










24年4月来自加拿大UBC、微软和Hippocratic AI的论文“Hybrid LLM: Cost-Efficient and Quality-Aware Query Routing”。
大语言模型 (LLM) 在大多数 NLP 任务中表现出色,但由于其规模较大,需要昂贵的云服务器进行部署,而可以部署在成本较低(例如边缘)设备上的小型模型往往在响应质量方面落后。这项工作提出一种混合推理方法,结合它们各自的优势以节省成本并保持质量。该方法使用路由器,该路由器根据预测的查询难度和所需的质量水平将查询分配给小型或大型模型。可以根据场景要求在测试时动态调整所需的质量水平,无缝地质量换成本。实验中对大型模型的调用次数减少了多达 40%,而响应质量没有下降。
最近的研究 [Kag et al., 2022, Ding et al., 2022] 引入了一种称为混合推理的新范式,它使用两个不同大小的模型而不是单个模型进行推理。较小的模型(例如 Llama2 [Touvron et al., 2023])通常具有较低的推理成本,但准确度也低于较大的模型(例如 GPT-4 [OpenAI, 2023])。关键思想是识别并将简单查询路由到小模型,以便在保持响应质量的同时降低推理成本。通过调整查询难度的阈值,可以动态地权衡相同推理设置的质量和成本。[Kag et al., 2022] 研究这种图像分类设置,并提出从头开始训练小模型、大模型和路由器。然而,LLM 训练成本高昂,并且针对每种情况从头开始重新训练 LLM 违背使用预训练基础模型进行推理的前提。此外,文本生成 [Iqbal and Qureshi, 2022] 通常比图像分类更模糊、更具挑战性,因此需要新技术来实现有效的混合 LLM 推理以生成文本。
一些近期的研究 [Jiang et al., 2023, Chen et al., 2023, Leviathan et al., 2023, Kim et al., 2023] 使用多个 LLM 进行推理,但这些方法通常会为单个查询调用多个 LLM,这可能会产生大量的计算开销。具体来说,[Jiang et al., 2023] 在推理时调用一组 LLM,因此推理成本将与系统中的模型数量成正比。[Chen et al., 2023] 使用级联 LLM 执行推理,其中级联中的 LLM 依次生成对查询的响应,直到其中一个模型的置信度得分高于预定义的阈值。推测解码[Leviathan et al., 2023, Kim et al., 2023] 通过在“简单”解码步骤上调用小型高效解码器来加速昂贵模型的解码。
随着 LLM 部署的复杂性和成本激增,小公司和个人消费者开始依赖 HuggingFace 和 OpenAI 等平台上托管的现有 LLM。这是更广泛的机器学习即服务 (MLaaS) 范式的一个实例,其中用户(小公司/个人消费者)通过 API 与模型交互,并在其中提交查询 [Kang et al., 2022],但模型本身的可见性有限。在这种情况下,混合推理方法可以降低消费者和平台所有者的成本,因为 a) 消费者可以使用它将简单的查询,路由到托管在其边缘设备(笔记本电脑/智能手机)上的小型模型,并且只调用更复杂的查询 API ;和 b) 平台所有者可以在不影响用户体验的情况下自动将查询路由到后端的低成本模型,只要保持响应质量水平即可。因此,混合推理方法提供了一种灵活且经济高效的解决方案,可充分发挥 LLM 的潜力,同时满足不同的成本预算和质量要求。
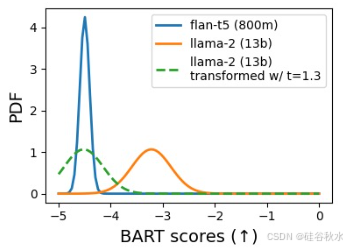
如图所示:路由器将 22% 的查询分配给 Llama-2 (13b) ,以 BART 分数衡量的响应质量下降不到 1% [Yuan et al., 2021]。小模型在响应质量方面更接近大模型时,其收益甚至更高。
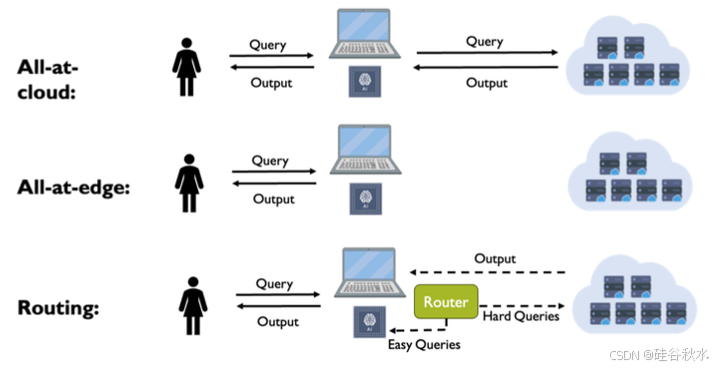
将小型模型的响应质量接近大型模型的响应质量的查询,称为“简单”查询。混合推理框架的目标是识别简单查询并将其路由到小型模型,从而确保在不大幅降低响应质量的情况下显著降低推理成本。请注意,此处定义的简单查询不一定是易于/廉价响应的查询,它们只是小型模型可以与大型模型相匹配的查询。
查询 x 的质量差定义为 H(x) := q(S(x))−q(L(x)),即小模型响应 S(x) 和大模型响应 L(x) 之间的质量差。质量差是一个随机变量,因为 LLM 响应通常是不确定的。下图说明了这一点,其中蓝色和橙色图对应于 FLAN-t5 (800M)[Chung et al., 2022] 和 Llama-2 (13B) [Touvron et al., 2023] 对单个查询的响应分布。
