系。最近的工作[216]研究多模态-到-文本和图像-到-文本以及文本-到-图像模型学习这些概念之间的关系。所研究的两类模型不能完全相互理解,同时也有一些共同的概念。同样,在未来的工作中,应该探索不同类模型提示之间的关系,特别是跨相同数据训练的不同模型构建通用提示的可行性。除了模型间关系之外,还应研究提示和模型架构之间的交互,因为大多数提示都是在基于Transformer模型上提出的。具体来说,要研究的是,模型的自注意在提示过程中如何变化[212]。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









