










23年9月25号的一篇博客网文“Add your own data to an LLM using Retrieval-Augmented Generation (RAG)“:作者Bea Stollnitz是住在西雅图的一个微软工程师。
网址:bea.stollnitz.com/blog/rag/
引言
大语言模型(LLM)对世界了解很多,但他们并不了解一切。 由于训练这些模型需要很长时间,因此它们上次训练的数据可能相当旧。 尽管LLM知道互联网上可用的通用事实,但不知道专有数据,而后者通常是基于人工智能的应用程序中需要的数据。 因此,利用新数据扩展LLM最近成为学术界和工业界的一个相当大的关注领域也就不足为奇了。
在大语言模型的新时代到来之前,通常会通过简单地微调模型来使用新数据扩展模型。 但现在的模型更大并且已经接受了更多数据的训练,微调仅适用于少数场景。 当想让LLM以不同的风格或语气进行交流时,微调效果特别好。 微调的一个很好的例子是 OpenAI 将其较旧的生成 GPT-3.5 模型改为聊天版 GPT-3.5-turbo (ChatGPT) 模型。
然而,在向大模型添加新数据时,微调的效果并不好,这是一种更常见的业务场景。 此外,微调 LLM 需要大量高质量数据、用于计算资源的大量预算以及大量时间——所有这些对于大多数用户来说都是稀缺资源。
该博文介绍一种称为“检索增强生成”(RAG)的替代技术。 这种方法基于提示,由 Facebook AI Research (FAIR) 2021 年引入。RAG 概念非常强大,Bing 搜索和其他高流量网站都用它来将当前数据合并到模型中。 当没有大量新数据、大量预算或大量时间时,这个微调方法也很有效。
与博文相关的GitHub 存储库中可以找到简单 RAG 场景的三种代码实现:一种直接使用 OpenAI API,另一种使用开源 LangChain API,第三种实现使用微软开源的Semantic Kernel API。
RAG概述
检索增强生成的实现可能有所不同,但在概念层面上,基于 AI 的应用程序使用 RAG 要涉及以下步骤:
用户输入问题。
系统搜索可能回答该问题的相关文档。 这些文档通常由专有数据组成,并存储在某种文档索引中。
系统创建一个 LLM 提示,其中结合了用户输入、相关文档以及 LLM 用提供文档回答用户问题的说明。
系统将提示发送给 LLM。
LLM根据提供的上下文返回用户问题的答案。 这是最后系统的输出。
如图是这个总体想法示意图:
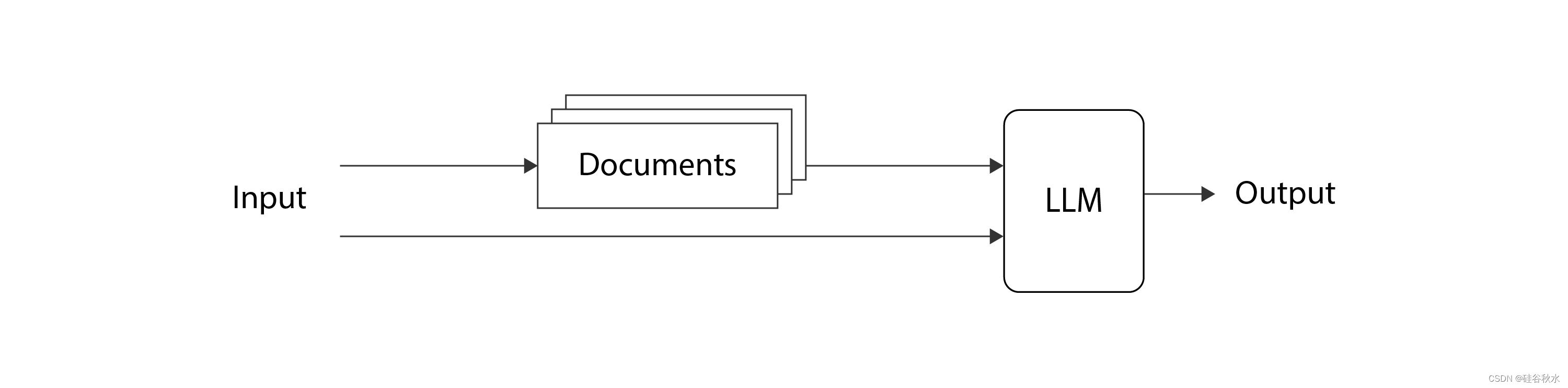
最原创的论文来自“Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks”
其论文展示的架构如下图所示:
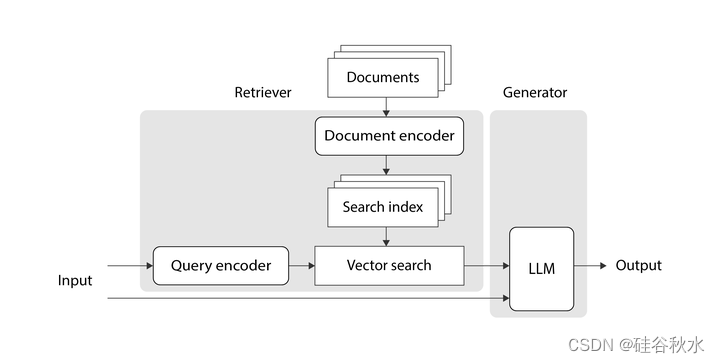
