









23年12月来自普度大学的论文“Large Language Models for Autonomous Driving: Real-World Experiments“。
准确理解人类的命令,特别是对于只有乘客而不是驾驶员的自动驾驶汽车,并实现高度个性化,仍然是自动驾驶系统开发中具有挑战性的任务。本文介绍一种基于大语言模型(LLM)的框架Talk-to-Drive(Talk2Drive),用于处理来自人类的口头命令,并利用上下文信息做出自动驾驶决策,满足他们在安全、高效和舒适方面的个性化偏好。首先,为Talk2Drive开发了一个语音识别模块,将人类的语言输入解释为文本指令,然后将其发送给LLM进行推理。然后,生成用于ECU的适当命令,实现运行代码100%成功率。
用I表示人类输入,用C表示驾驶上下文信息,用H表示历史数据,用P表示生成的策略代码,用F表示来自人类的反馈。
如图是Talk2Drive框架架构。人类的口头指令由基于云的LLM处理,LLM根据天气、交通状况和当地交通规则信息合成上下文数据C。LLM生成可执行代码P,这些代码P被传送到车辆ECU。这些代码操作车辆控制装置的驱动,确保将人类的意图转化为安全和个性化的驾驶行为。记忆模块将每个命令I、其生成的代码P和随后的用户反馈F存档,确保个性化驾驶体验的不断完善。
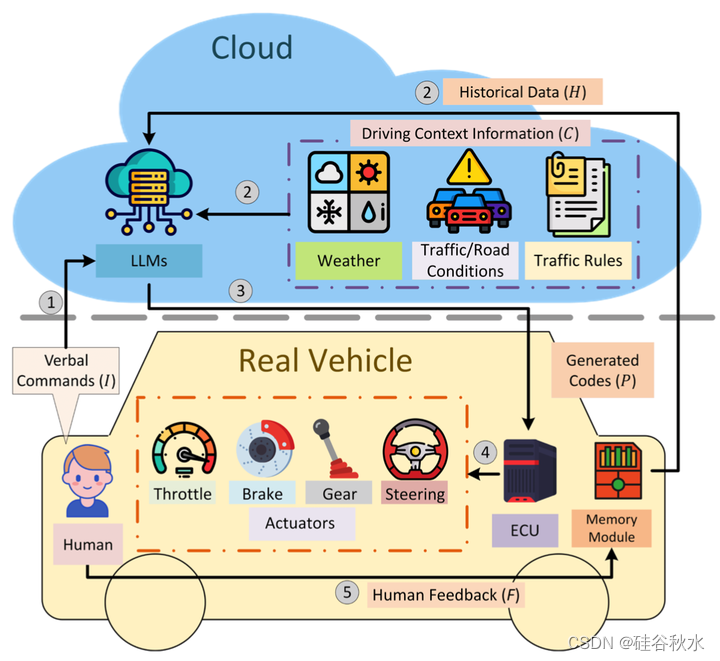
第一步涉及直接接收来自人类的任意口头命令。利用尖端的语音识别技术,特别是开源的API Whisper[44],这些口头命令被准确地捕获,然后被翻译成文本指令(I)。这种翻译对于确保人类口语的内容和特点有效地转换为可供LLM处理的文本格式,至关重要。同时,LLM访问额外的基于云的实时环境数据,包括天气更新、交通状况和当地交通规则信息。例如,LLM可以授权通过Openweather API[45]的天气信息、通过OpenStreetMap API[46]的地图信息(如道路类型和限速)以及通过TomTom API[47]的交通信息。所有这些上下文数据(C)都是文本格式的,在决策过程中至关重要,确保效应考虑环境上下文。
下一步是用LLM处理和推理文本命令。一旦命令被翻译成文本,它就会被上传到云上托管的LLM。这就是Talk2Drive功能的核心所在。LLM参与推理过程来解释命令(I)。此外,LLM结合了在上一个步骤中提供的上下文数据(C)。信息将作为输入提示传输给LLM。例如,如果当前的天气状况表明有雪,LLM可以智能地知道以较低的速度启动驾驶会更安全。此外,LLM还访问记忆模块,即历史交互(H)的存储库,考虑人类过去的行为和偏好。
