










23年12月清华大学论文“CogAgent: A Visual Language Model for GUI Agents”。
人们在图形用户界面(GUI),例如计算机或智能手机屏幕,在数字设备上花费了大量时间。ChatGPT等大语言模型可以帮助人们完成写电子邮件等任务,但很难理解GUI并与之交互,从而限制了它们提高自动化水平的潜力。本文介绍CogAgent,一个180亿参数的可视化语言模型(VLM),专门用于GUI理解和导航。通过利用低分辨率和高分辨率图像编码器,CogAgent支持1120×1120分辨率的输入,使其能够识别微小的页面元素和文本。作为一个通用的视觉语言模型,CogAgent在五个文本丰富的VQA基准的和四个通用VQA基准上达到了最先进的水平,包括VQAv2、OK-VQA、text VQA、ST-VQA、ChartQA、infoVQA、DocVQA、MM Vet和POPE。
模型和代码下载可在 https://github.com/THUDM/CogVLM
基于VLM的智体直接感知视觉GUI信号,而不是完全依赖于HTML[28]或OCR结果[31]等文本输入。由于GUI是为人类用户设计的,只要VLM与人类水平的视觉理解相匹配,基于VLM的智体就可以像人类一样有效地执行。此外,VLM还能够掌握通常大多数人类用户无法掌握的快速阅读和编程等技能,从而扩展了基于VLM智体的潜力。先前的一些研究仅将视觉特征作为特定场景中的辅助因素。例如WebShop[39],其主要将视觉特征用于目标识别目的。随着VLM的快速发展,仅仅依靠视觉输入能否自然而然地在GUI上实现通用性?
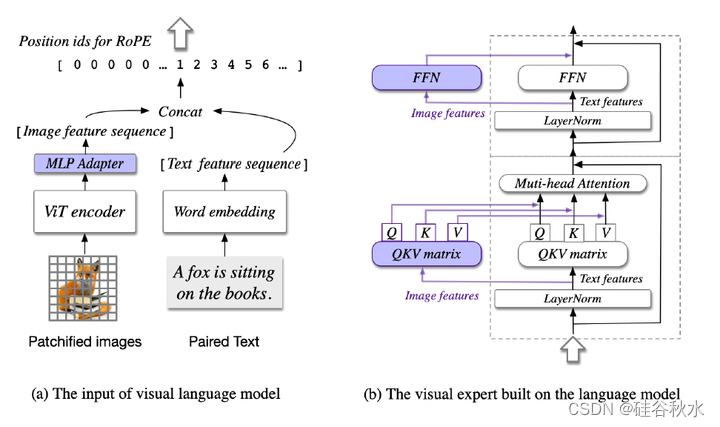
本文基于一个开源的VLM模型,CogVLM (来自清华大学作者自己的论文“CogVLM: Visual Expert for Pretrained Language Models”),其体系架构如图所示:(a) 关于输入的说明,其中图像由预训练的ViT处理,并映射到与文本特征相同的空间中。(b) 语言模型中的Transformer块。图像特征具有不同的QKV矩阵和FFN。
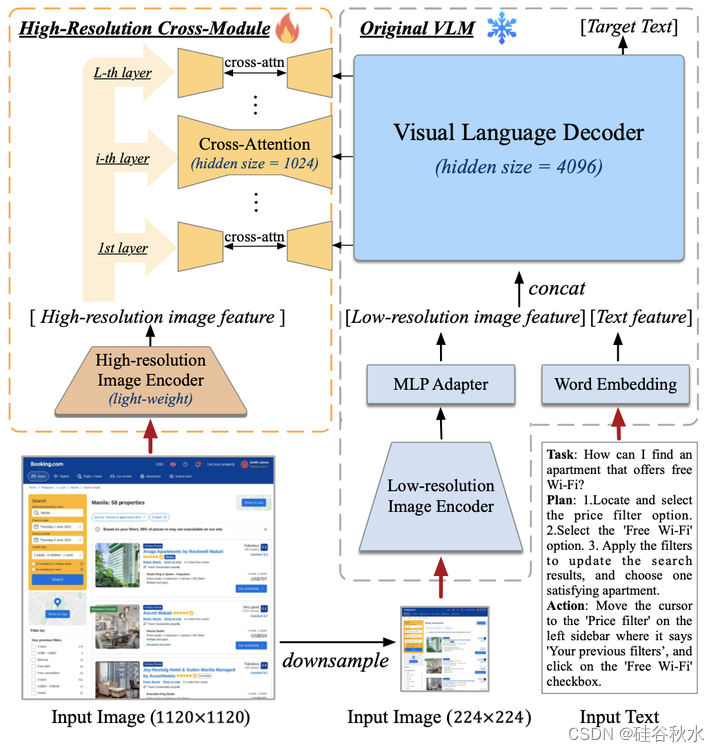
CogAgent的体系结构如图所示。基于预训练的VLM(图右)建立模型,并建议添加一个交叉注意模块来处理高分辨率输入(图左)。作为基础VLM,选择CogVLM-17B[38],这是一个开源大型视觉-语言模型。具体而言,用EVA2-CLIP-E[35]作为低分辨率图像(224×224像素)的编码器,并辅以MLP适配器,该适配器将其输出映射到视觉-语言解码器的特征空间中。解码器是一种预训练的语言模型,通过一个视觉专家模块进行了增强[38],促进视觉和语言特征的深度融合。解码器处理低分辨率图像特征序列和文本特征序列的组合输入,并自回归地输出目标文本。