在高层次上,所提出的结构由两个组件组成:检索器和生成器。 检索器组件使用查询编码器将输入文本转换为浮点数(向量)序列,使用文档编码器以相同的方式转换每个文档,并将文档编码存储在搜索索引中。 然后,它在搜索索引中搜索与输入向量相关的文档向量,将文档向量转换回文本,并将其文本作为输出返回。 然后,生成器获取用户输入的文本和匹配的文档,将它们组合成提示,并要求LLM根据文档中的信息回复用户的输入。 该LLM的输出就是系统输出。
查询编码器、文档编码器和 LLM 在上图中都以类似的方式表示 - 这是因为它们都是用 Transformer 实现的。 传统的 Transformer 由两部分组成:编码器和解码器。 编码器负责将输入文本转换为大致捕获单词含义的向量(或向量序列); 解码器负责根据输入文本生成新文本。 本文的架构中,查询编码器和文档编码器是使用仅编码器Transformer实现的,因为它们只需要将文本片段转换为数字向量。 生成器中的 LLM 是使用传统的编码器-解码器Transformer来实现的。
这个架构是如何训练的? 该论文提出用预训练的 Transformer,并仅联合地微调查询编码器和生成器 LLM。 这种微调是用成对的用户输入和LLM期望的相应输出来完成的。 文档编码器没有进行微调,因为这样做成本高昂,而且作者发现这并不必需。
该论文提出了两种实现该架构的方法:
RAG-序列 :检索 k 个文档,并用它们生成回答用户查询的所有输出token。
RAG-token:检索 k 个文档,用它们生成下一个token,然后检索更多 k 个文档,用它们生成下一个token,依此类推。 这意味着最终可能会在生成用户查询的单个答案时检索多个不同的文档集。
RAG的工业应用
在实践中,业界常见的 RAG 实现已根据本文进行了以下修改:
在本文提出的两种方法中,RAG-序列实现几乎一直在业界使用。 与其他替代方案相比,它更便宜、更简单,而且效果很好。
通常不会微调任何Transformer。 如今,可以用经过预训练的LLM,足以按原样使用,但进行微调的成本太高。
此外,搜索文档的方法并不总是完全按照论文提出的方法进行。 搜索通常是在搜索服务(例如 FAISS 或 Azure Cognitive Search)的帮助下完成的,这些服务支持与 RAG 完美搭配的不同搜索技术。
一个搜索服务一般由以下两个执行步骤组成:
检索:此步骤将用户的查询与搜索索引中的文档进行比较,并检索最相关的文档。 常见的检索技术有三种:关键词搜索、向量搜索和混合搜索。
排名:这是检索之后的可选步骤。 它获取通过检索发现相关的文档列表,并改进它们的排名顺序。
关键词搜索
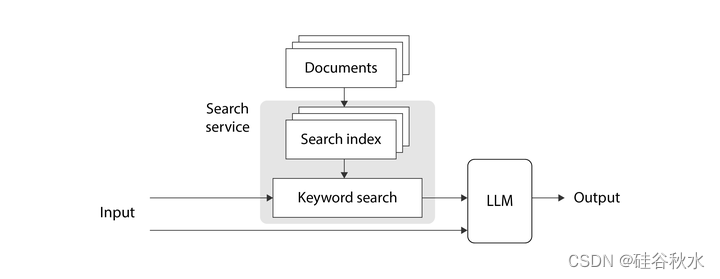
查找与用户查询相关的文档的最简单方法是进行“关键字搜索”(也称为“全文搜索”)。 关键字搜索把用户输入文本中的确切术语送入索引中搜索具有匹配文本的文档。 匹配仅基于文本完成,不涉及向量。 尽管这种技术已经存在了一段时间,但它在今天仍然具有现实意义。 当您搜索用户 ID、产品代码、地址以及任何其他需要高精度匹配的数据时,这种类型的搜索非常有用。 如图是此实现的高级示意图:
带关键字搜索的 RAG 图
