









24年5月来自清华大学的论文“Efficient and Economic Large Language Model Inference with Attention Offloading”。
基于 Transformer 的大语言模型 (LLM) 在生成任务中表现出色,但由于昂贵的计算优化加速器使用效率低下,在实际服务中带来了重大挑战。这种不匹配,源于 LLM 的自回归性质,其中生成阶段包含具有不同资源需求的运算符。具体而言,注意算子是内存密集型的,其内存访问模式与现代加速器的优势相冲突,尤其是在上下文长度增加的情况下。
为了提高 LLM 服务的效率和成本效益,引入注意卸载的概念。这种方法利用一组廉价的、内存优化的设备作为注意运算符,同时仍将高端加速器用于模型的其他部分。这种异构设置可确保每个组件都根据其特定工作负载进行定制,从而最大限度地提高整体性能和成本效率。
为了进一步验证这个理论,开发Lamina,一个包含注意卸载的 LLM 推理系统。实验结果看,与同类解决方案相比,Lamina 可以提供高 1.48 倍至 12.1 倍的吞吐量/美元。
相关工作:Orca [43] 提出了连续批处理,即以迭代粒度对传入请求进行批处理。与整个请求批处理相比,连续批处理大大减少了解码阶段提前终止造成的资源浪费。PagedAttention [18] 专注于内存管理优化,使用细粒度的 KV 缓存管理来减少内存浪费。PagedAttention 还可用于优化各种解码场景,例如集束搜索(beam search)和共享前缀。FlexGen [33] 是一个异构 LLM 推理系统,采用分层级和 token 级任务划分和调度。然而,它没有考虑到同一层内不同运算符的不同特性。 LLM 定制推理系统,例如 DeepSeed [4]、Megatron-LM [34] 和 TensorRT-LLM [27],使用了各个方面的优化,包括核优化 [9, 15]、高级调度 [2, 10, 21, 30, 41] 和高效内存管理 [10]。
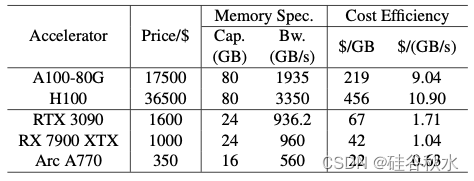
如表所示,消费级 GPU 在内存相关特性方面表现出色,与高端 GPU 相比,每美元提供的内存容量和带宽多 3 倍以上。这些替代加速器虽然在原始计算能力和可扩展性方面有所不足,但却为高效处理注意算子引入了经济的选择。此外,预计内存处理 (PIM) 设备 [5、14、16、19] 的发展将在容量更大、带宽更高的同时,展现出更大的成本优势。与传统加速器相比,PIM 提供的计算能力较低,并且缺乏从所有计算单元对整个内存的统一访问性能,但这些属性对于高效处理注意算子来说根本不是必需的。
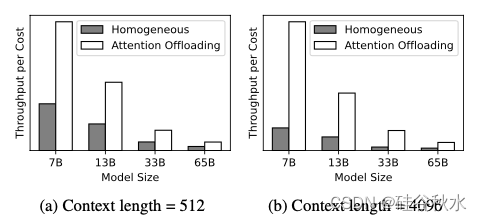
如图展示了用同构 A100 集群的传统设置与提出的架构(将每个 A100 与多个内存优化设备配对)之间吞吐量比较。可以看到,这种方法有效地将 LLM 推理的资源需求与各种硬件平台的优势相结合。
基于 transformers架构的LLM。基于 transformer 的 LLM 首先将每个输入 token 映射到词嵌入。然后,词嵌入经过一系列 transformer 块。最后,将最后一个 transformer 块的输出乘以采样矩阵,以获得下一个 token 的预测似然估计。LLM 中的每个 transformer 块包含一个前馈网络和一个自注意层。前馈网络乘以矩阵将输入嵌入投影到中间向量空间。如图所示:
