









23年12月的论文“Interactive Planning Using Large Language Models for Partially Observable Robotics Tasks“, 来自伯克利分校和MERL。
设计用于执行开放词汇任务的机器人智体一直是机器人和人工智能领域的长期目标。最近,大语言模型(LLM)在创建用于执行开放词汇任务的机器人智体方面取得了深刻的成果。然而,在不确定性的情况下,这些任务规划是具有挑战性的,因为它需要“思维链”推理,聚合来自环境的信息,更新状态估计,并根据更新的状态估计生成行动。本文提出一种使用LLM部分可观测任务的交互式规划技术。该方法LLM用于机器人从环境中收集缺失的信息,并在引导机器人执行所需操作的同时,根据收集的观测结果推断潜在问题的状态。通过self-instruct使用一个微调的Llama 2模型,并将其性能与GPT-4等预训练的LLM进行比较。
考虑图中所示的任务T2,其中机器人需要了解如何收集信息来识别空杯子,然后将其扔进垃圾箱。杯子的内容中存在不确定性。对于任务T1,机器人被要求将左侧的杯子扔进垃圾箱。LLM智体可以生成机器人执行任务的可行动作序列。当被要求扔空杯子时,智体无法根据当前信息判断哪个杯子是空的。它需要与杯子互动,并用来自观察的反馈(例如,力传感器读数)来识别空杯子。
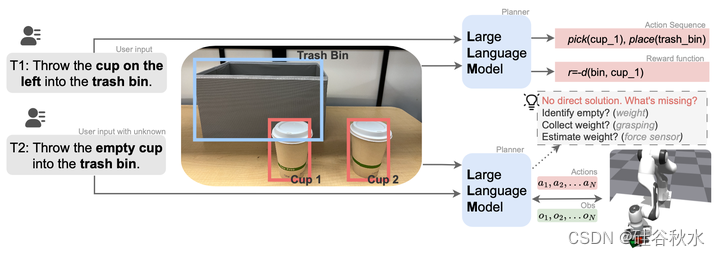
与信息完整的任务不同,设计一系列技能或合适的奖励函数来解决这项任务将是一项挑战。这个问题可以公式化为部分可观测马尔可夫决策过程(POMDP)[18]。然而,解决POMDP可能在计算上很棘手。它需要在问题的置信(belief)状态下进行推理,并且不能与问题的维度很好适应。先前关于将LLM用于机器人任务的工作已经证明了LLM具有良好的推理能力,并将推理映射到机器人动作[1,15,9]。受此启发,可以利用LLM的推理和“思维链”(CoT)能力,与环境交互的同时解决部分可观察的任务。当前LLM具有挑战性的是,需要了解来自不同模态的真实机器人观测结果,并将其用于任务规划。
先前在机器人学中使用LLM的大多数工作都集中在逐步理解场景和任务上,充分利用当前可用的模态来推断最佳动作和/或奖励[1,15,52,9]。本文工作专注于部分可观测性的情况下执行交互式规划。这需要规划模块收集来自环境的信息,推理系统的正确状态,并根据机器人收集的传感器观测结果更新状态估计。此外,作者还试图了解,与GPT-4等预训练LLM相比,微调的较小规模模型,像Llama2-7B[42],其性能如何。由于实际原因,较小的模型通常是可取的,但蒸馏出如GPT-4模型的推理能力,对本文讨论的复杂机器人任务,可能具有挑战性。为此,作者提出了一个遵循self-instruct[47]方案的指令数据生成流水线,这样才能了解较小模型的局限性以及克服这些局限性的潜在方法。
对于长期任务,用一组预训练好的参数化技能作为动作空间,是一种常见的选择。本文使用了一组参数化技能,如{pick,place,reach,reset}。所有这些技能都可以使用机器人观测来执行,因此在机器人技能执行过程中不考虑部分可观察性(partial observability)。值得注意的是,在技能执行过程中不考虑连续的感知反馈——然而,这可以通过使用强化学习(RL)训练技能来实现。
