









24年5月来自香港理工、百度和新加坡国立大学的论文“A Survey on RAG Meets LLMs: Towards Retrieval-Augmented Large Language Models”。
作为人工智能领域最先进的技术之一,检索增强生成 (RAG) 技术可以提供可靠且最新的外部知识,为众多任务带来极大便利。特别是在人工智能生成内容 (AIGC) 时代,RAG 中强大的检索能力能够提供额外的知识,使得检索增强生成能够辅助现有的生成式人工智能生成高质量的输出。近年来,大语言模型 (LLM) 在语言理解和生成方面展现出了革命性的能力,但同时也面临着幻觉和内部知识过时等固有局限性。鉴于 RAG 在提供最新和有用辅助信息方面的强大能力,检索增强大语言模型应运而生,它利用外部权威知识库而不是仅仅依靠模型的内部知识来增强 LLM 的生成质量。
本综述全面回顾现有的检索增强大语言模型 (RA-LLM) 研究,涵盖了三个主要技术视角:架构、训练策略和应用。作为初步知识,简要介绍 LLM 的基础和最新进展。然后,为说明 RAG 对 LLM 的实际意义,按应用领域对主流相关工作进行分类,具体详细说明每个领域的挑战以及 RA-LLM 的相应功能。最后,为了提供更深入的见解,讨论了当前的局限性以及未来研究的几个有希望的方向。
如图所示:检索增强生成 (RAG) 与大语言模型 (LLM) 相遇。当用户的查询超出范围时,例如训练数据中未见的内容或需要答案的最新信息,LLM 可能会显示较差的生成性能。借助 RAG,LLM 可以利用来自外部数据源的其他相关信息来增强文本生成能力。
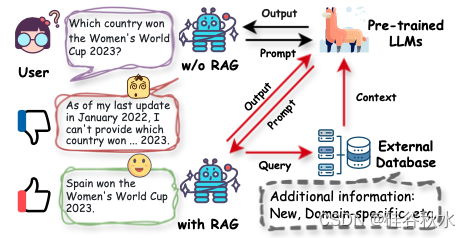
基于 LLM 的对话系统无法很好地回答超出范围的查询。相比之下,借助 RAG 从外部数据源检索相关知识并将其集成到生成过程中,对话系统成功地为用户提供了正确的答案。
LLM的背景知识在此跳过。
先说检索增强的LLM。LLM 时代的 RAG 框架一般包含检索、生成、增强三大流程,以及判断是否需要检索的机制。
检索
RAG 中的检索过程旨在根据 LLM 输入的查询提供来自外部知识源的相关信息,这些知识源可以是开源的,也可以是闭源的。关键组件检索器由多个过程组成,它们作为一个整体发挥作用,以衡量查询与数据库中文档之间的相关性,从而实现有效的信息检索。检索的具体流程还取决于是否包括检索前和检索后过程。
如图是针对特定 QA 任务基本检索增强大语言模型 (RA-LLM) 框架的说明,该框架由三个主要部分组成:检索、增强和生成。检索可能具有不同的程序和各种设计,其中可能包括检索前和检索后过程。检索到的文档在生成过程中通过增强模块进一步利用,增强模块可能根据生成模型中的集成阶段采取不同的设计。
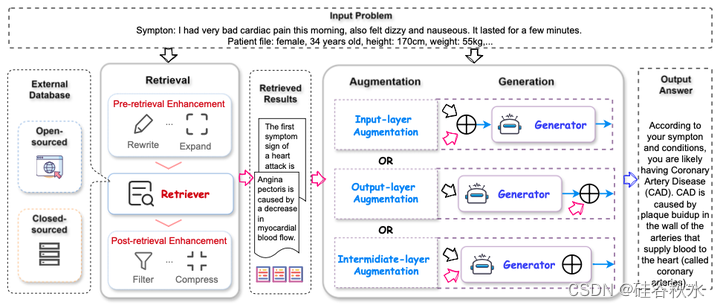
如图是RA-LLM 中检索器的说明,它可以以密集或稀疏的方式实现,每种方式都有几个关键操作。

RAG 中的检索是基于外部知识源进行的,外部知识源可以是闭源的,也可以是开源的 [92, 94]。闭源数据库通常存储知识的K-V对,这些KV对可以通过多种方式构建。K主要用于相似性匹配,可以是稀疏向量(例如 BM25)或来自检索编码的密集嵌入。V取决于特定的检索目标,在大多数情况下是原始文本 [6, 42, 49, 67, 69, 123]。例如,在早期的 RAG 中,每篇Wikipedia文章被分成不相交的 100 字块,总共 2100 万篇文档 [69]。