










23年10月来自香港中文大学、新加坡国立大学、腾讯AI实验室和香港科技大学的论文“Beyond Factuality: A Comprehensive Evaluation of Large Language Models as Knowledge Generators“。
当大语言模型(LLM)被提示生成世界知识时,在下游知识密集型任务中其优于信息检索技术。然而,社区对采用这些未经审查知识的做法,担忧其事实性和潜在影响。有鉴于此,作者引入CONNER,一种知识评估方法,旨在从六个重要角度——事实性、相关性、连贯性、信息性、帮助性和有效性——系统地、自动地评估生成的知识。对三种不同类型LLM,在两项广泛研究的知识密集型任务(即开放领域问答和基于知识对话)中产生的知识进行了实证分析。研究表明,生成知识的事实性即使较低,也不会阻碍下游任务。相反,相关性和连贯性比事实小错误更重要。此外,本文还展示了如何使用CONNER设计出两种策略来改进知识密集型任务:提示工程和知识选择。
大语言模型有四条研究路线。首先,进行人类评估,从不同的角度评估生成的知识(Li 2022;Yu2023;Liu2023a)。然而,其耗时和主观性经常遇到如扩展性和再现性的问题。其次,已经构建数据集,借助参考来评估开放域的生成(Honovich2021;Glover2022a;Lee2023;Li2022)。这些方法虽然更具客观性,但由于依赖于人类标记参考而受到限制,影响了在现实世界中对动态生成内容的适用性和可推广性。第三,自我评价方法(Kadavath,2022b;Manakul,2023)估计模型生成内容的不确定性。尽管简单,但这些模型缺乏可解释性,对长答案格式效果较差。最后,当代研究应用事实核查原则来发现事实的不准确之处(Pan2023;Min2021)。然而,这些方法主要评估生成知识内在质量的单一方面,忽略了其他方面及其对下游任务的外在影响,从而限制了对LLM生成内容的全面理解。
鉴于这些局限性,文中提出CONNER(COmpreheNsive kNowledge Evaluation fRamework),一项综合性的知识评估工作,如图所示。CONNER被设计成一个无参考的框架,可以从六个粒度系统地、自动地评估生成的知识,包括对其内部属性的内在评估,以及对其对特定下游任务影响的一个统一的外在评估。
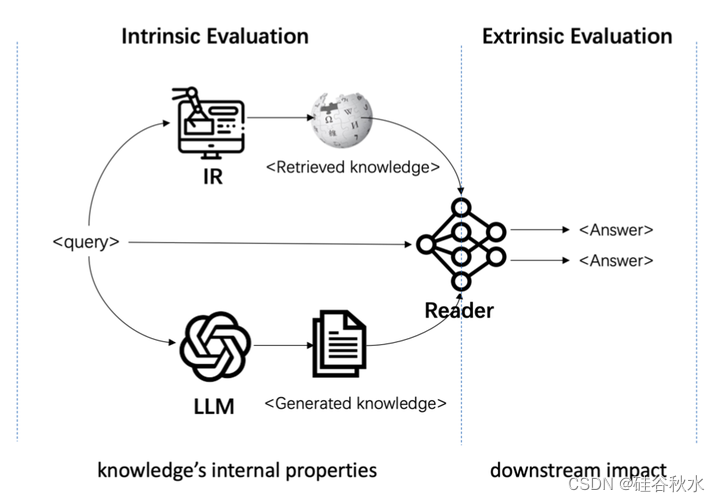
评估指标的分类见表如下:事实性、相关性、连贯性、信息性、帮助性和有效性

