









24年6月来自杭州心识公司(Mindverse AI)发表的论文“AI-native Memory: A Pathway from LLMs Towards AGI”。
大语言模型(LLM)已经向世界展示了通用人工智能(AGI)的光芒。一种观点,尤其是来自一些从事LLM的初创公司观点,认为具有几乎无限上下文长度的LLM可以实现AGI。然而,他们可能对(现有)LLM的长上下文能力过于乐观。最近的文献表明,各个公司LLM的有效上下文长度明显小于其声称的上下文长度。另外,大海捞针实验进一步表明,同时从长上下文中找到相关信息并进行(简单)推理几乎是不可能的。
本文设想一条通过整合记忆从LLM到AGI的途径。AGI应该是一个以LLM为核处理器的系统。除了原始数据外,该系统的记忆还将存储大量从推理过程中得出的重要结论。与仅仅处理原始数据的检索增强生成 (RAG) 相比,这种方法不仅将语义相关的信息联系得更紧密,而且简化了查询时的复杂推理。作为中间阶段,记忆将很可能以自然语言描述的形式存在,用户也可以直接使用。最终,每个智体/人都应该拥有自己的大型个人模型,一个深度神经网络模型(因此AI -原生),它可以参数化和压缩所有类型的记忆,甚至那些无法用自然语言描述的记忆。
AI -原生记忆具备 AGI 时代作为(主动)参与、个性化、分发和社交变革性基础设施的潜力,由此带来隐私和安全挑战。
大语言模型 (LLM)有OpenAI 的 GPT 系列(Brown,2020;Ouyang,2022;Achiam,2023)、谷歌的 Gemini 系列(Team,2023;Reid,2024;Team,2024)、Anthropic 的 Claude 系列(Anthropic,2024)、Meta 的 Llama 系列(Touvron,2023a、b)以及 Mistral 的 Mixtral 系列(Jiang,2023、2024)。
原始 GPT-4 的上下文窗口为 32K 个 token(Achiam,2023),最新的 GPT-4-turbo 和 GPT-4o 模型可以处理 128K 个 token;Gemini 1.5 声称上下文窗口为 1M 或 10M 个 token(Reid,2024)。来自从事 LLM 的初创公司的人,认为具有超长甚至无限上下文的 LLM 可以通过将所有原始数据放入上下文中并完全依赖 LLM 一步完成所有必要的推理以获得每个查询的最终结果来实现 AGI。
与人类的认知负荷(Sweller,1988)类似,LLM 能够处理的最大内容量可能本质上受限于它们正在执行的任务。然而,之前对长上下文模型的大多数评估都是基于困惑度或简单的合成检索任务,而忽略了其在更复杂任务上的有效性。根据最近对更复杂任务的基准测试(Hsieh,2024),大多数(如果不是全部)LLM 都夸大了它们的上下文长度。例如,GPT-4 模型声称具有 128K 的上下文,但有效上下文只有 64K;另一个声称具有 128K 上下文的模型 ChatGLM(Zeng,2023a;Du,2022)最终只有 4K。大海捞针的基准,在LLM的评估,证明了同时从长上下文中找到相关信息并进行推理几乎是不可能的。
AGI 应该是一个系统,其中 LLM 更像处理器,而 LLM 的上下文就像 RAM。仅使用处理器和 RAM 甚至不足以用于计算机,也不足以用于 AGI。要完成这个系统,至少需要(长期)内存,它起着磁盘存储的作用。
