










2018年CVPR来自MIT、McGill U、U Ljubljana 和 U Toronto 的论文“VirtualHome: Simulating Household Activities via Programs”。
感兴趣的是模拟典型家庭中发生的复杂活动。使用程序(即原子动作和交互序列)作为复杂任务的高级表示。程序之所以有趣,是因为它们提供了任务的非歧义表示,并允许智体执行。但是,如今没有数据库提供此类信息。为了实现这一目标,首先通过用于教孩子如何编码的游戏式界面,众包各种发生在人们家中的活动的程序。使用收集的数据集,展示了如何学习直接从自然语言描述或视频中提取程序。然后,在 Unity3D 游戏引擎中实现最常见的原子(交互)动作,并使用程序“驱动” AI 智体在模拟家庭环境中执行任务。VirtualHome 模拟器能够创建具有丰富事实的大型活动视频数据集,从而能够训练和测试视频理解模型。最后介绍智体根据语言描述在 VirtualHome 中执行任务的示例。
目标是建立一个大型的存储库,其中包含在日常生活中在家中执行的常见活动和任务。这些任务可以包括简单的操作,例如“打开电视”,也可以包括复杂的操作,例如“煮咖啡加牛奶”。兴趣在于为机器人收集这些信息。与人类不同,机器人需要更直接的指令。例如,为了“看电视”,人们可能会将其(对人类)描述为“打开电视,坐在沙发上看”。这里,“拿起遥控器”和“坐在/躺在沙发上”这些动作被省略了,因为它们是人类拥有的常识知识的一部分。
在工作中,目标是收集机器人成功执行任务所需的所有步骤,包括常识步骤。特别是,希望收集完整描述活动的程序。将动作描述为程序的优点,是它提供了完成任务所需所有步骤清晰且无歧义的描述。然后,这些程序可用于指导机器人或虚拟角色。程序还可用来表示涉及许多简单操作的复杂任务,从而提供一种理解和比较活动和目标的方法。
如图所示:首先众包一个大型的家务知识库(顶部)。每个任务都有一个高级名称和一个自然语言指令。然后,收集这些任务的“程序”(中间左侧),标注者将指令“翻译”成简单的代码。在一个名为 VirtualHouse 的 3D 模拟器中实现最频繁的(交互)操作,能够驱动智体执行程序定义的任务。从文本(顶部)和视频(底部)自动生成程序,从而通过语言和视频演示来驱动智体。

使用程序来表示活动的主要动机,是让机器人执行这些程序来“驱动”机器人执行任务。作为智体,使用程序在模拟的 3D 环境中驱动角色。模拟很有用,因为它们为“机器人”定义了一个游乐场,一个可以教人工智体执行任务的环境。这里专注于构建模拟器,而不是模拟器内部的学习。特别是,假设智体可以访问有关环境的所有 3D 和语义信息,以及手动定义的动作视频。重点是表明程序代表了一种指导此类智体的好方法。此外,模拟器允许生成丰富多样复杂活动的大规模视频数据集。可以简单地记录智体在模拟器中执行程序来创建数据集。然后,模拟器提供密集的真值信息,例如语义分割、深度、姿势等。
如图所示:VirtualHome 活动数据集是使用模拟器创建的复合活动视频数据集。首先使用简单的概率语法生成程序。通过随机选择房屋、智体、摄像头以及目标子集的位置、智体的初始位置、操作速度和交互目标的选择,为 VirtualHome 中的每个程序制作活动视频。每个程序都会显示给标注者,标注者需要用自然语言描述它(上行)。视频有基本事实:(第二行)每个原子动作的时间戳、(底部)2D 和 3D 姿势、类和目标实例分割、深度和光流。

用 Unity3D 游戏引擎实现 VirtualHome 模拟器,该引擎允许利用其运动学、物理和导航模型,以及通过 Unity 的 Assets 商店提供的 3D 模型。从网上获得 6 套带家具的房屋和 4 个装配好的类人模型。平均而言,每个家庭包含 357 个目标实例(每个房间 86 个)。通过 3D 仓库从另外 30 个目标类中收集目标,这些目标出现在收集的程序中,但在整个包中不可用。每个类别收集至少 3 个不同的模型。房屋和智体如图所示。


目标是从自然语言描述或视频演示中为该活动生成一个程序。将输入(描述或视频)转录成程序的任务,视为翻译问题。调整 seq2seq 模型 [23],并使用模拟器奖励的强化学习对其进行训练。
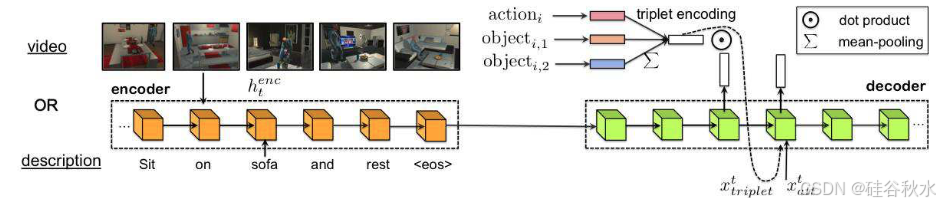
该模型由一个 RNN 编码器和另一个 RNN 组成,前者将输入序列编码为隐藏向量表示,后者充当解码器,一次生成程序的一个步骤。用具有 100 维隐状态的 LSTM 作为编码器。整个模型示意图如图所示:
训练分两步。
首先,在 RNN 解码器的每个时间步中使用交叉熵损失对模型进行预训练。遵循典型的训练策略,即在每个时间实例上进行预测,但将真实值输入到下一个时间实例中。
在第二步,将程序生成视为强化学习问题,其中智体学习生成编写程序步骤的策略。遵循 [18],用策略梯度优化来训练模型,使用贪婪策略作为基线估计器。
为了从视频生成程序,将每个视频分成 2 秒的片段,并训练一个模型预测中间帧的步。用 DilatedNet 获得每帧的语义分割,并使用具有 4 帧关系的时间关系网络 (TRN)[27] 来预测指令的嵌入(动作 + 目标 + 主题)。用此嵌入来获得每个指令的似然。每个片段的预测用作 RNN 编码器的输入以生成程序。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









