










23年10月来自谷歌和CMU的工作的论文“Language Model Beats Diffusion — Tokenizer Is Key To Visual Generation“。
虽然大语言模型 (LLM) 是语言生成任务的主要模型,但在图像和视频生成方面其表现不如扩散模型。 为了有效地使用 LLM 进行视觉生成,一个关键组件是视觉token化器,它将像素空间输入映射到适合 LLM 学习的离散token。 本文介绍MAGVIT-v2,这是一种视频token化器,旨在用一个通用token词汇为视频和图像生成简洁且富有表现力的token。 配备了这个新的token化器,证明 LLM 在标准图像和视频生成基准(包括 ImageNet 和 Kinetics)上优于扩散模型。 此外,还证明该token化器在另外两项任务上超越了之前表现最好的视频token化器:(1)根据人类评估,视频压缩可与下一代视频编解码器(VCC)相媲美;(2)为动作识别任务学习高效的表征。
在论文“MAGVIT: Masked generative video transformer“(Yu2023a),MAGVIT-v1引入了更好的 3D 架构、图像预训练初始化的膨胀技术以及稳健的训练损失。 借助 MAGVIT,LM 在多个视频基准测试中实现了领先的质量。
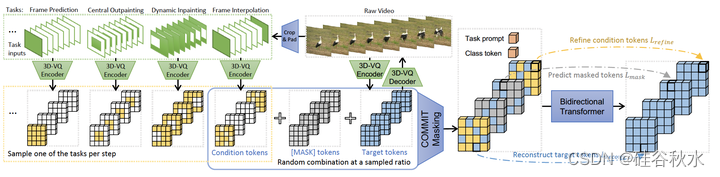
如图所示:D-VQ 编码器将视频量化为离散token,而 3D-VQ 解码器将它们映射回像素空间。 在每个训练步骤中对其中一个任务进行采样,并通过裁剪和填充原始视频来构建其条件输入,其中绿色表示有效像素,白色表示填充。 用 3D-VQ 编码器量化条件输入,并选择非填充部分作为条件token。 掩码token序列组合了条件 tokens、掩码tokens和目标tokens,并以一个任务提示和一个类标记作为前缀。 双向Transformer通过三个目标学习预测目token:细化条件token、预测掩码token和重建目标 token。
不过MAGVIT 很难对图像进行token化,并且经常导致较长视频中出现明显的闪烁。本文改进MAGVIT,旨在将视觉场景中的时空动态映射为适合语言模型的紧凑离散token。 其方法包含两个新设计:无查找的量化器和token化器模型的一系列增强功能。
训练更大的码本的一个简单技巧是在增加词汇量时减少代码嵌入维度(Yu2022a)。 这个技巧抓住了一个直觉,限制单个token的表示能力,反过来这又促进了对大词汇量分布的学习。
受上述观察的启发,将 VQ-VAE 码本的嵌入维数减少到零。形式上,将码本C替换为整数集C,其中|C|=K。回想一下,在VQ-VAE模型中,当计算与编码器输出最接近的码本条目时,量化器必须查找码本中的所有K个d维嵌入,其中d通常为256。这种新的设计完全消除了对这种嵌入查找的需要,因此称之为无查找量化(LFQ)。
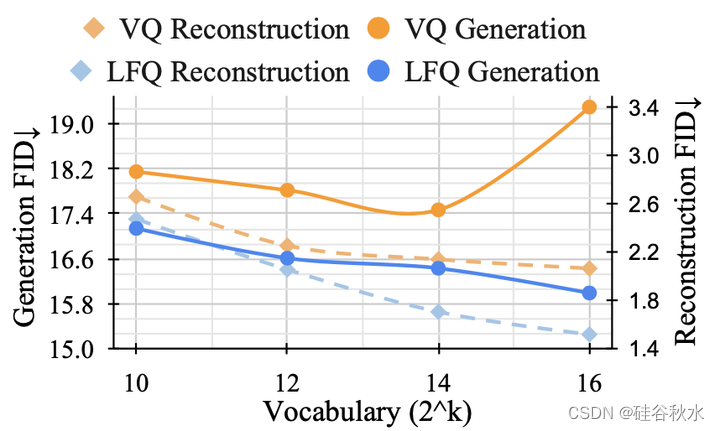