采用LLM在交互式规划过程中可以发挥多方面的作用。
用于状态抽象的LLM:给定环境描述和传感器观测,LLM需要分析可用信息并抽象足够的统计信息(或适当的状态)来解决任务。此外,它还需要根据目前的观察结果对不确定的因素进行推理。当有历史信息提示时,它需要根据观察结果更新其信念。
LLM作为策略:考虑到观测和动作空间,LLM需要规划一些收集环境信息的动作,减轻不确定性并更新智体的信念状态。基于LLM的策略也有望生成最优规划,在任务描述的基础上以最少的步骤最大化奖励。此外,由于对机器人使用开环参数化技能,因此LLM也用于在这些技能执行失败时向机器人提供反馈。这种反馈需要以机器人执行的方式提供。
在任务执行过程中使用LLM来推理这些问题。值得注意的是,POMDP环境中的动作是以新观测数据和更新的信念为条件的。当用LLM作为不确定性任务的闭环策略时,还有一些额外的挑战。为了更新任务的置信状态,LLM必须了解来自不同模态(姿态检测、力传感器等)的机器人观测结果。这些数据格式可能是LLM模型的新数据格式,因此必须正确地包含在LLM的提示模板中。此外,机器人可用的技能由连续的位置和方向坐标参数化,这在执行机器人任务时可能很难推理。类似地,语言模型的输出需要由机器人执行;应该把响应写在下游控制器能够理解的模板中。
交互式规划框架(LLM-POP)如图所示。其中一个示例显示了该框架在解决任务“拾取较重的块”过程中的工作方式。LLM规划器向机器人输出可执行的动作序列。机器人执行动作,观察描述-动作对添加到历史缓冲区中。LLM评估器分析历史信息,并将更新后的信息输出到规划器生成新规划。
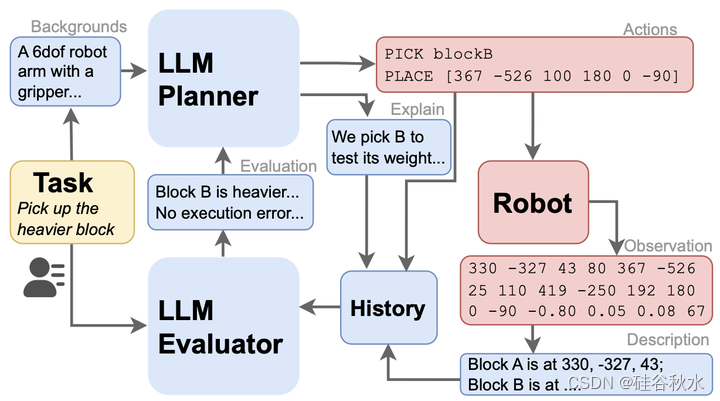
正如所介绍的,框架中基于语言的策略在规划循环中有多个任务要做。在每一步,语言模型的输入都包含来自用户的任务描述、来自机器人的当前观测以及来自先前步骤的历史动作和观察序列。模型输出包括可执行的动作序列和相应的文本解释。机器人将执行策略提供的操作,并返回观察结果到LLM下一轮的查询。语言模型必须完成推理任务,并以设计的格式输出策略。任务描述是规划过程中用户提供的唯一输入。
除了LLM规划器,还用类似的提示结构设计LLM评估器。评估器在执行过去的操作后获取背景信息、任务描述和历史观察结果。评估任务执行状态,并将其附加到下一轮提示中。评估器将明确要求LLM完成“状态抽象”(分析缺失的信息)、策略中的“置信更新”(分析历史观察中的信息)和“纠正执行错误”(从历史中识别失败)。尽管可以将所有需求放入LLM规划器中,要求其进行所有分析并在响应中做出规划决策,但将其分解为两个步骤可以提高推理结果。
使用像GPT-4这样强大的LLM作为交互式规划器,其依赖思维链推理和上下文学习能力。因此,LLM的提示(单轮LLM查询的输入)需要仔细设计,确保它可以推广到机器人任务,并避免响应中出现幻觉(以错误的格式生成动作或机器人无法执行)。
如图所示:左边部分是GPT规划器和评估器的提示模板,任务描述取自用户输入,其他描述根据环境和机器人预定义,输出规则将针对评估者进行调整;右边部分是微调LLM作为交互式规划器的训练程序。在推理过程中,问题来自预定义的CoT问题集,输入来自机器人观测。
