










23年2月来自麻省大学和微软的论文“How Does In-Context Learning Help Prompt Tuning?“。
由于大语言模型规模迅速增长,微调变得越来越不切实际。 这激发了参数高效适应(parameter-efficient adaptation)方法的使用,例如提示调优(PT)和上下文学习(ICL),前者将少量可调嵌入添加到冻结的模型中,后者向学习者提供任务演示。 无需任何自然语言模型的额外训练。 最近(Singhal 2022) 的指令提示调优(IPT),将自然语言演示与学习的提示嵌入连接起来,即PT与 ICL 结合。 尽管这些方法都已被证明对不同的任务有效,但如何相互作用仍有待探索。
本文测量 ICL、PT 和 IPT 在具有多个基本语言模型的五个文本生成任务上的有效性,实证研究了上下文示例何时以及如何改进提示调优(PT)。 发现的是:(1)IPT 并不总是优于 PT,事实上需要上下文演示在语义上与测试输入相似才能产生改进; (2) PT 不稳定并且表现出很高的方差,但是将 PT 和 ICL 结合起来(形成 IPT)一致地减少了所有五项任务的方差; (3) 通过 PT 学习的特定任务提示,在与不同目标任务的上下文示例配对时,表现出正迁移。
最简单的方法是利用上下文学习(ICL),其中LLM通过指示或演示提示来解决新任务,无需任何额外的训练(Brown 2020)。 动态检索与特定测试输入相似的演示,取代随机选择演示,可以进一步改进 ICL(Liu 2022b)。 然而在复杂的和域外(OOD)的下游任务上,其仍然苦苦挣扎(An2022; Liu2022a)。
ICL 的局限性引出了少量训练是否有帮助的问题。 在提示调优(PT)中,绝大多数 LLM 保持冻结,而少量新的可调整嵌入被连接到每个测试输入(Lester 2021)。 虽然PT总体上优于ICL,但它不稳定且难以优化(Ding 2022)。
最近Singhal (2022) 将 ICL 和 PT 结合到指令提示调优(IPT)中,将检索的上下文演示与可调的提示嵌入连接起来,并使LLM适应医学领域方面的有效性。
如图展示的是指令提示调优 (IPT) 。 软可调提示嵌入被预先添加到检索的上下文演示中,接着是一个训练示例。
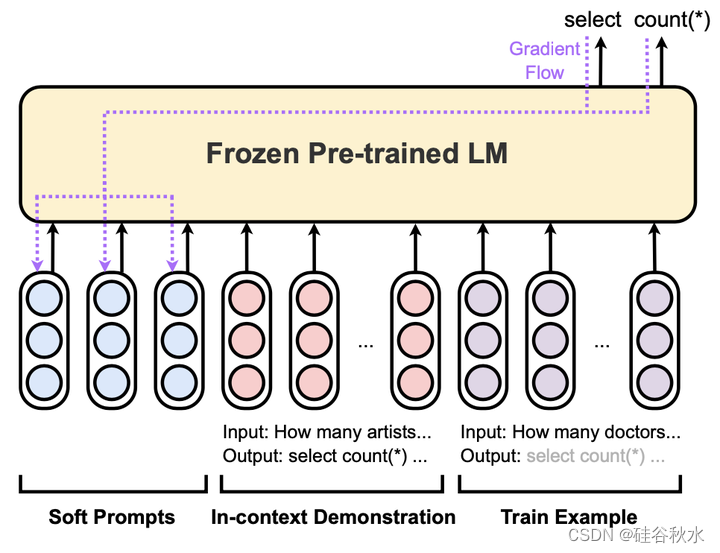
参数高效微调(PET)方法(Houlsby 2019;Karimi Mahabadi 2021;Ben Zaken 2022)将 LLM 专门用于目标任务,同时保持大部分参数冻结并仅调整少量特定于任务的参数。 由于对于大多数LLM来说,在消费级硬件上进行全模型微调的成本过高,因此此类方法增加了LLM研究和部署的可及性。