每个文档都通过密集嵌入进行编码,并分别作为V和K保存在数据库中。V也可以存储tokens,每个token一个,就像在 kNN-LM 和 Spalm 中应用的那样 [57, 171]。数据库的来源取决于具体的应用领域和任务。Wikipedia 是先前 RAG 工作中最常用的通用检索集之一,它存储事实结构化信息,并且有多个版本,规模从十亿个 token 级别 [22, 35, 42, 57, 69, 111, 128, 160, 171] 到万亿个 token 级别 [6] 不等。领域特定数据库也用于下游任务。例如,对于代码生成任务,Zan [176] 收集公共库的 API 信息和代码文件来构建他们的 API retriever 数据库。此外,Zhou [189] 建议在他们的模型中使用经常更新新内容(新发布的库)的文档池。应用互联网搜索引擎 [89](如 Bing 和 Google)避免了搜索索引的维护,并且可以访问最新的知识 [65]。同时,它提供了比闭源数据库 [5, 65] 更广泛的知识库。互联网搜索已广泛与黑盒子 LLM 结合,并在知识增强 [65]、事实核查 [94] 和 LLM智体增强 [166] 等不同功能方面显示出有效性。与传统的 RAG 相比,互联网搜索在 RA-LLM 中更多地被用作检索者,这是因为 LLM 具有非凡的读者能力来理解搜索结果(即检索到的文档),并且 LLM 能够使用工具来处理和分析它们 [92]。现有研究 [173] 表明,利用搜索引擎(例如 InstrucGPT)对于 LLM 在零样本知识密集型任务(例如 OpenQA 和事实核查)上特别有效。
生成
生成器的设计很大程度上取决于下游任务。对于大多数文本生成任务,仅解码器和编码器-解码器是两种主要架构 [186]。商业闭源大基础模型的最新发展使黑盒子生成模型成为 RA-LLM 中的主流。存在两类生成器的研究:参数可访问(白盒子)和参数不可访问(黑盒子)。
增强
增强描述了集成检索和生成部分的技术过程,这是 RA-LLM 的重要组成部分。主要有三种增强设计,分别在生成器的输入层、输出层和中间层进行。
检索增强必要性和频率
基于 LLM 生成中的检索操作通常旨在补充知识以增强生成。尽管检索增强模型已显示出良好的前景,但它们被批评为不是通用解决方案 [70, 103],因为不加区分地用不相关的段落增强 LLM 可能会覆盖 LLM 已经拥有的潜在正确知识,并导致错误的响应 [93]。Thakur [139] 提供了一个人工标注的数据集,以帮助评估 LLM 对外部检索知识错误的鲁棒性,并观察到 LLM 对不相关检索段落的幻觉率可能是相关段落的两倍。因此,对于 RA-LLM 来说,准确回忆先验知识至关重要,同时仅在必要时有选择地合并检索到的信息,这是实现鲁棒 RA-LLM 的途径。
现有方法大多根据 LLM 的初步答案或其内部推理结果来确定检索的必要性 [96, 111]。例如,Self-RAG [5] 引入特殊 token 来评估检索的必要性并控制检索行为。其他方法设计迭代提示来决定生成过程中是否需要额外信息,从而需要调用 LLM 的检索或其他操作 [154, 166]。在传统 RAG 中,检索必要性判断也被探索并提出通过直观的方法来解决,比如评估生成模型生成的 logit 置信度 [43, 51, 54]。这样的解决方案也适用于 RA-LLM,例如,FLARE [52] 在 logit 低于特定阈值时动态触发 RAG。更灵活的是,Tan [9] 提出一种基于 RA-LLM 的检索必要性判断方法。 [138] 介绍一种协作方法 SlimPLM,它使用精简智体模型检测 LLM 中缺失的知识,该模型的作用是生成“启发式答案”。启发式答案用于评估检索的必要性,并在必要时通过应用于查询重写来促进检索过程。