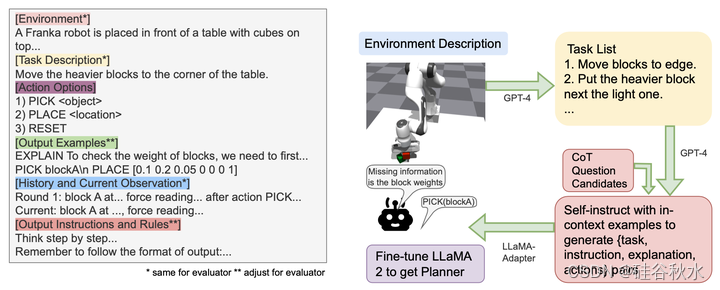
如上图左所示,规划器的提示模板由以下部分组成:
环境描述、动作选项、输出规则:有助于理解任务设置的背景信息;该信息由用户预先设置,并且整个不同任务的规划中是恒定不变。
任务描述:描述用户任务的文本;假设前两部分应该为LLM提供足够的信息,了解什么是缺失的信息,以及什么是可以收集信息的动作。
输出示例:规划的上下文示例。
当前观测和历史信息:当前观测和历史信息的文本格式描述。如果观察是姿态和力(force),采用带解释的向量。
输出中的解释以及动作序列将包含在历史信息中。这有助于LLM理解其过去执行的动作,避免再次对此进行推理。请注意,LLM规划器需要根据自己对环境、任务和动作空间描述的理解来指定动作中的参数。对于操作任务,这包括目标姿态的位置和方向。
微调语言模型,而不是直接查询GPT-4,不仅可以实现离线部署,而且在交互式规划环境中具有明显优势。一个突出的原因是在数据中加入了多模态。系统不仅仅依靠文本描述,还利用了机器人的观测结果。虽然这些观测结果理论上可以转换为文本形式,但它们构成了一种新数据类型,GPT-4尚未进行过训练,从而导致零样本的可推广性有限。例如,在使用GPT-4的实验中,如果机器人观测中的姿态和动作参数处于不同的参考系中,LLM将难以转换。第二个原因是输入中需要大长度的上下文。对GPT的直接查询需要在每个实例中包含环境设置和生成约束,这是低效且成本高。较小微调的预训练LLM模型,其困难主要来自两个方面:1)缺乏复杂任务的数据。野外的大多数机器人数据[44,3,10]都不涉及部分可观测任务,力-扭矩(force-torque)传感器数据通常不包括在内,因为其含噪,并且在不同的机器人上有变化。2) 较小的模型在推理任务方面更差,CoT与较大的模型联系在一起[48]。
为了获得所需的数据,以便在部分观测下对交互式规划的规划器进行模型微调,遵循上面图右所示的程序,使用self-instruction[47]生成指令数据集并对LLaMA2-7B[41]模型进行微调。整个流水线包括:
任务生成:向GPT-4提供环境、机器人、潜在不确定性、动作选项和示例任务的描述,生成一些可行的任务。鼓励GPT-4在任务集的难度上多样化。
指令生成:生成的任务用于生成指令-响应对,遵循self-instruction范式。指令包括任务描述和问题,输入包括机器人的观测结果。该模型生成的输出包括与GPT-4规划器一样的口头解释和动作。添加格式指令以保证“响应”格式。
CoT问题设计:对于较小的模型来说,在一个查询中完成状态抽象、置信更新和动作规划是很困难的。因此,创建CoT问题[12],询问是否存在缺失信息,如何收集信息,以及如何用填充信息解决任务。规划器根据响应的二值选项选择问题来问。
整合收集的机器人观测结果:对于预训练的动作,收集机器人完成动作的成功轨迹,并将其用作指令生成(Instruction Generation)过程中的上下文参考示例。
微调:对于微调过程,采用LLaMA适配器[11]。这种方法能够利用专门策划的数据集,并根据独特的任务生成和交互式规划场景对其进行微调,从而提高模型的性能。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









