










23年8月来自中山大学、中科院自动化所和字节公司的论文“EVE: Efficient Vision-Language Pre-training with Masked Prediction and Modality-Aware MoE“。
构建可扩展的视觉-语言模型以从多样化的多模态数据中学习,仍然是一个悬而未决的挑战。本文介绍了一个高效视觉-语言的基础模型,即EVE,一个统一的多模态Transformer,仅通过一个统一任务进行预训练。具体而言,EVE在与模态-觉察稀疏混合专家(MoE)模块集成的共享Transformer网络中,对视觉和语言进行编码,该模块选择性切换到不同的专家捕获模态特定信息。为了统一视觉和语言的预训练任务,EVE对图像-文本对进行掩码信号建模,在给定可见信号的情况下重建掩码信号,即图像像素和文本token。与用图像-文本对比度和图像-文本匹配损失进行预训练的模型相比,这个简单而有效的预训练目标将训练加速了3.5倍。由于统一架构和预训练任务的结合,EVE易于扩展,以更少的资源和更快的训练速度实现了更好的下游性能。尽管EVE很简单,但它在各种视觉语言下游任务上都取得了最先进的性能,包括视觉问答、视觉推理和图像文本检索。
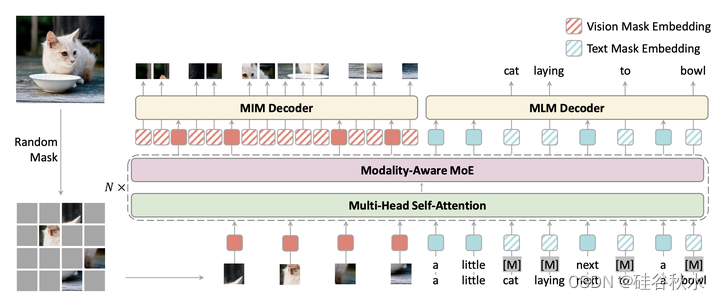
EVE采用共享注意机制和模态觉察MOE的统一多模态 Transformer 作为主干网络,该网络能够对不同模态进行编码。如图是EVE和屏蔽信号建模概述。为EVE使用具有共享注意和模态-觉察MoE的统一架构,并为预训练用单个统一的屏蔽信号建模。对图像和文本都采用了随机掩码。掩码图像和完整文本用于掩码图像建模,反之亦然。
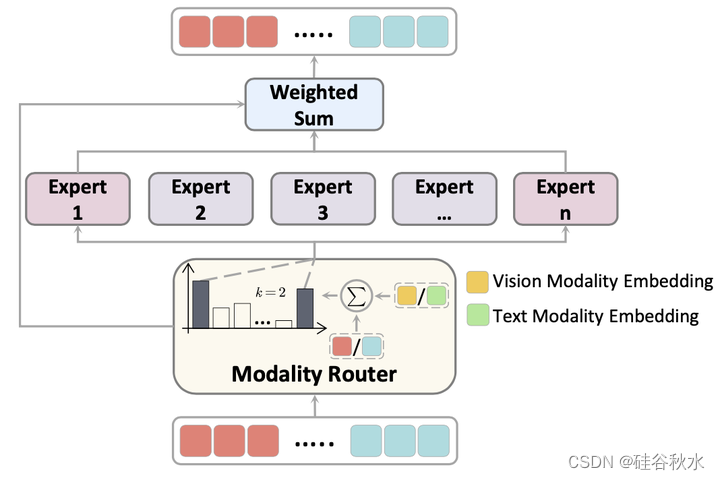
多模态学习与单模态学习有很大不同,因为模态之间的差异不容忽视。对所有模态使用相同的前馈网络可能导致模态的不适当融合,从而导致性能下降。相反,在所有层中使用模态特定的MoE可能不会有利于不同模态的对齐。因此,提出的模态-觉察的专家混合(MoE),如图所示,在通用MoE之上结合了模态路由技术,捕获模态特定信息,同时选择性地切换到不同的专家进行融合。
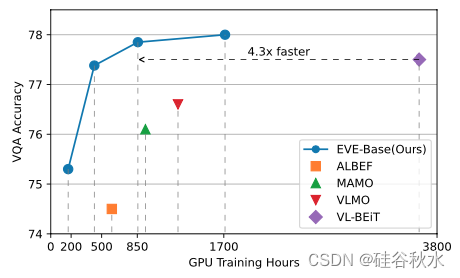
EVE 可以大大提高预训练速度,如图 所示。它降低了对大量计算资源的需求,同时易于扩展。EVE 体现了在各种视觉语言下游任务上的有效性,包括视觉问答、视觉推理和图像文本检索。EVE 在图像文本检索和视觉语言理解 (VQA 和 NLVR2) 任务上实现了最先进的性能。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