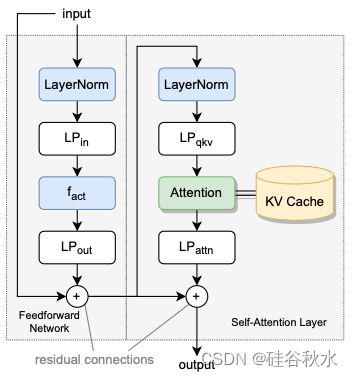
应用激活函数后,中间向量与另一个矩阵相乘,以获得变换后的嵌入。自注意层首先将嵌入投影到Q、K和V向量中。然后,将注意算子应用于序列的Q、K和V向量以获得注意计算。然后将注意与一个输出矩阵相乘,以获得注意层的输出嵌入。在实践中,多头注意通常用于增强模型质量,其中Q、K和V向量被细分为独立头。然后将头的结果连接起来乘以输出矩阵即可。
KV 缓存。回想一下,LLM 以自回归方式运行。每次迭代后,可能会缓存所有层中的 ki 和 vi 的值。因此,在以后的迭代中,可能仅在最新的 token 上运行模型,并使用缓存的V来计算注意值。这种优化大大降低LLM 推理的计算复杂度,但代价是更大的内存需求。
通过采用 KV 缓存,LLM 推理过程可以分为两个不同的阶段。预填充阶段处理整个输入提示,计算提示中每个 token 的中间嵌入,以及要生成的第一个 token。生成阶段迭代计算最后一个 token 的嵌入并生成下一个 token。
请求批处理。在机器学习训练和推理中,批处理技术被广泛用于提高 GPU 利用率 [8, 12, 35]。通过同时处理多个输入,从 GPU 内存加载的模型参数可以重用于不同的输入,从而使整个工作负载的计算更加密集。然而,在 LLM 服务的背景下,批处理的有效性受到几个因素的限制。首先,LLM 服务请求可能带有不同的上下文长度。盲目地将所有输入填充到最长长度的实现可能会导致大量的计算和内存资源浪费。已经提出更复杂的批处理技术 [18, 43] 来解决此问题。
最重要的是,随着 KV 缓存的引入,注意算子仍然受到内存带宽的瓶颈,因为每个请求都必须访问自己特定的 KV 缓存。此外,批次大小受到 GPU 内存容量的严重限制,GPU 只能容纳少量的 KV 缓存。
模型并行性。由于单个加速器的能力有限,已经开发模型并行性来将模型划分到多个加速器上。模型并行性对于管理过大而无法存储在单个加速器中的模型是必要的。两种流行的模型并行形式是流水线并行和张量并行。
流水线并行 (PP) 涉及将模型的层拆分为不同的阶段,并将每个阶段分配给单独的设备。这允许并发处理模型的不同部分,一个阶段的输出将作为下一个阶段的输入。流水线并行不会减少端到端计算时间。
张量并行 (TP) 将模型层内的各个参数张量划分到多个设备,使矩阵乘法等运算符能够由多个加速器联合计算。虽然这显著减少了计算时间,但与流水线并行相比,张量并行的可扩展性较差。这是因为每个单层加速器之间都需要进行大量的数据交换。因此,张量并行通常仅限于部署在节点内,其中加速器通过 NVLink 等高速链路连接。
为了充分利用廉价内存优化加速器的优势,注意卸载,可以有效解决 LLM 推理中两个算子的不同特征。这种方法将注意算子的处理与整体模型评估分开。这种架构划分是经过战略性设计的,旨在通过选择最适合每个运算符需求的硬件来优化性能。具体来说,用内存优化的设备来计算注意算子,并使用计算优化的设备来计算模型的其余部分。
