










24年7月来自上海AI实验室、浙江大学、上海交大、清华大学、南京大学、香港中文大学和西安电子科大的论文“GRUtopia: Dream General Robots in a City at Scale”。
最近的研究一直在探索具身智能领域的扩展规律。鉴于收集现实世界数据的成本高昂,模拟-到-现实 (Sim2Real) 范式是扩展具身模型学习的关键一步。 GRUtopia ,是一个为各种机器人设计的模拟交互式 3D 社会。它具有几个进步:(a) 场景数据集 GRScenes 包括 100k 个交互式、精细注释的场景,可以自由组合到城市规模的环境中。与以前主要关注家庭的作品相比,GRScenes 涵盖了 89 个不同的场景类别,弥补了通用机器人最初部署的面向服务环境之间的差距。(b) GRResidents,一个大语言模型 (LLM) 驱动的非玩家角色 (NPC) 系统,负责社交互动、任务生成和任务分配,从而模拟具身智能应用的社交场景。 (c)基准 GRBench 支持各种机器人,但主要关注腿式机器人作为主要智体,并提出涉及目标定位导航、社交定位导航和定位操作的中等挑战性任务。
GRUtopia的主要特征如图所示:

规模化定律在 NLP 和 CV 中取得了重大成功,激发了机器人社区探索其在机器人学习中的形式。一种直接的方法是收集现实世界的机器人动作轨迹,例如最近在 Open X-Embodiment [51] 和 DROID [26] 中的努力。然而,这种尝试在数据收集成本和跨不同硬件平台的泛化问题方面带来了持续的挑战。模拟仿真是解决这些问题的关键一步。先前的研究已经证明学习特定低层策略的可能性,例如 Legged Gym [23, 45]、ManiSkill [22] 和 Orbit [38]。许多研究已经探索在模拟中的具身智能 [31, 21, 48, 1]。然而,现有平台在两个关键方面表现出有限的多样性和复杂性:场景和任务,因此难以满足实现策略泛化的需求。
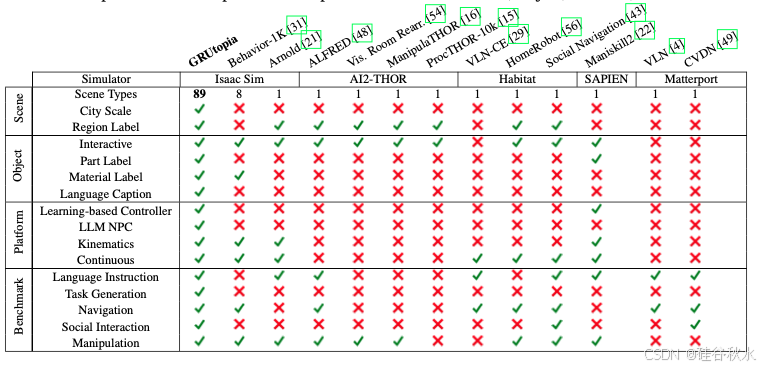