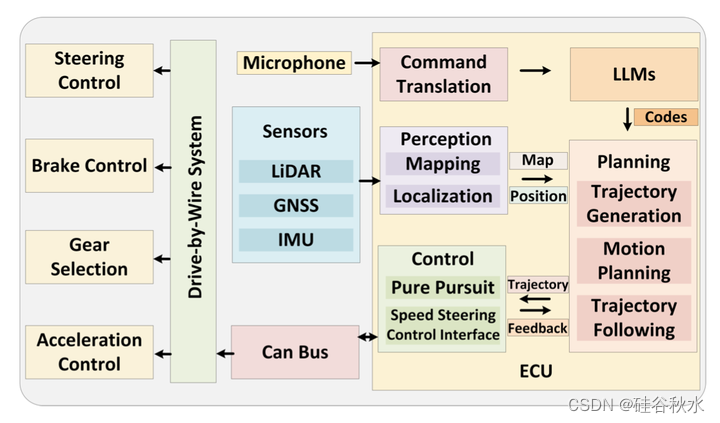
然后LLM推理过程输出由用于规划和控制的可执行代码组成。受“代码即策略[48]”概念的启发,LLM随后基于此解释生成相应的代码(P)。这些代码不仅仅是简单的指令;还包括复杂的驾驶行为和需要在车辆的低级控制器中调整的参数。具体来说,生成的代码调整控制参数,如向前看距离和向前看比率,优化pure pursuit控制性能。此外,这些代码还修改车辆的目标速度,满足驾驶员的指令。这些动作代码采用ROS题目命令的形式,指导基于Autoware[49]的自动驾驶系统修改其轨迹跟随配置。
生成的代码(P)随后从云端发送回给车辆ECU,并在那里执行。此外,还为生成的代码设置两种安全检查。首先,检查生成代码的格式,如果代码的格式无效,Talk2Drive框架将不会提供与生成代码相关的任何响应或行动。执行代码的另一个安全检查是参数验证。它评估给定的参数对于当前情况是否合适和安全,并防止执行可能具有潜在危险的代码。例如,如果生成的代码设置的目标速度明显超过速度限制,系统将识别它并禁止执行这些代码。代码执行涉及调整车辆规划和控制系统中的基本驾驶行为和各种参数。ECU执行这些代码后,车辆的执行器通过CAN总线和线控系统控制油门、制动器、档位选择和转向盘,实现LLM生成的代码所指定的驾驶行为,如图所示。
在最后一步,一种新的记忆模块来存储人和车辆之间的历史交互(H),这是Talk2Drive框架的关键特征,从而强调了其对个性化的重视。人与车辆之间的每次互动都会被记录下来,并以文本格式保存在ECU内的存储模块中。该记录包括人类的命令I、LLM生成的代码P和人类的反馈F。每次旅行后,存储模块中的历史数据都会更新。考虑到LLM的自适应性质,如果用户对类似命令的响应不同,LLM将优先考虑最近的响应,作为其当前决策过程的参考点。当用户发出命令时,LLM访问记忆模块,并将存储的信息(H)作为决策过程的输入提示的一部分。
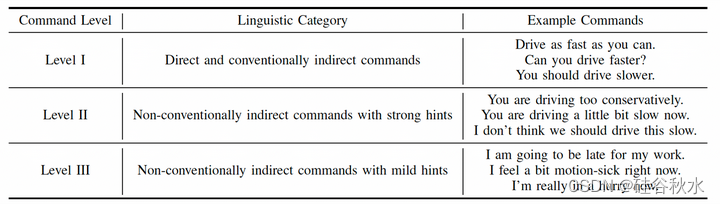
传统的间接策略主要改变直接策略的礼貌水平,根据暗示的强度将非传统的间接请求分为两类。根据指导程度,对命令中不同强度的暗示进行分类。为了收集数据,要求测试驾驶程序根据说话的偏好生成命令,然后将命令分类到定义的级别中,如下表包括生成的命令示例。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