设计的Lamina,是一个具有注意卸载功能的分布式异构 LLM 推理系统。Lamina 是用 Python 开发的,只有几行 C/C++ 代码。LLM 模型在 PyTorch [29] 中实现,其中注意算子由自定义 CUDA 内核实现。用 Ray [1] 来管理集群并促进物理资源分配和工作者放置。Lamina 支持流水线并行和模型并行。如图描述了 Lamina 的整体架构和流水线阶段。
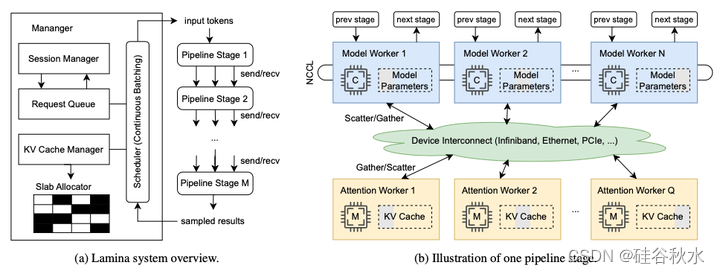
Lamina 采用两种加速设备:内存设备用于存储 KV 缓存和计算注意算子,计算设备用于存储模型参数和计算模型的其他部分。这些设备可以位于同一台物理机器内,也可以分布在一组节点上。
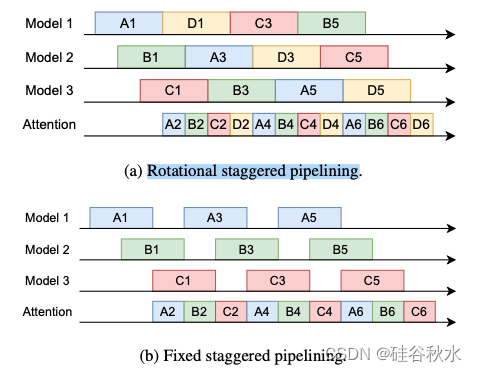
假设同时执行 n 个批次(batch)。让 tm, ta 分别表示执行一个模型切片和一个注意算子所需的时间。如图所示是旋转交错流水线(和固定流水线比较),部署 n − 1 个模型副本,每个副本在比前一个副本晚 tm /(n-1) 的时间开始其任务。所有批次共享一组通用的内存设备,最大化聚合内存带宽并提高内存利用率。对于每个批次,KV 缓存均匀地分布在这些设备上。所有内存设备联合计算单个批次的注意算子。选择内存 tm 设备的数量使 ta = tm /(n-1)。在注意算子之后,每个批次根据轮换时间表转换到下一个模型副本;也就是说,第 j 个批次的第 k 个模型切片在副本 (j+k) mod (n-1)+1 上执行。
与旋转交错流水线一样,每个模型副本以交错的执行间隔执行模型切片,并且所有批次也共享内存设备。但是,如每个副本被分配一个固定的请求批次,并在注意计算期间等待内存设备。这种固定配置交错流水线简化执行控制,并允许更好的可扩展性,但由于模型设备中出现气泡,吞吐量会降低。
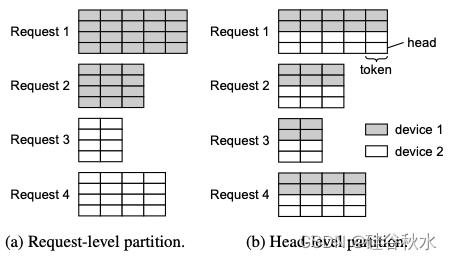
由于单个设备的能力有限,需要使用多个存储设备来联合计算注意算子。如图所示,一个阶段内的注意算子也可以通过各种方式在存储设备之间并行化。一种方法是将不同的请求分布到不同的设备上;另一种策略是将注意头(也可以独立计算)划分并分布到不同的设备上。注意头划分方法可确保工作负载平衡分配,而请求划分可能会导致负载不平衡,这是因为请求之间的序列长度不同,因此 KV 缓存大小也不同。然而,注意头划分的灵活性有限,因为它要求存储设备的数量能够被注意头的数量整除。在 Lamina 中进行请求划分,尽管工作负载分配可能不均,但它在适应各种计算场景方面提供了更大的适应性。
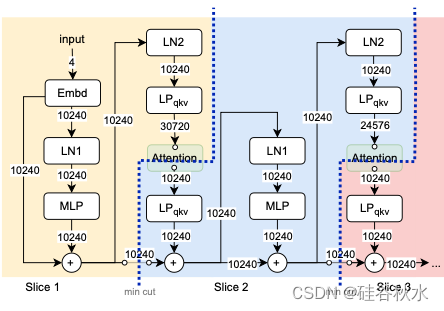
在注意卸载架构中,LLM 的不同运算符可能在不同的硬件上执行;因此,需要将模型划分为多个切片,这可以通过分割注意算子来实现。这通常需要对现有代码库进行重大修改,主要是因为所需的切割点与 LLM 固有的模块结构不一致。这种不一致使划分过程变得复杂,并增加了注意卸载系统内出现错误和不一致的风险。
这里给出一个自动的模型分割器,能够将 LLM 转换为可单独调用的切片,如图所示。给定 LLM 源代码,分割器使用符号执行生成加权计算图。每条边的权重表示在运算符之间传递的数据的大小,该大小是源自模型的形状规范。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