该方法解决了LAION和COYO等数据集中GUI图像的稀缺性和有限相关性,这些数据集主要以自然图像为特征。GUI图像及其独特的元素,如输入字段、超链接、图标和独特的布局特征,需要专门的处理。为了提高模型解释GUI图像的能力,作者概念化了两个GUI基础任务:(1)GUI参考表达生成(REG)——其中模型的任务是基于屏幕截图中的指定区域为DOM(文档目标模型)元素生成HTML代码;(2)GUI参考表达理解(REC)–这涉及到为给定的DOM元素创建边框。为了促进GUI基础中的鲁棒训练,构建CCS400K(Common Crawl Screenshot 400K)数据集。这个广泛的数据集是从最新的Common Crawl数据中提取URL然后捕获400000个网页截图而形成的。除了这些屏幕截图,还使用Playwright编译了所有可见的DOM元素及其相应的绘制框,为数据集补充了1.4亿个REC和REG问-答对。这个丰富的数据集确保了对GUI元素的全面训练和理解。为了降低过拟合的风险,采用了不同范围的屏幕分辨率进行渲染,这些分辨率是从各种设备的常用分辨率列表中随机选择的。此外,为了防止HTML代码变得过于广泛和笨拙,按照[16]中概述的方法,通过省略DOM元素中的冗余属性来执行必要的数据清理。
在预训练期间,还整合了公开可用的文本图像数据集,包括LAION-2B和COYO-700M(删除损坏的URL、NSFW图像以及带有嘈杂字幕和政治偏见的图像)。
对CogAgent模型进行了总共60000次迭代的预训练,批量大小为4608,学习率为2e-5。在前20000步中,冻结了除新添加的高分辨率交叉模块外的所有参数,导致总共646M(3.5%)个可训练参数,然后在接下来的40000步中,在CogVLM中额外解冻视觉专家。首先对更容易的文本识别(自然图像的合成渲染和OCR)和图像字幕进行训练,然后依次结合更难的文本识别、基础数据和网页数据,为课程学习(CL)做准备,因为这会在初步实验中带来更快的收敛和更稳定的训练。
为了增强模型在各种任务中的性能,并确保它与GUI设置中自由形式的人工指令保持一致,进一步在广泛的任务中微调模型。从手机和电脑中手动收集了2000多张截图,每个截图都由人工标注员以问答格式注释屏幕元素、潜在任务和操作方法。还利用Mind2Web[10]和AITW[31]这两个数据集专注于网络和安卓行为,包括任务、动作序列和相应的屏幕截图,并使用GPT-4将其转换为自然语言问答格式。此外,将包含各种任务的多个公开可用视觉问答(VQA)数据集合并到对齐数据集中。在此阶段,解冻所有模型参数,并训练10k次迭代,批量大小为1024,学习率为2e-5。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