如图是 GRUtopia 和其他平台在场景、目标、平台和基准的比较:
如图所示 GRScenes 中场景和目标的丰富性和多样性。(a)场景分布以细粒度显示。GRScenes 涵盖了广泛的功能场景类别。(b)GRScenes 中存在的注释目标范围和一些示例。
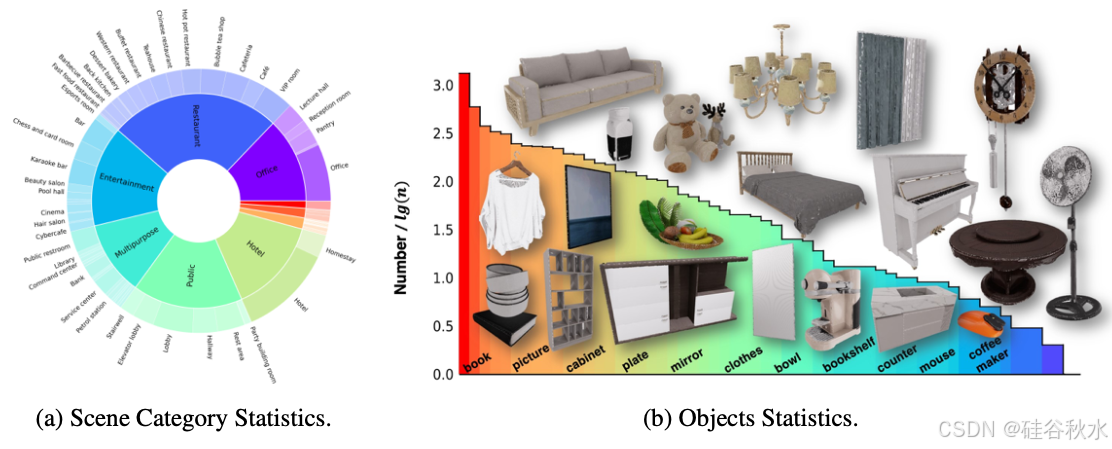
要构建一个用于训练和基准测试具身智体的平台,具有多样化场景和目标资产的完全交互环境是必不可少的。因此,收集一个具有多样化目标资产的大规模 3D 合成场景数据集,作为 GRUtopia 平台的基础。
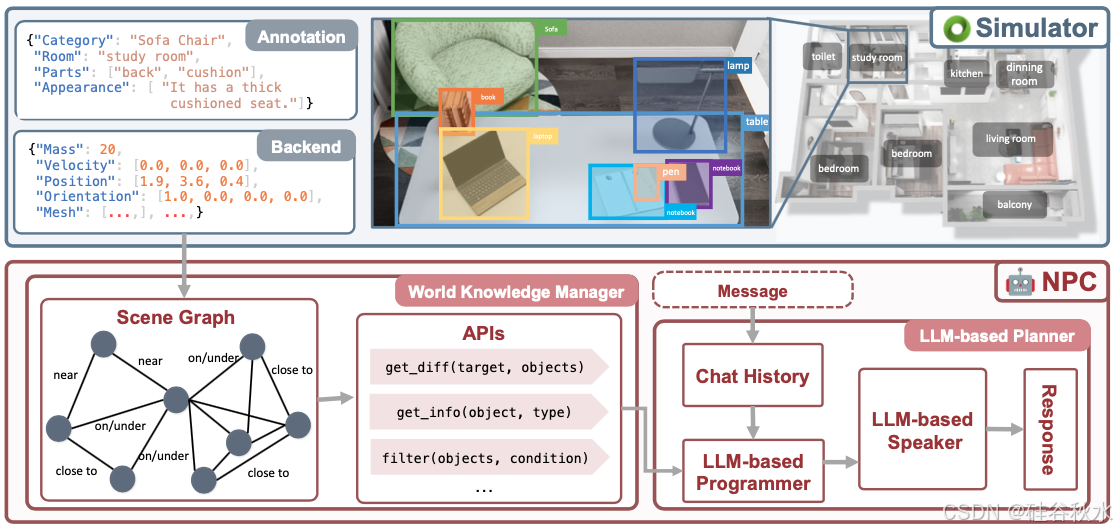
在 GRUtopia 中,我们通过嵌入一些“居民(residents)”,即由 LLM 驱动的生成式 NPC,为世界赋予社交能力,从而模拟城市环境中的社交互动。这个 NPC 系统被命名为 GRResidents。在 3D 场景中构建真实的虚拟角色的主要挑战之一是融入 3D 感知的能力。然而,虚拟角色可以轻松访问场景注释和模拟世界的内部状态,从而实现鲁棒的感知。为此,设计一个世界知识管理器 (WKM),它管理实时世界状态的动态知识,并通过一系列数据接口提供访问。借助 WKM,NPC 可以通过参数化的函数调用检索所需知识并进行细粒度的目标定位,这构成了其感知能力的核心。
如图所示GRResidents 概述。它包含两个模块:(a)世界知识管理器WKM,它从数据集注释和模拟器后端组织场景知识并提供用于知识检索的 API。(b)LLM 规划器,能够从世界知识管理器检索全局知识并根据对话上下文生成响应。
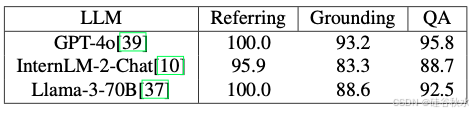
如下图所示,在引用实验中,采用人在环评估。NPC 随机选择一个目标并对其进行描述,然后人类标注者根据描述选择一个目标。如果人类标注者能够根据描述找到正确的目标,则引用成功。在落地实验中,人类标注者的角色由 GPT-4o[39] 扮演,它提供目标描述,然后 NPC 对其进行定位。如果 NPC 能够找到相应的目标,则落地成功。