基于CONNER,作者对三种不同类型的LLM进行了实证评估,包括LLaMA(Wei 2022)即一个基础LLM、FLAN-T5(Wei2022)即一个指令调优的LLM,和ChatGPT(Ouyang 2021),一种用人类反馈进行训练的商业LLM。在两项广泛研究的知识密集型任务上对它们进行了评估:开放领域QA(Kwiatkowski 2019)和基于知识的对话(Dinan 2018)。
本文详细调查得出关于LLM生成知识的几个有价值看法:1)LLM生成知识在大多数评估角度都超过了检索知识,而实际上其受到预期的事实问题影响。值得注意的是,与观察的检索知识相关性和连贯性方面较低的影响相比,下游任务的事实问题被影响的程度较小。2)确定了几个影响生成知识事实性的关键因素,如其频率和长度,而少样本上下文学习和较大规模的模型并不一定能保证更高的质量和可靠性。3)除了评估和分析来自不同LLM的生成知识外,CONNER的评估结果还可以用来增强知识生成,并进一步提高下游任务的性能。
形式上,将知识密集型任务定义如下:给定用户查询q,目标是通过访问知识资源得出答案。具体地,系统首先从知识资源k中获得有助于回答查询q的相关知识k,然后用所获得的知识k生成答案a。具体地,知识资源k可以是用于知识检索的知识库,也可以是用于生成知识的语言模型。
如下两个表分别总结了DPR(一个流行的、基于检索的生成模型)和三个基于LLM的知识生成器在NQ和WoW数据集上的评估结果。 NQ:Natural Questions (Kwiatkowski 2019)是一个开放域的QA数据集; WoW:Wizard of Wikipedia (Dinan 2018) 是一个知识落地的对话数据集。
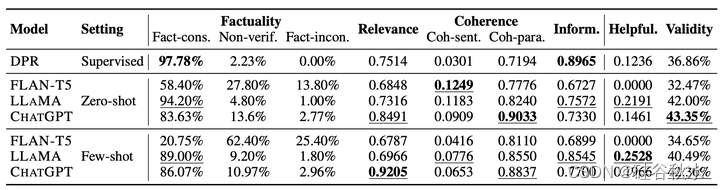
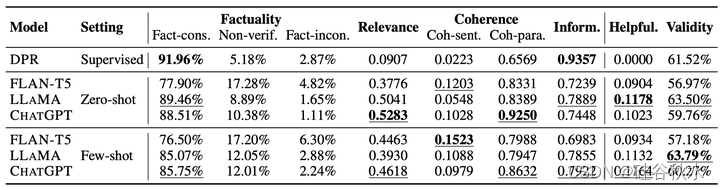
为了研究根本原因,作者分析了两项知识密集型任务其内在指标和外在指标之间的相关性。如下两个表格所示,LLM生成知识的事实性问题确实阻碍了下游任务的执行。然而,对于基于检索的模型(例如DPR),检索知识的相关性和连贯性可能会受到限制,而其高事实性还是无法确保下游任务的性能。
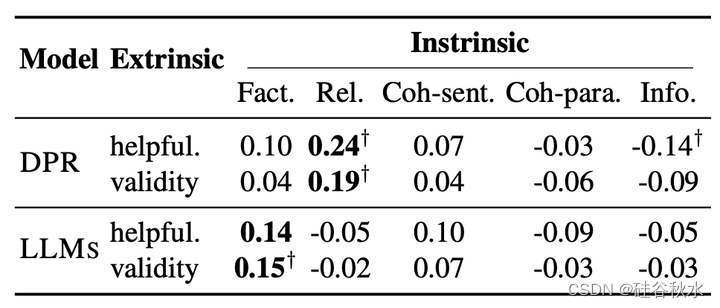
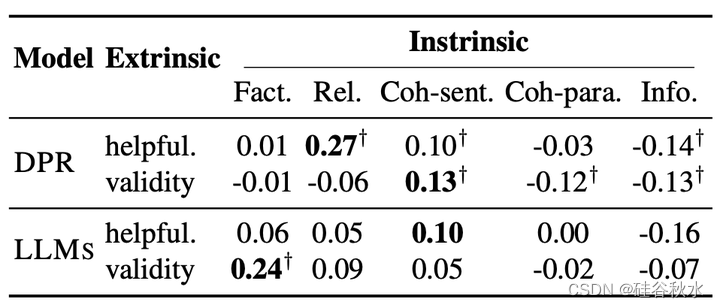
如下表是说明所获知识的事实性可能不会影响答案的有效性,从不相关的检索知识中得出正确答案是极不可能的。其中红色单词表示关键信息中的事实错误,而蓝色单词表示非关键信息中存在的事实错误。

