









23年4月来自谷歌、谷歌waymo和其他几个大学的论文“OpenScene: 3D Scene Understanding with Open Vocabularies“。
传统的3D场景理解方法依赖于标注的3D数据集来训练监督的单任务模型。OpenScene,是一种替代方法,其中模型预测与CLIP特征空间中文本和图像像素共同嵌入的3D场景点密集特征。这种零样本方法可以实现任务无关训练和开放式词汇查询。例如,为了执行SOTA零样本3D语义分割,它首先推断每个3D点的CLIP特征,然后根据与任意类标签嵌入的相似性对其进行分类。更有趣的是,它实现了一套以前从未做过的开放词汇场景理解应用程序。例如,它允许用户输入任意文本查询,然后查看一个能指示哪些部分场景是匹配的热图。
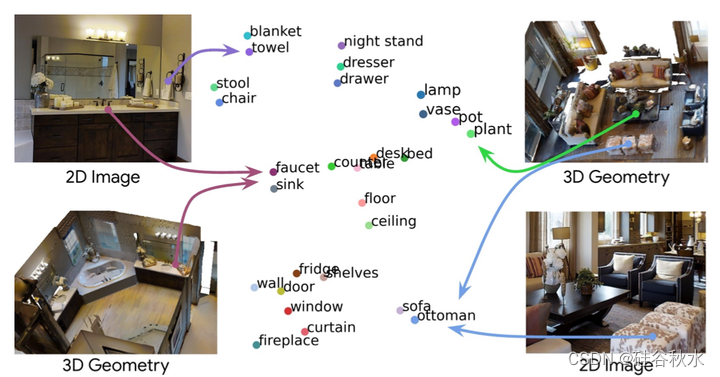
如图可视化这个想法:用CLIP特征空间(用T-SNE[52]可视化)中文本和图像像素共同嵌入那些3D点,该特征空间具有从大型图像和文本库中学习的结构。
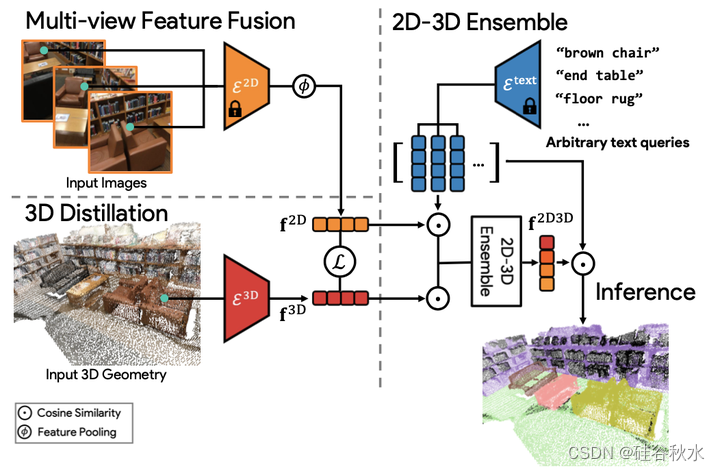
如图是该方法概览:给定3D模型(网格或点云)和一组姿势图像,训练一个3D网络以产生3D点的密集特征,3D点具有一个所投影像素多视图融合特征的蒸馏损失。对一个任意查询集,基于与CLIP嵌入的余弦相似性来集成3D点特征和2D投影特征。在推理过程中,用逐点特征和给定CLIP特征之间的相似性得分来执行开放词汇3D场景理解任务。
本文展示了该方法在零样本、开放词汇三维场景理解中的实用性。它在标准基准上实现了零样本3D语义分割的先进状态,在具有许多类标签的3D语义分割中优于监督方法,并启用了新的开放词汇应用程序,其中可以使用任意文本和图像查询来查询3D场景,而无需使用任何标记的3D数据。这些结果为3D场景理解提供了一个新的方向,即从大量多模态数据集训练的基础模型指导3D场景理解系统,而不是仅用小的标记3D数据集训练它们。
不过,该工作有几个局限性。首先,当图像出现在前融合的测试时,推理算法可能会更好地利用像素特征(尝试了这种方法,但收效甚微)。其次,实验可以扩展到在更广泛的任务中研究开放词汇3D场景理解的局限性。对闭集三维语义分割进行了广泛的评估,但由于缺乏具有基本事实的三维基准,因此只能为其他任务提供定性结果。在未来的工作中,设计实验来量化开放词汇查询在无法获得基本事实的任务中的成功将是一件有趣的事情。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