检索增强的 LLM 可以筛选大量相关上下文来回答查询(Kocˇisky` ,2018 ;Dasigi ,2021 ;Pang ,2022 ;Trivedi ,2022),在这里可以被视为一种特殊情况,因为它将记忆定义为原始数据。然而,记忆超越了原始数据,因为它应该被生成和组织,包括许多需要从原始数据中推理的结果。除了下游应用程序之外,记忆还应该能够被用户直接使用。
在认识到记忆的必要性之后,再说记忆的形式以及记忆和 LLM 的交互(例如,将正确的数据从“磁盘”加载到“RAM”)。作为中间阶段,记忆很可能以自然语言描述的形式出现。这与许多现有的信息提取和知识发现工作一致,为每个智体/人构建一个“记忆宫殿”。
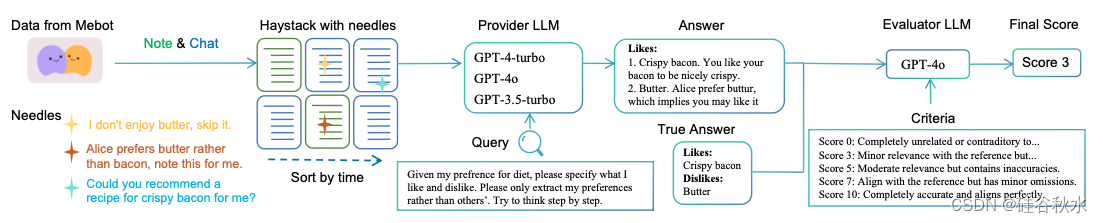
设计一种新的大海捞针任务,旨在验证 LLM 在同时需要检索和推理时的能力。如图显示了大海捞针评估流程的概览。大海捞针、针和查询都是在用户许可下基于 Mindverse AI 的 Mebot 真实数据和场景设计的。大海捞针通常是一系列按时间顺序链接的用户-Mebot 交互。针-查询对,是针对某些推荐场景构建的。Mebot 是基于 LLM 的“第二个我”产品。它为每个用户创建可应用于各种场景的个性化模型。具体来说,它强调在确保隐私和安全的同时组织用户的记忆,并根据这些记忆提供个性化的服务和灵感。
AGI 应该是一个像计算机一样的系统,其中 LLM 就像处理器,LLM 的上下文就像 RAM。要完成这个系统,必须有(长期)记忆作为磁盘存储。
RALM/RAG 是记忆的基本版本。检索增强型 LLM (RALM) 筛选大量相关上下文来回答查询(Kocˇisky` ,2018 ;Dasigi ,2021 ;Pang ,2022 ;Trivedi ,2022 ),可以被视为一种特殊情况,因为它将记忆仅定义为原始数据。虽然有些人想利用 RALM 来实现 AGI,但这些方法的主要出发点是解决 LLM 缺乏域知识的问题。因此,这些方法旨在解决 LLM 本身支持的长上下文不够长问题。如前所述,仅依靠 LLM 本身的超长上下文无法实现 AGI。所以 RALM/RAG 也行不通。
记忆超越原始数据,因为它应该被生成和组织,包括许多需要从原始数据中推理的结果。除了下游应用程序之外,记忆还应该能够被用户直接使用。
什么是 AI-原生记忆?其最终形式是一种深度神经网络模型(因此是 AI-原生),它可以参数化和压缩所有类型的记忆,即使是那些无法用自然语言描述的记忆。为了确保与同一个 AGI 智体交互的不同用户之间记忆隐私,最佳做法是为每个单独的用户维护一个记忆模型。因此,将 AGI 智体和特定用户之间的这种记忆模型称为该用户的大型个人模型 (LPM)。 LPM 记录、组织、索引和整理个人的每一个细节,最终为用户提供直接访问记忆的接口,并为下游应用(如个性化生成、推荐等)提供有用、完整的上下文。从某种意义上说,LPM 充当了升级版的“检索增强”角色。它的优越性在于通过广泛的“推理”(即组织、索引等)对原始数据进行转换,而不仅仅是记录。注意,LPM 会随着用户与 LPM 的交互而进化,形成一个数据飞轮。
设计 LPM 实现的三个级别,如下所示,复杂性逐渐增加:
L0:原始数据。此方法类似于直接将 RALM/RAG 应用于原始数据,将记忆定义为所有原始数据。
L1:自然语言记忆。是指可以总结为自然语言形式的记忆,例如用户的简短简历、重要句子或短语列表以及偏好标签。
L2:AI -原生记忆。是指不一定需要用自然语言描述的记忆,通过模型参数进行学习和组织。每个 LPM 都将是一个神经网络模型。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









