










21年4月来自Facebook(现在Meta)、伦敦大学学院(UCL)和纽约大学的RAG原创论文“Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks“。
大型预训练语言模型已被证明可以在其参数中存储事实知识,并在下游 NLP 任务上微调时获得最先进的结果。 然而,它们访问和精确操控知识的能力仍然有限,因此在知识密集型任务上,其性能落后于特定任务的架构。 此外,为决策提供依据并更新世界知识仍然是一个悬而未决的研究问题。
迄今为止,对显式非参数内存具备可微分访问机制的预训练模型,仅针对提取的下游任务而做过研究。 该文探索一种用于检索增强生成(RAG)的通用微调方法,结合预训练的参数化和非参数化内存来生成语言。 本文引入 RAG 模型,其中参数存储器是预训练的 seq2seq 模型,非参数存储器是维基百科的致密向量索引(DPR),可通过预训练的神经检索器访问。 比较两种 RAG 公式,一种以整个生成序列中相同的检索段落为条件,另一种每个token采用不同的段落。 在广泛的知识密集型 NLP 任务上微调和评估模型,并在三个开放域 QA 任务上设置最先进的技术,优于参数化 seq2seq 模型和特定任务的检索-和-提取架构。 对于语言生成任务, RAG 模型比最先进的纯参数 seq2seq 基线方法,生成更具体、更多样化和更真实的语言。
RAG 模型用输入序列 x 来检索文本文档 z 并在生成目标序列 y 时将它们用作附加上下文。 模型利用两个组件:(i) 一个检索器 pη(z|x),其参数 η 返回给定查询 x 的文本段落(前- K 截断)分布;(ii) θ 参数化的生成器 pθ( yi|x, z, y1:i−1) ,根据前 i − 1 个token y(1:i−1)、原始输入 x 和检索段落 z 的上下文,生成当前token。
为了端到端地训练检索器和生成器,将检索文档视为潜变量。 该文提出两种模型,以不同的方式边际化潜文档,产生生成文本的分布。 一种方法,RAG-Sequence,用相同的文档来预测每个目标token。 第二种方法,RAG-Token,可以根据不同的文档预测每个目标token。
如图所示:将预训练的检索器(查询编码器 + 文档索引)与预训练的 seq2seq 模型(生成器)相结合,并进行端到端微调。 对于查询 x,用最大内积搜索 (MIPS) 来查找前 K 个文档 zi。 对于最终预测 y,将 z 视为潜变量,给定不同的文档边际化 seq2seq 预测。
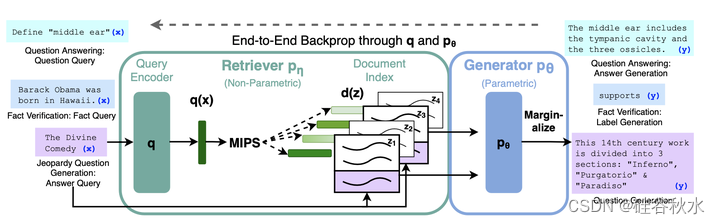
RAG-Sequence 模型使用相同的检索文档来生成完整序列。从技术上讲,它将检索的文档视为单个潜变量,该变量被边际化,通过 top-K 近似获得 seq2seq 概率 p(y|x)。具体来说,使用检索器检索前 K 个文档,生成器为每个文档生成输出序列概率,然后将其边际化。
在 RAG-Token 模型中,可以为每个目标 token 绘制不同的潜文档并相应地进行边际化。这允许生成器在生成答案时从多个文档中选择内容。具体来说,使用检索器检索前 K 个文档,然后生成器为每个文档的下一个输出 token 生成分布,然后进行边际化,并重复该过程输出token。
将目标类视为长度为 1 的目标序列,RAG 可用于序列分类任务,在这种情况下,RAG-Sequence 和 RAG-Token 是等效的。
检索器基于DPR【26】,一个双-编码器架构(文本和查询)。用来自 DPR 的预训练双编码器来初始化检索器并构建文档索引。该检索器经过训练,可检索包含 TriviaQA [24] 问题和 Natural Questions [29] 答案的文档。将文档索引称为非参数记忆。
生成器可以是任意编码-解码结构。可以采用 BART-large [32],一个经过预训练的 seq2seq Transformer [58],具有 400M 个参数。为了在从 BART 生成时将输入 x 与检索的内容 z 结合起来,只需将它们连接起来即可。BART 使用去噪目标(objective)函数和各种不同的噪声函数进行预训练。它在一系列不同的生成任务上获得最先进的结果,并且优于同等大小的 T5 模型 [32]。从此以后,将 BART 生成器参数 θ 称为参数记忆。
联合训练检索器和生成器组件,无需对应该检索哪个文档直接监督。给定一个输入/输出对 (xj , yj ) 的微调训练语料库,用 Adam 的随机 j 梯度下降法最小化每个目标的负边际对数似然 sum(−logp(yj|xj))[28]。在训练期间更新文档编码器 BERT 的成本很高,因为它需要定期更新文档索引,就像 REALM 在预训练期间所做的那样 [20]。这一步对于实现强劲的性能来说不是必要的,并且保持文档编码器(和索引)固定,只微调查询编码器 BERT 和 BART 生成器。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