在很少考虑检索必要性的传统 RAG 中,检索频率(也称为检索步幅)是决定在生成中使用检索程度的重要设计方面,从而极大地影响 RAG 模型的整体性能 [111]。检索频率控制对检索结果的依赖程度,从而影响模型的效率和有效性。当不考虑检索的必要性时,检索频率通常是预定义和固定的,有三种常见设置:一次性、每 n 个token一次和每个token一次。一次性检索仅调用一次检索函数,并尝试在这一次性操作中找到所有所需信息。一次性检索通常在生成过程开始时进行,然后将所有检索到的文档与原始输入一起提供给生成模型,如 REALM [42] 中所述。一次性检索更适合于 LLM [52] 显然需要外部数据库中的信息的情况。然而,对于需要长格式输出的语言任务(如开放域摘要),在生成过程中考虑输出中tokens之间的依赖关系更为重要。在这些情况下,预先检索到的文档(通过一次性检索)可能不足以支持整个输出序列的生成,这就需要在生成过程中进行检索操作。为此,In-Context RALM [111] 和 RETRO [6] 在生成过程中应用每 n 个tokens的检索,以实现更好的增强。相比之下,kNN-LM [57] 采用了更频繁的检索策略,在生成过程中检索每个 token 的预测信息。总体而言,应用不同的检索频率会影响整个 RAG 方法的有效性和效率。例如,更频繁的检索会带来更好的性能,但也会增加计算成本 [111]。选择检索频率几乎是在计算成本和性能之间的权衡。
再说RAG-LLMs的训练。
根据是否训练,现有的 RAG 方法可分为两大类:无需训练的方法和基于训练的方法。无需训练的方法通常在推理时直接利用检索到的知识,而无需通过将检索到的文本插入提示中来引入额外的训练,这在计算上是高效的。然而,一个潜在的挑战是检索器和生成器组件并未针对下游任务进行专门优化,这很容易导致检索到的知识利用率不理想。为了充分利用外部知识,提出了大量方法来微调检索器和生成器,从而指导大语言模型有效地适应和整合检索到的信息 [121、122、124、128、145、191]。
如图所示是对检索增强大语言模型 (RA-LLM) 中不同训练方法的说明。现有的 RA-LLM 方法可分为两类:无需训练的方法通常将检索到的知识整合到提示中,来直接利用推理期间检索到的信息,而基于训练的方法则微调检索和生成器,增强生成性能。根据训练策略,基于训练的方法可进一步分为三类:独立训练,其中检索和生成器组件是独立训练的;序贯训练,按顺序进行训练它们;以及联合训练,其中它们被联合训练。
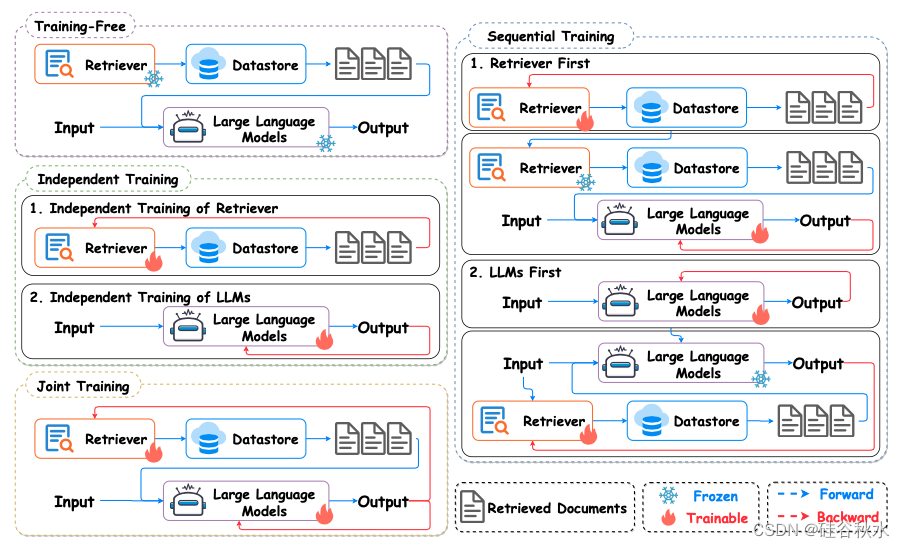
无需训练
由于参数数量巨大,LLM 已经展现出人类水平的智能,并在各种下游任务中取得了良好的预测性能。然而,频繁执行微调和更新存储在模型参数中的知识 [69] 极具挑战性,因为这需要大量时间和计算资源。最近,许多研究建议通过检索机制增强 LLM,使其能够从外部来源动态获取新知识,无需额外的训练过程(即无训练)[49, 52, 58],而不是仅仅依赖于模型参数中编码的隐性知识。这些方法已显示出各种知识密集型任务的性能显著提升,例如开放域问答 [69] 和文档摘要 [134]。根据 LLM 利用检索到的信息的不同方式,将这些无需训练的方法分为两类:1)基于提示工程的方法,将检索到的知识直接集成到原始提示中;2)检索引导的 Token 生成方法,检索信息来标定 token 生成过程。