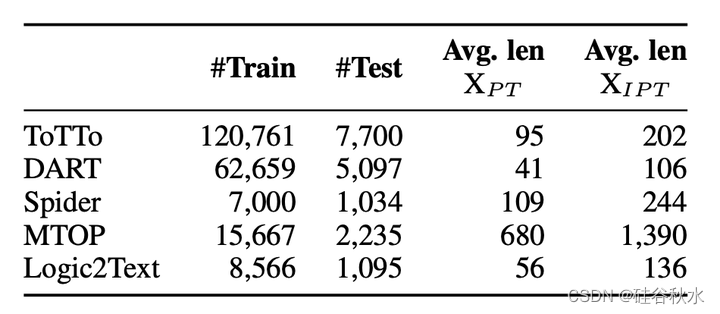
本文研究三种任务:数据-到-文本生成、逻辑-到-文本生成和语义解析。 在数据-到-文本生成中,输入是结构化数据,要么表示为 DART 中的三元组集(Nan2021),要么表示为 ToTTo 中的线性化表字符串(Parikh 2020)。 这两个任务的输出都是描述数据或表格的短句,并使用 BLEU 进行评估(Papineni 2002)。 对于语义解析,其中自然语言话语被映射为逻辑形式,对Spider(Yu2018)和MTOP(Li2021)进行评估并报告精确匹配精度。 最后,在 Logic2Text 逻辑-到-文本任务(Chen 2020)中,用度量 BLEC 与其他工作保持一致(Xie 2022)。有关每个数据集的更多详细信息见下表。
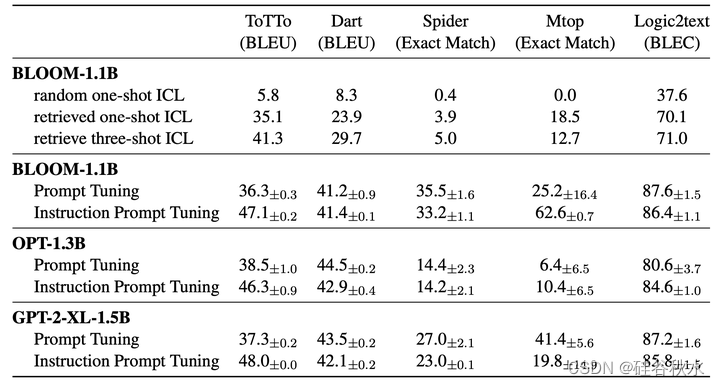
在所有任务中都用 BLOOM-1.1B3、OPT-1.3b4 和 GPT-2-XL-1.5B5 模型进行实验。 对于细粒度分析,重点关注 BLOOM 检查点,有 24 个 Transformer 层、1536 的嵌入维数和 16 个注意头,并接受了多语言文本和编程语言语料库的训练。为了更稳定、更快的提示调优收敛性,采用(Li & Liang2021) 引入的重参数化技巧,在初始提示嵌入之上添加了两个前馈层; 然后将转换后的提示嵌入反馈到模型中。对于 PT 和 IPT,随机初始化所有提示嵌入,使用批量大小 8,并使用 AdamW 优化器(Loshchilov & Huter,2019)。
如 (Liu2022b),使用密集检索来选择良好的上下文示例以进行指令提示调优。 用大语言模型对每个示例的输入进行编码,并提取最后的token表示作为编码序列的密集表示。 然后,用 FAISS(Johnson 2019)检索最近邻训练示例作为上下文演示。
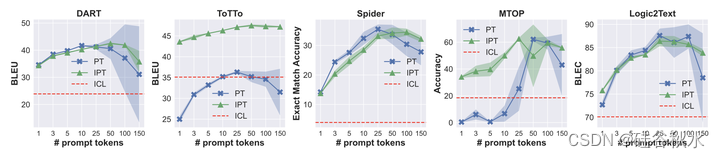
如表所示,尽管 PT 和 IPT 通常都优于 ICL,但提供检索的上下文演示明显优于随机上下文训练演示。 在这里,仅报告具有 25 个可调提示嵌入的 PT 和 IPT 的性能。
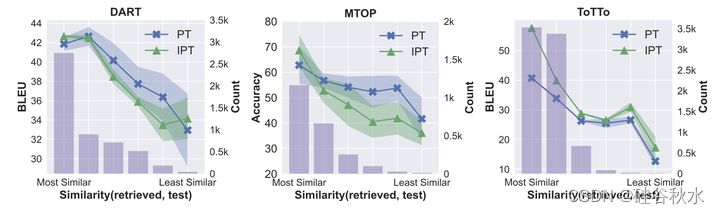
如下两个图是IPT和PT结果的性能比较:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









