










19年6月来自谷歌的论文"Parameter-Efficient Transfer Learning for NLP"。
微调大预训练模型是NLP中一种有效的迁移机制。然而,在存在许多下游任务的情况下,微调方法是参数效率低下的:每个任务都需要一个全新的模型。作为替代方案,作者建议使用适配器(adapter)模块进行迁移。适配器模块产生了一个紧凑且可扩展的模型;它们只为每个任务添加几个可训练的参数,并且可以添加新任务,而无需重新访问以前的任务。原始网络的参数保持固定,从而产生高度的参数共享。为了证明适配器的有效性,将最近提出的BERT Transformer模型迁移到26个不同的文本分类任务中,包括GLUE基准。适配器可以获得接近最先进的性能,同时每个任务只添加几个参数。在GLUE上,获得了.4%以内的全微调性能,每个任务只添加3.6%的参数。相比之下,微调要训练每个任务100%的参数。
该策略是一种在几个下游任务上调整大文本模型的策略, 有三个关键特性:(i)获得良好的性能,(ii)允许按顺序对任务进行训练,也就是说,不需要同时访问所有数据集,以及(iii)只为每个任务添加少量附加参数。这些属性在云服务的上下文中特别有用,在云服务中,许多模型需要在一系列下游任务上进行训练,因此需要高度共享。
为了实现这些特性,本文提出了一个新的瓶颈适配器模块。使用适配器模块进行调优,需要向模型中添加少量新参数,这些参数在下游任务中进行训练(Rebuffi2017)。当执行深度网络的微调时,会对网络的顶层进行修改。这是必需的,因为上游和下游任务的标签空间和损失不同。适配器模块执行更通用的体系结构修改,将预训练的网络重新用于下游任务。特别是,适配器调优策略将新加层注入到原始网络中。原始网络的权重是不变的,而新的适配器层是随机初始化的。在标准微调中,新的顶层和原始权重是协同训练的。相反,在适配器调优中,原始网络的参数被冻结,因此可能被许多任务共享。
适配器模块有两个主要特性:少量参数和接近本体的初始化。与原始网络层相比,适配器模块需求较小。这意味着当添加更多任务时,总模型大小增长相对较慢。为了对自适应模型进行稳定训练,需要进行接近-本体的初始化。将适配器初始化为接近-本体的函数,当训练开始时,原始网络不受影响。在训练期间,适配器可以被激活以改变整个网络的激活分布。如果不需要,也可以忽略适配器模块;如果初始化偏离本体函数太远,模型可能无法训练。
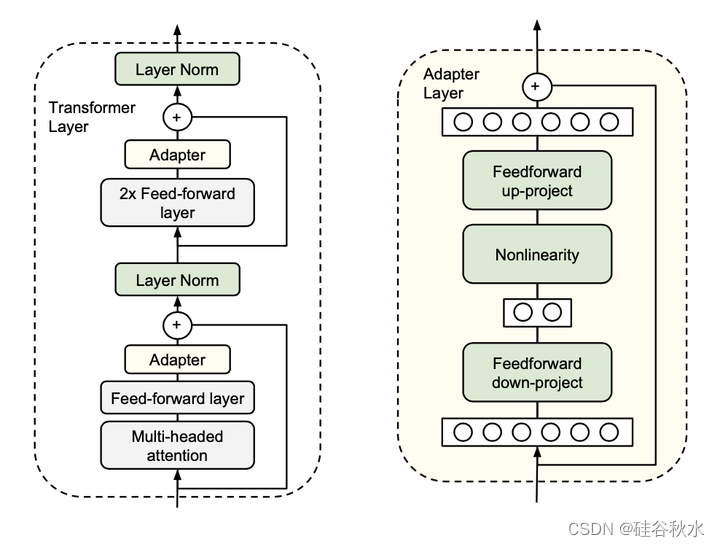
如图显示适配器体系结构,以及它在Transformer中的应用。Transformer的每一层都包含两个主要的子层:一个注意层和一个前馈层。两个层后面都紧接着一个投影,该投影将特征大小映射回输入的大小。跳连接应用于每个子层。每个子层的输出被馈送到层归一化(LN)中。在每个子层之后插入两个串行适配器。适配器总是直接应用于子层的输出,在投影回输入大小之后,但在添加跳连接之前。然后,适配器的输出直接传递到下面的层归一化中。左图:将适配器模块添加到每个Transformer层两次,即在跟随多头注意的投影之后和两个前馈层之后。右图:适配器由一个瓶颈组成,该瓶颈包含原始模型中的注意层和前馈层相关的少数参数。在适配器调试期间,在下游数据上训练绿色层,包括适配器、层规范化参数和最终分类层(图中未显示)。
用公共的、预训练的 BERT Transformer 网络作为基础模型。要使用 BERT 进行分类,遵循 Devlin(2018)中的方法。每个序列中的第一个token是一个特殊的“分类token”。在该token的嵌入上附加一个线性层来预测类标签。
训练程序也遵循 Devlin(2018)的方法。用 Adam(Kingma & Ba,2014)进行优化,其学习率在前 10% 的步骤中线性增加,然后线性衰减为零。所有运行都在 4 个 Google Cloud TPU 上进行训练,批处理大小为 32。对于每个选定的数据集和算法,根据验证集上的准确性运行超参扫描和最佳模型。对于 GLUE 任务,计算提交网站提供的测试指标。对于其他分类任务,计算测试集准确性。
将其与微调(目前大型预训练模型迁移的标准)和 BERT 成功使用的策略进行比较。对于 N 个任务,全微调需要 N× 预训练模型的参数量。目标是实现与微调相同的性能,但总参数更少,理想情况下接近 1×。
下表是使用 GLUE 评估服务器对 GLUE 测试集的结果进行评分。MRPC 和 QQP 使用 F1 分数进行评估。STS-B 使用 Spearman 相关系数进行评估。CoLA 使用 Matthew 相关系数进行评估。其他任务使用准确度进行评估。适配器调整使用总共 1.3 倍的参数(相比 9 倍)实现了与全微调(80.4)相当的总体得分(80.0)。将适配器大小固定为 64, 会导致总体得分略有下降为 79.6,同时模型略小。
















 263
263

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