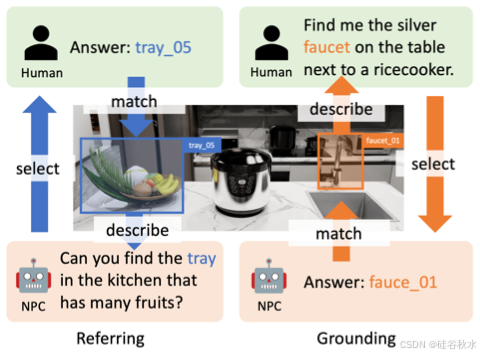
下表(引用和落地)中的成功率显示,不同的 LLM 分别达到 95.9%-100% 和 83.3%-93.2% 的准确率,验证了 NPC 框架在跨 LLM 目标引用和落地方面的准确性。
由于物理模拟需要处理碰撞,因此低级控制 API 对于管理模拟器中的机器人智体至关重要。与之前使用动画和设置位置来执行伪动作的工作不同,将基于 RL 的控制器作为驱动机器人的 API。这种方法利用预训练的、强大的低级控制系统,促进了智体算法在执行高级任务中的部署。具体来说,根据策略学习实践 [34, 33] 开发并提供运动策略作为 API,这些策略适用于各种机器人,包括人形机器人(Unitree H1、Unitree G1、Fourier GR-1)和四足机器人(Unitree Aliengo 和 Unitree Z1 Arm)。这些运动 API 经过精心设计,易于使用,使研究人员和开发人员能够集成复杂的控制机制,无需深入研究 RL 训练的复杂性。
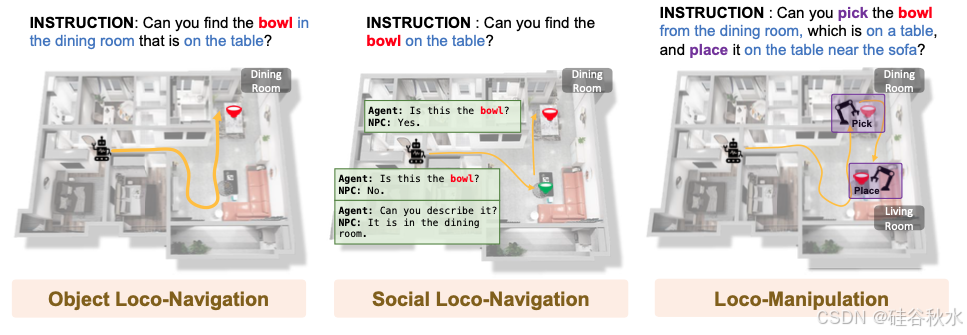
具身智体需要主动感知周围环境,通过对话来澄清模糊的人类指令,并与周围环境互动以完成任务。
如图所示,展示一些示例案例,为综合评估具身智体设置了三个基准:1) 目标定位导航,用于评估主动感知和导航;2) 社交定位导航,用于评估与 NPC 的有效沟通以澄清指令;3) 定位操作,用于测量移动操作。为每个基准生成 300 个情节(100 个用于验证,200 个用于具身智体的测试集)。
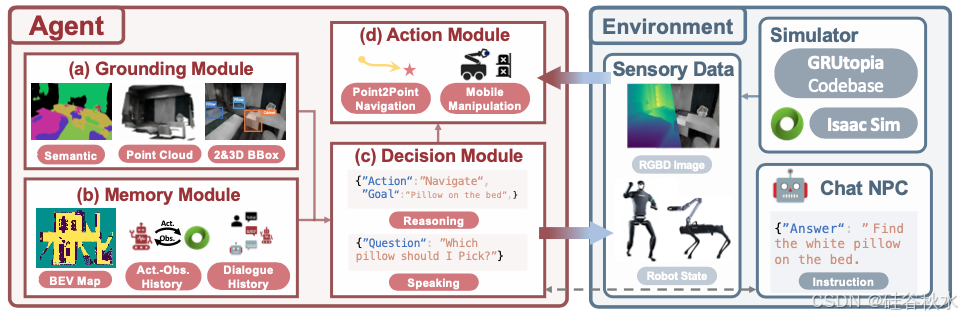
如图所示,所提出的 LLM 智体由一个落地模块、一个记忆模块、一个决策模块和一个动作模块组成。智体的环境输入是智体的自我中心观察和机器人的当前状态。通过这些模块之间的协作交互,智体可以有效地分析和利用环境输入,使其能够与环境进行物理和语言交互。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