查询使用 BERT 样式的编码器模型(例如 DeBERTa,[He et al., 2020])进行路由,该模型在代表性查询数据集上进行训练并学习预测分数。由于路由器是一个编码器模型,查询通过一次就足以生成分数,假设与使用大型模型[Sun et al., 2019] 运行自回归解码的成本相比,此步骤的成本可以忽略不计。因此,预计使用路由器将查询路由到小型模型不会显著削弱可实现的成本优势。
对于上面定义的简单查询,将路由器得分设计得较大。直观地讲,Pr[H(x) ≥ 0] 的估计值是一个合适的候选值,因为 Pr[H(x) ≥ 0] = Pr[q(S(x)) ≥ q(L(x))] 的大数值,对应于一些查询,其具有一个小模型响应质量至少与大模型一样高的高似然。但是,在大型模型明显比小型模型更强大的场景中,即通常情况下 q(S(x)) << q(L(x)),可以放宽简单查询的定义为 Pr[H(x) ≥ −t] = Pr[q(S(x)) ≥ q(L(x)) − t](其中 t > 0)来训练更有效的路由器。在测试时,调整分数阈值并将分数高于阈值的查询路由到小模型,实现所需的性能准确性权衡。对于具有参数 w 的路由器,用 pw(x) 表示路由器分数,pw : X → [0,1]。
确定路由器
先前关于混合 ML 的研究 [Ding et al., 2022, Kag et al., 2022] 假设神经模型是确定性函数,可将输入特征映射到输出空间中的单个点。为了在 LLM 中实现这一点,从每个模型中为每个查询采样一个响应。为每个训练查询分配布尔标签 yidet = 1[q(S(xi)) ≥ q(L(xi))], i = 1, . . . , N,并将 BART分数作为质量函数 q(.)。一个路由器训练是最小化如下目标:
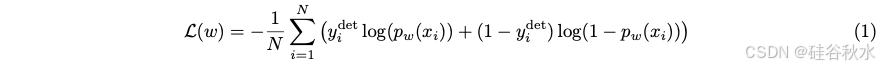
分配的标签 yidet 可以看作是 Pr[H(xi) ≥ 0] 的估计值,给定每个模型对每个查询的一个响应,因此最小化上述损失会促使路由器得分 pw(x) 接近对测试查询的 Pr[H(x) ≥ 0]。这种确定性路由器称为 rdet。
概率路由器
对于真值标签通常明确且唯一的任务,例如图像分类 [Masana et al., 2022] 和视频分割 [Yao et al., 2020],确定性假设是合理的。然而,当涉及到 NLP 任务时,由于自然语言的内在模糊性和复杂性,通常没有单一的最佳答案。LLM 被广泛用作非确定性生成器来捕获 NLP 任务的内在不确定性。非确定性主要来自解码阶段的随机性。用户通常通过选择不同的解码策略(例如核 nucleus 采样 [Holtzman et al., 2019])以及超参温度值,来控制不确定性水平。直观地说,温度值越高,生成响应的随机性和多样性就越高。对于 GPT-4 等黑盒子 LLM API [OpenAI,2023],即使温度设置为最小值 0,它仍然可以为相同的输入查询提供不同的响应。底层机制仍是一个悬而未决的问题,而最近的一项研究暗示 MoE 主干的不稳定性 [Skyward,2023]。 一个概率路由器rprob是最小化如下目标函数:
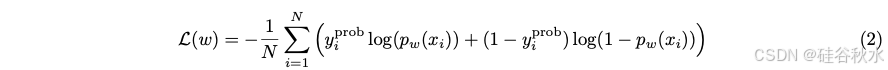
数据转换的概率路由器
当大模型比小模型强大得多时,Pr[H(xi) ≥ 0] = E[1[q(S(xi)) ≥ q(L(xi))]] 的经验估计趋于极小。因为在这种情况下大多数查询 q(S(x)) << q(L(x)),rdet 和 rprob 都无法比随机查询分配提供太大改进。
传统的不平衡数据学习方法,有其自身的缺点 [Krawczyk,2016]。此外,目标是只设计一个可以降低推理成本同时尽可能保持响应质量的路由器,因此不限于类标签的特定定义实现此目标。利用这种灵活性引入新标签 yitrans(t) := Pr[H(xi) ≥ −t] = Pr[q(S(xi)) > q(L(xi)) − t],其中 t > 0。由于 −t < 0,根据尾部分布的定义,Pr[H(x) ≥ −t] ≥ Pr[H(x) ≥ 0],因此期望这种松弛为路由器训练提供更强的信号,同时仍然识别简单的查询,即 q(S(x)) 很可能接近 q(L(x)) 的查询 (q(S(x)) > q(L(x)) − t)。视觉上看,这相当于将对查询的小模型响应分布与大模型响应的偏移分布进行比较。
现在的问题是如何选择最佳松弛 t?鉴于尾部概率 Pr[H(x) ≥ −t] 位于 [0, 1] 之间,最大化转换标签之间的平均成对差异来选择 t,将它们推得尽可能远,并为训练提供强信号。最佳t定义为
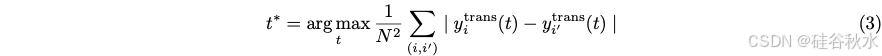
通过网格搜索解决上述优化问题。变换的标签 yitrans(t∗) 分布,明显更加平衡,预计最终的路由器将更加有效。再次,通过最小化损失来训练路由器 rtrans:
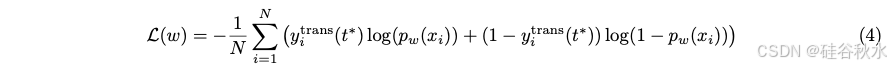


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









