









23年9月来自瑞士ETH、德国MPI和比利时鲁文大学的论文“TrafficBots: Towards World Models for Autonomous Driving Simulation and Motion Prediction“。
数据驱动仿真已经成为训练和测试自动驾驶算法的一种有利方式。在世界模型的背景下,在基于模型的强化学习中,也探索了用学习的模拟器取代实际环境的想法。该文展示了数据驱动的交通模拟可以被公式化为一个世界模型。TrafficBots,一种基于运动预测、端到端驾驶的多体策略。基于TrafficBot,可获得一个为自动驾驶汽车规划模块量身定制的世界模型。现有的数据驱动交通模拟器缺乏可配置性和可扩展性。为了生成可配置的行为,为每个智体引入一个目的地作为导航信息,还有一个时域不变潜在个性的行为风格。为了提高可扩展性,提出一种角度位置编码方案,允许所有智体共享相同的矢量化上下文,并用基于点积注意的架构。因此,可以模拟在密集的城市场景中看到的所有交通参与者。在Waymo开放运动数据集上的实验表明,TrafficBots可以模拟真实的多智体行为,并在运动预测任务上取得良好的性能。
如图是自动驾驶规划模块的世界模型,该模拟器全数据驱动,完全可微分。
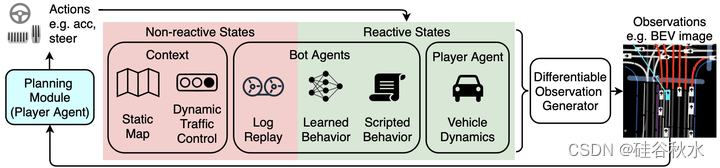
如图是TrafficBots,一种多智体策略,从真实世界的数据中学习,为机器人智体生成现实的行为。

策略基于当前状态st和上下文来预测下一步st+1的智体状态。在对st进行编码后,上下文被顺序地注入到编码状态st中。用交叉注意的Transformer编码器层,通过关注编码地图M和编码交通灯Ct来更新st。交互Transformer使用跨智体的自注意来允许智体相互关注。在推断时,非TrafficBots代理s†的状态也将由这些Transformer处理,以便TrafficBot可以对其做出反应。在合并了地图、交通灯和其他智体状态后,每个智体都有一个递归单元来聚合其历史,因为模拟状态不是马尔可夫的。然后,经过串联和残差MLP,将输出与智体个人目的地和个性相结合。最后,由动作头预测每个智体的动作,并且基于动作和st+1由动力学模块来计算st+1。
下图是TrafficBots的网络架构:括号中是张量形状,其中B是批次大小。为了简洁起见,省略了隐藏/特征大小。共享和私有(不是共享)上下文在每个故事片段(episode)开始时只编码一次。
SceneTransformer[12]将位置编码与方向和其他属性的单位向量连接起来,然后将其提供给MLP。这里位置编码和交叉注意一起,便于对全局到每个智体局部的转换建模。
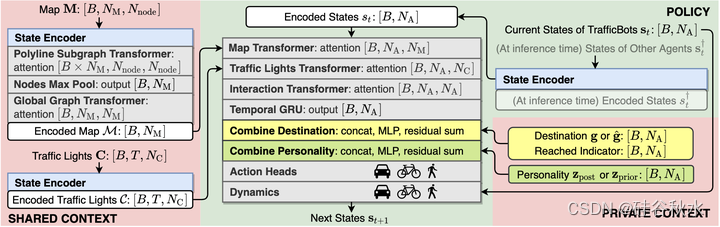
如图是不同状态编码器的架构:

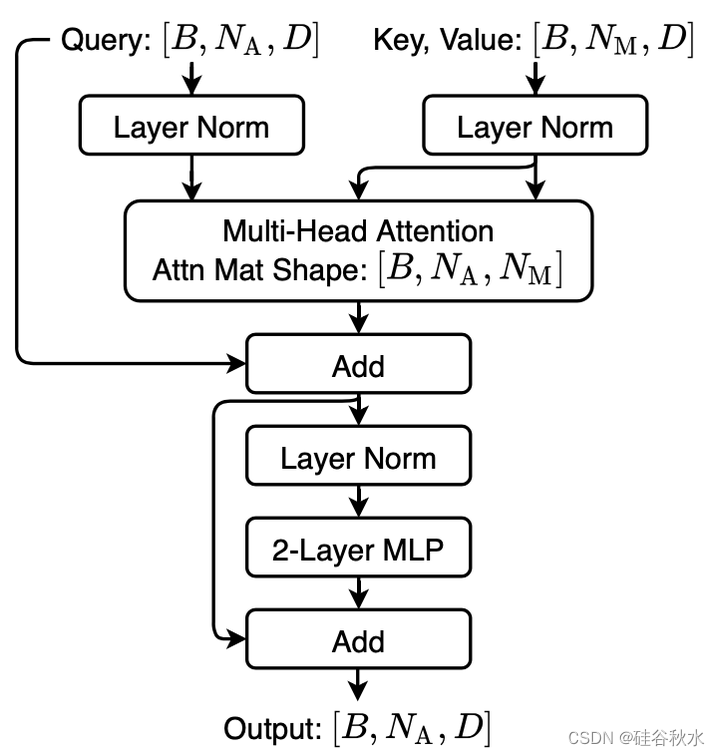
如图是Transformer带layer norm的编码器层:
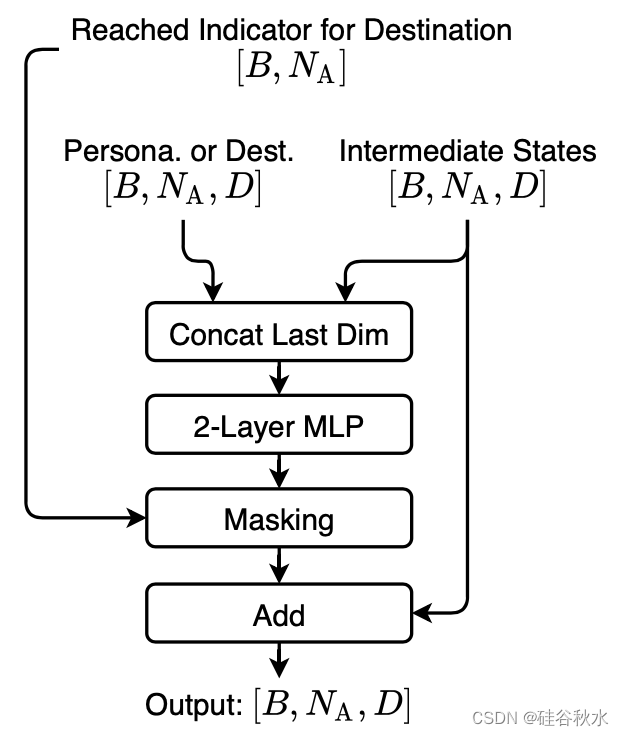
如图显示的是,组合个性化或者目的地,通过级联、MLP和残差和,注入到中间状态:
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