在这种情况下,搜索服务保留一个倒排索引(inverted indexing),将单词映射到使用这些单词的文档。 用户的文本输入被解析以提取搜索术语,并进行分析以查找这些术语的标准形式。 然后扫描倒排索引查找搜索词,对每个匹配进行评分,并从搜索服务返回最相关的匹配文档。
向量搜索
“向量搜索”(也称为“密集检索”)与关键字搜索的不同之处在于,当文档中不存在搜索词时,它还可以找到匹配项,但总体思路是相似的。 例如,假设正在构建一个聊天机器人来支持房产租赁网站。 如果用户问:“有推荐靠近大海的宽敞公寓吗?” 并且特定属性的文档包含文本“4000 sq ft home with ocean view”,关键字搜索不会将其识别为匹配项,但向量搜索会。 在非结构化文本中搜索通用想法而不是精确的关键字时,向量搜索效果最好。
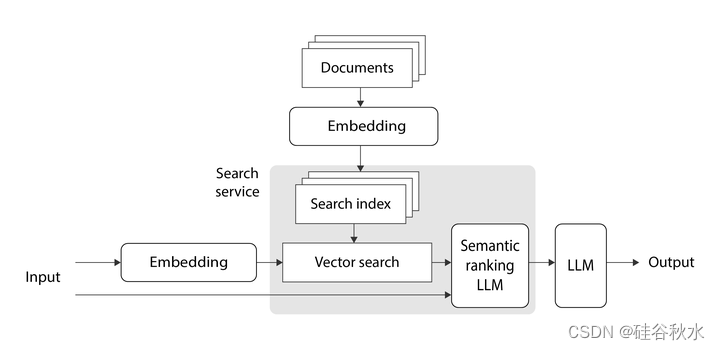
如图是 RAG 与向量搜索的高级概述。业界使用的向量搜索与 RAG 论文的做法几乎相同。 但这种情况下不对Transformer进行微调。
通常用预训练的嵌入模型,例如 OpenAI 的 text-embedding-ada-002,来对查询和文档进行编码,并用预训练的 LLM,例如 OpenAI 的 gpt-35-turbo (ChatGPT),来生成最终输出。 嵌入模型用于将输入文本和每个文档转换为相应的“嵌入”。 什么是嵌入? 它是一个浮点数向量,大致捕获编码文本的一般概念。 如果两段文本相关,那么可以假设相应的嵌入向量是相似的。
为了找到给定输入向量的顶级文档向量,搜索服务可以简单地使用暴力计算输入向量和每个文档向量之间的相似度,然后选择顶级匹配。 然而,这种简单的算法无法扩展到有大量文档向量的大型企业应用程序。 因此,搜索服务通常用某种类型的近似最近邻(ANN)算法,该算法使用巧妙的优化在更短的时间内给出近似结果。 ANN 的一种流行实现是“分层的可导航小世界 ”(HNSW) 算法。
混合搜索
混合搜索包括同时使用关键字和向量搜索。 例如这样一个场景:有一个客户 ID 和一个文本输入查询,并且想要进行一次搜索,以捕获客户 ID 的高精度和用户文本的一般含义。 这是混合搜索的完美场景。 混合搜索分别执行两种类型的搜索,然后每种技术最佳结果的算法组合产生输出。 这种方法在工业界经常使用,特别是在更复杂的应用。
语义排名
语义排名(也称为“重排名”)是文档检索之后的一个可选步骤。 检索步骤会尽力根据返回文档与用户查询的相关程度对它们进行排名,但语义排名通常可以改进该结果。它用检索返回的文档子集,以及专为该任务训练的 LLM,去计算更高质量的相关性分数,并根据这些分数对文档重排名。
如图显示了语义排名与向量搜索的结合,但也可以轻松地将其与关键字搜索结合。
结论
该博客介绍了用自定义数据扩展预训练的 LLM 的 RAG 模式。 讨论了首次引入 RAG 概念的研究论文、它如何适应行业、以及通常与其结合使用的不同搜索技术。















 935
935

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