虽然LLaMA和ChatGPT生成知识的事实性略低于DPR,但已证明其足以用于下游任务。在这一点上,所获得知识的相关性更为关键。因此,仅仅依靠知识本身的事实性,不是评估其对下游任务真实性影响的可靠手段。基于这一发现,作者研究了CONNER的多视角评估结果去引导生成知识选择的方法,以提高下游性能。
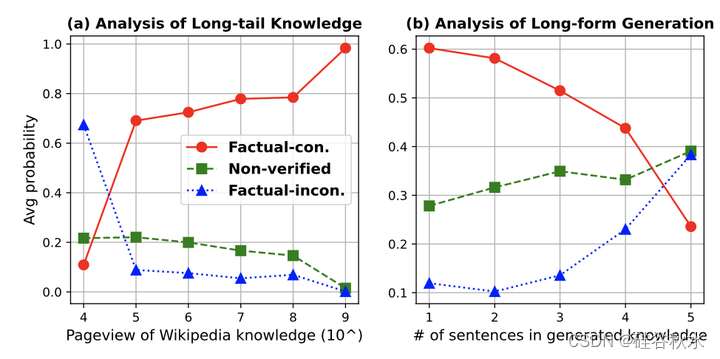
长尾知识。本文研究了知识频率对LLaMA在WoW数据集上事实性的影响。WoW的每个数据条目都包括一个主题、查询、知识和答案。该主题指示链接到知识的相应维基页面。用维基百科2015年至20213年的页面浏览量来评估这些知识的频率。这能够区分WoW的普通知识和长尾知识。研究结果表明,与常见知识相比,LLaMA在预期生成罕见/长尾知识时表现出较低的可靠性,如下图(a)所示。
长回答形式的生成。本文也研究生成长度对生成知识的事实性的影响。具体来说,考虑超过40个表征的知识,并将句子作为与事实性评估一致的评估单元。如下图(b)显示了基于生成知识中句子数量的事实性表现。结果表明,LLaMA在生成长回答形式知识时表现出较高的错误率。因此,促使LLM以简洁而非冗长的方式生成所需的知识有利于事实性。
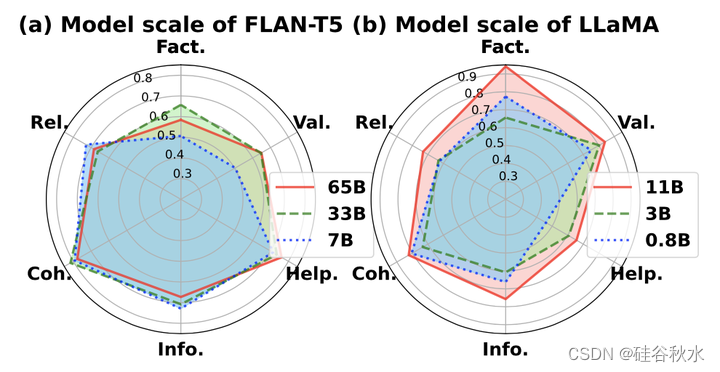
模型大小的影响。如下图描述了随模型大小的性能扩展,包括(a)LLaMA-65B/33B/7B和(b)FLAN-T5-11B/3B/780M。用零样本提示在NQ数据集上得到结果。就内在评估(事实性、相关性、连贯性和信息性)而言,较大的模型并不一定优于较小的模型(尤其是当参数大小相似时)。然而,在外在评价(帮助性和有效性)方面,较大的模型始终优于较小的模型。















 5331
5331











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