LFQ 可以增加词汇量,有利于语言模型的生成质量。 如图中的蓝色曲线所示,随着词汇量的增加,重建和生成都持续改进——这是当前 VQ-VAE 方法中未观察的属性。
为了构建联合图像视频token化器,需要一种新的设计。 如图是token化器的比较:(a-c)
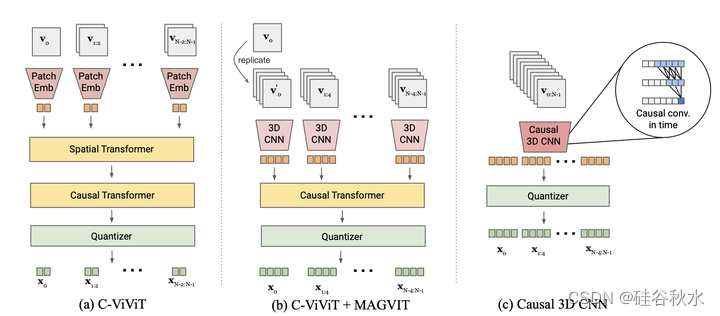
首先回顾现有的方法 C-ViViT(Villegas 2022)。 如图a 所示,C-ViViT 采用与因果时间Transformer块相结合的完整空间Transformer块。 这种方法表现相当不错,但有两个缺点。 首先,与 CNN 不同,位置嵌入使得很难对训练期间未见过的空间分辨率进行token化。 其次,根据经验,3D CNN 的性能比空间Transformer更好,并且生成的token与相应补丁(patch)具有更好的空间因果关系。
为了解决这些缺点,探索了两种可行的设计。 图b结合 C-ViViT 和 MAGVIT。 假设时间压缩比为 4,3D CNN 处理 4 帧块,然后处理因果Transformer。 在图c中,用时间因果 3D 卷积来代替常规 3D CNN。 具体来说,内核大小(kt, kh, kw) 常规 3D 卷积层的时间填充方案包括输入帧之前的 (kt-1)/2 帧和之后的 kt/2 帧。相比之下,因果 3D 卷积层在输入之前填充 kt -1 帧,之后不填充任何内容,因此每个帧的输出仅取决于之前的帧。 因此,第一帧始终独立于其他帧,从而允许模型对单个图像进行token化。
将 1+s×t 帧映射到 1+t,步幅为 s 的时间卷积子采样足以进行 s ×下采样。 在常规 s ×上采样之后,丢弃前 s-1 个结果帧,这样将 1+t 帧映射为 1+s×t 并允许对单个图像进行token化。
除了因果 3D CNN 层之外,作者还进行了其他几项改进 MAGVIT 模型的架构修改。 首先,将编码器下采样器从平均池化更改为跨步卷积,这样利用学习的内核,并将解码器从最近邻的上采样器进行大小调整替换为“深度-到-空间”算子的卷积。 其次,将时间下采样从前几个编码器块推迟到最后一个。 此外,鉴别器中的下采样层现在利用 3D blur池化(Zhang,2019)来鼓励平移不变性。 最后,按照StyleGAN (Karras 2019),在解码器中每个分辨率的残差块之前添加一个自适应分组归一化(GN)层,将量化的潜变量作为控制信号传递。
输出token可以输入到语言模型中,生成视频。 为了帮助较小的Transformer在大词汇量中进行预测,可以将 LFQ token的潜空间分解为相等的子空间。 例如,可以在两个串联的码本(每个大小为 29)中进行预测,而不是用大小为 218 的码本进行预测。分别嵌入每个子空间token,并用它们的嵌入总和作为Transformer输入的token嵌入。 对于权重绑定的输出层(Press & Wolf,2017),用每个子空间的嵌入矩阵来获得具有单独预测头的 logits。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