基于训练
独立训练是指将检索器和 LLM 作为两个完全独立的过程进行训练,在训练过程中检索器和 LLM 之间没有任何交互 [56, 64, 189]。与无需训练的方法相比,训练 LLM 利用检索到的知识或检索器来弥合信息检索和语言生成之间的差距,可以有效提高基于 RAG 的模型的性能。对于 LLM 的训练,负对数似然损失是最具代表性的训练目标 [109, 140],旨在指导 LLM 根据给定的输入生成期望的输出。
关于检索器,可以分为两类:1)稀疏检索器 [114, 119],2)密集检索器 [56, 64, 189]。稀疏检索器通常利用稀疏特征(例如词频)来表示文档,并根据特定任务的度量 [72, 114, 119](例如 TF-IDF 和 BM25)计算相关性得分。对于密集检索器,深度神经网络用于将查询和文档编码为密集表示,然后通常用内积来计算相关性得分并检索相关的外部知识。例如,DPR [56] 采用两个独立的 BERT [24] 网络分别对查询和段落进行编码,并利用对比学习来训练这些模型。CoG [64] 建议训练前缀编码器和短语编码器进行检索,并将文本生成重新表述为从现有源文本集合中进行多次复制-粘贴的操作。
序贯训练
独立训练是在生成过程中利用外部知识的一种有效方法,因为检索器和生成器可以离线训练,并且可以使用任何现成的模型,从而避免额外的训练成本。为了更好地增强检索器和生成器之间的协同作用,已经提出了几种方法来序贯训练检索器和 LLM。在这些序贯训练方法中,该过程通常从检索器或生成器的独立预训练开始,然后固定预训练模块,而另一个模块进行训练。请注意,各种现有模型(例如 BERT [24, 59, 117]、CLIP [107]、T5 [110])可以直接用作固定检索器和生成器,从而绕过第一个相关过程。与独立训练相比,序贯训练涉及检索器和生成器的协调训练,其中可训练模块受益于固定模块的协助。根据检索器和生成器之间的训练顺序,序贯训练可以分为两类:1)检索器优先[5, 121, 122, 145, 191];2)LLM 优先[124, 128, 149]。
联合训练
联合训练方法 [17, 46, 55, 74, 159, 188] 采用端到端范式同时优化检索器和生成器。联合训练方法不是按顺序训练每个模块,而是有效增强检索器定位外部知识进行生成的能力以及生成器有效利用检索信息的能力。例如,RAG [69] 通过最小化负对数似然来联合训练检索器和生成器。REALM [42] 采用与 RAG [69] 类似的训练范式,并使用最大内积搜索 (MIPS) [15, 27, 113, 125] 技术来查找最相关的文档。要使用 MIPS,首先嵌入所有外部文档,然后为每个嵌入生成一个搜索索引。一种异步索引更新策略[42、47、50、133],每几百个训练步刷新一次索引,以避免重新索引所有文档的时间消耗。
应用
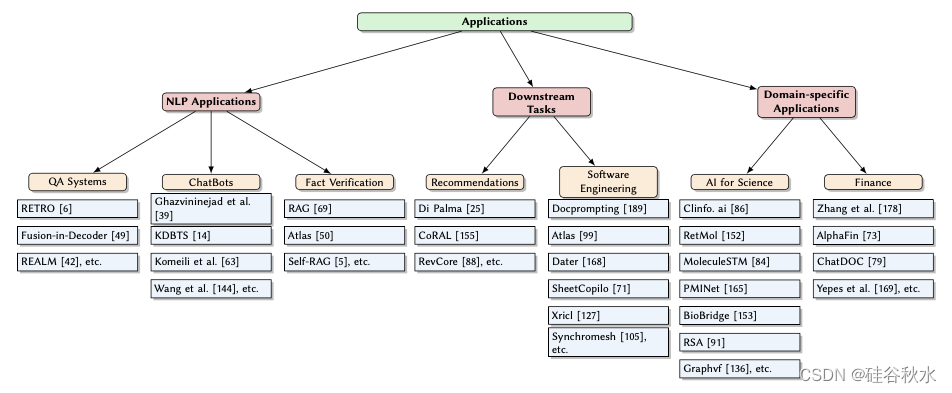
如图所示按 NLP 应用、下游任务和特定域应用分类的 RA-LLM 应用概览。具体而言,NLP 应用包括 QA 系统、聊天机器人和事实验证;下游任务包括推荐和软件工程;特定域应用包括科学和金融AI。
未来方向
值得信赖的 RA-LLM
多语言RA-LLM
多模态RA-LLM
外部知识质量


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









