









23年6月来自斯坦福团队的论文“Aladdin: Zero-Shot Hallucination of Stylized 3D Assets from AbstractScene Descriptions“。
什么构成了特定场景的“氛围(vibe)”? 人们应该在“繁忙、肮脏的城市街道”、“田园诗般的乡村”或“废弃客厅中的犯罪现场”中找到什么? 在严格且有限的室内数据集上训练的现有系统,无法具备任何通用性去完成从抽象场景描述到风格化场景元素的转换。
利用基础模型捕获的知识来完成此关键转换。 即一个系统,可以作为一种工具为短语描述的 3D 场景生成风格化3D物体模型,无需枚举场景中要找到的目标或给出有关其外观的说明。 此外,它对开放世界概念具备鲁棒性,这是有限数据训练的传统方法所不具备的,为此给3D 艺术家提供了更多的创作自由。
该系统由大语言模型、视觉语言模型和多个图像扩散模型组成的基础模型“团队”来完成这一点,这些模型用可解释和用户可编辑的中间表示进行通信,从而为3D 艺术家生成更通用和更可控的风格化物体模型。 作者引入新指标,并通过人工评估表明,在 91% 的情况下,系统输出比基线更忠实于输入场景描述的语义。这种方法提供一种潜力,从根本上加速3D 艺术家的 3D 内容创作过程。
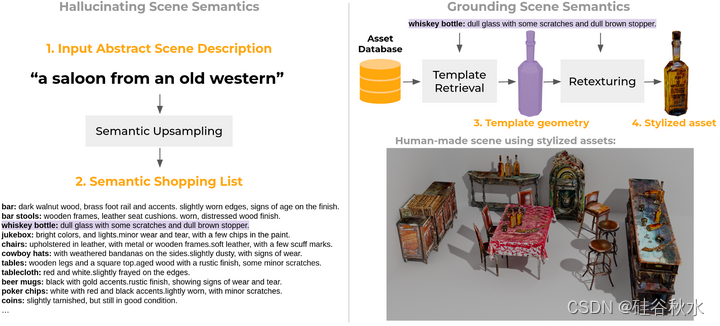
如图所示:系统生成适合场景描述的风格化物体模型。 给定一个抽象场景描述,该描述没有提供有关在该场景中应该找到哪些目标的详细信息,系统可以(1)推断出一个语义购物清单,人类可读和可编辑的目标类别和外观属性列表,然后用它来 (2) 从 3D 资源数据库检索模板形状,然后 (3) 重新纹理化以适应所需的外观属性。 系统的输出是纹理网格的集合,可以直接导入到 3D 设计软件中并用于其他下游任务。 注意右侧的资源与左侧系统生成的目标类别和外观属性的对应关系。
具体实现如下。
给定一个抽象的场景描述,系统将场景描述的语义“上采样”到目标类别、属性和外观的级别。 为此,用 GPT-3 的小样本提示 [Brown 2020],这已被证明在其他设置中非常有用[Chen 2022; Dong2022; Min 2021; Robin2021; Shen2022; Wang2022; Wei 2021/2022;Zhang2022; Zhao 2021; Zhou2022]。
为此,创建涵盖场景中可能找到目标的各个不同方面模板; 目标类别、样式、材料属性和状况(例如划伤、未使用、生锈等)。 采用模板有两个主要原因:(1)它们有效地强制执行人们想要用来描述场景中目标属性类型的先验;(2)它们规定了一种可以非常容易解析的系统文本格式(例如,逗号分隔的属性、目标类别和属性之间的冒号分隔)。
在实践中发现,一次查询场景中的所有目标可能会导致退化结果 - 一次生成太多目标的详细信息可能会导致所选目标在语义上“偏离”提示。 因此,采用了一种更加分层的方法,首先用上下文学习来询问 GPT-3 [Brown2020] 生成一组“锚”目标(通常是一小组 6-8 个目标)及其属性。 对于每个锚点目标,要求幻觉在锚点目标“周围”找到的目标(及其属性),并在层次结构中递归地重复此操作。 这对于阐明目标的层次结构非常有效,并且对于目标放置很有用(例如,对于“高档法国餐厅”,生成的锚目标是一张桌子(“根”节点),围绕该锚目标生成的目标,是通常在桌子上找到的目标)。 此外,按层次结构执行此操作意味着,对于涉及大量目标的抽象描述,只需调用此过程几次即可到达隐目标层次结构中的“叶节点”目标。 遍历该层次结构可以得到可能在所描述的场景中找到的目标和目标的外观属性的完整列表。 此列表被称为语义购物列表。
给定来自语义上采样的语义购物清单,系统使用 CLIP [Radford 2021] 在资产数据库中嵌入目标的视觉渲染和文本注释,检索每个目标的模板几何形状。
然而,由于检索期间选择的所有目标都将经过基于扩散的重纹理,因此很容易完全忽略原始纹理,并也仅用由语义上采样中的目标类别信息组成的查询进行检索(忽略目标属性,这将是“ 在稍后阶段涂上”)。 实际上,这会导致检索结果不理想。 某些目标属性(例如“旧车”中的“旧”)不太完全基于纹理,会影响视觉外观和几何形状。 此外,CLIP 的预训练模型是在自然图像上进行训练的,该模型依赖于颜色属性来进行准确的相似性评估([Michel 2022] )中也报告了类似的观察结果。 因此,使用候选资产的无纹理渲染实际上会损害检索性能。
为了匹配语义购物清单中的开放世界词汇,必须有一个庞大且多样化的资产数据库可供选择。
选择用 Future3D [Fu 2021b] 和 Objaverse 的 30K 子集 [Deitke 2022]进行结合。 Future3D 专门研究室内环境中常见的目标,对于室内场景中发现的大多数“基本”目标来说是一个有用的数据集,预计这些目标将构成大多数用户场景查询。 Objaverse 的目标类别更加多样化,适用于室内场景的“个性化”部分,这样场景能够更加忠实于输入中传达的“氛围” 描述。 此外,它还包含在户外也会发现的目标类别,这使得系统能够构建户外场景。
在当前的实现中,用不同资产的缩略图来导出 CLIP 图像嵌入,因为 (1) 这些在大多数数据集中都很容易获得,并且 (2) 人类艺术家已经使用它们来判断特定资产对其场景的适当性 。 未来扩展的工作可以对不同的目标使用更复杂的渲染技术,而如何进行渲染以鼓励高精度 3D 资产检索的问题是未来工作的一个重要方向。
从检索阶段就加强风格一致性是很困难的。 根据经验,仅使用语义购物清单通常会导致检索出在其模板几何形状上风格不一致的目标,因此一旦放入同一场景,就无法在美学上很好地结合起来。 这是因为,虽然语义上采样会产生视觉细节的幻觉,但它对下游检索结果的风格一致性没有相关的上下文。 因此,将抽象场景描述合并到所有目标的所有检索和纹理查询中,作为语义购物清单去提供不充分风格故障的保护。
鉴于许多 3D 资产都有语言注释,在基于语言和图像的余弦相似性简单线性加权来确定 K 最近邻时,结合了该信息。 当资产缩略图不像其文本注释那样反映几何内容时,这样做会给检索过程带来更多的鲁棒性。
一旦有了模板模板,就利用预先存在的图像生成流水线来每个检索到的目标渲染纹理。 可用的深度引导和语言引导图像扩散模型 [Rombach 2022],可以生成与目标视图相对应的图像,并用可微分渲染来优化网格纹理以匹配生成的图像,同时通过深度和语言调节鼓励不同视图之间的 3D 一致性。 最近一篇论文的实现 [Richardson 2023]可实现这一目标。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









