










24年10月来自清华大学、多伦多大学、香港中文大学和腾讯公司的论文“VidEgoThink: Assessing Egocentric Video Understanding Capabilities for Embodied AI“。
多模态大语言模型 (MLLM) 的最新进展为具身智能的应用开辟了新的途径。在 EgoThink 的基础上,推出 VidEgoThink,这是一个评估自我中心视频理解能力的综合基准。为了弥合具身智能中 MLLM 与低级控制之间的差距,设计四个关键的相互关联的任务:视频问答、分层规划、视觉落地和奖励建模。为了最大限度地降低人工注释成本,用 GPT-4o 的先验知识和多模态功能,基于 Ego4D 数据集开发一个自动数据生成流水线。然后,三位人工标注者过滤生成的数据以确保多样性和质量,从而得出 VidEgoThink 基准。对三种类型的模型进行广泛的实验:基于 API 的 MLLM、基于开源图像的 MLLM 和基于开源视频的 MLLM。实验结果表明,包括 GPT-4o 在内的所有 MLLM 在与自我中心视频理解相关的所有任务中表现不佳。这些发现表明,基础模型仍需要重大改进才能有效应用于具身智能中的第一人称场景。总之,VidEgoThink 反映一种研究趋势,即将 MLLM 用于以自我中心视觉,类似于人类的能力,从而能够在复杂的现实世界环境中进行主动观察和交互。
以自我为中心的视频(Grauman,2022;Damen,2018)包含典型的第三人称视角观察和与周围环境的额外互动,可以改善主要的 MLLM,使其更加通用,并将其应用扩展到现实世界。
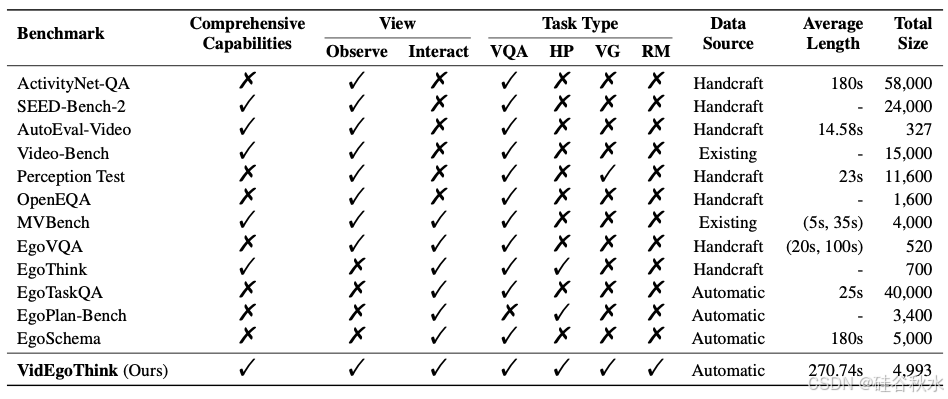
如表所示,已经出现各种以自我为中心的基准测试(Cheng,2024;Fan,2019),用于从第一人称视角评估 MLLM 的能力。例如,EgoTaskQA(Jia,2022)和 EgoPlan(Chen,2023c)评估 MLLM 对长范围任务的规划能力,而 EgoSchema(Mangalam,2024)旨在诊断对超长视频的理解。然而,缺乏从自我中心角度进行的全面视频基准测试,这对通用基础模型的开发提出了重大挑战。此外,当前的基准测试(无论是在任务设计还是文本输出形式中)都侧重于传统的视频问答设置,而忽略了支持具身智能下游应用(如玻璃设备或自主机器人)的潜力。例如,自然语言输出格式(例如“将三文鱼放入微波炉”)不能由机器人直接处理以采取行动,而落地目标的边框(例如“微波炉[290、202、835、851]”或低级动作的函数调用(例如“查找(微波炉)”)与机器人控制系统的输入要求更加一致。因此,设计合适的任务格式,以有效应用于具身智能的下游应用至关重要。
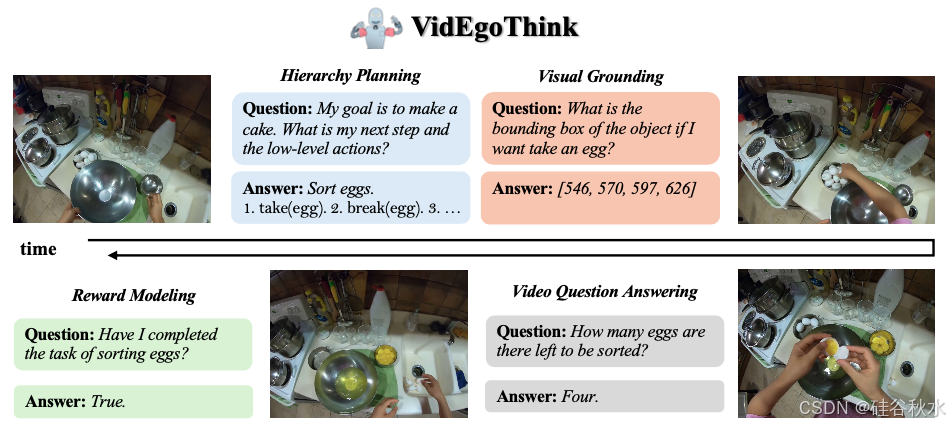
如图所示:VidEgoThink 基准测试的主要任务是全面评估具身智能的以自我中心视频理解能力。任务类型包括视频问答、分层规划、视觉落地和奖励建模。这四个任务相辅相成,共同实现具身智能的完整目标。
为了强调静态图像和动态视频之间的差异(Li et al.,2023d),强调时间属性,确保问题需要整个视频才能准确回答,而不仅仅是单个帧。考虑到从第一人称视角观察和与现实世界互动的基本能力,将围绕“我自己”的视频模态内容分解为三个主要元素:目标、动作和场景。此外,从这些元素中探索了一系列细粒度维度,如图所示。
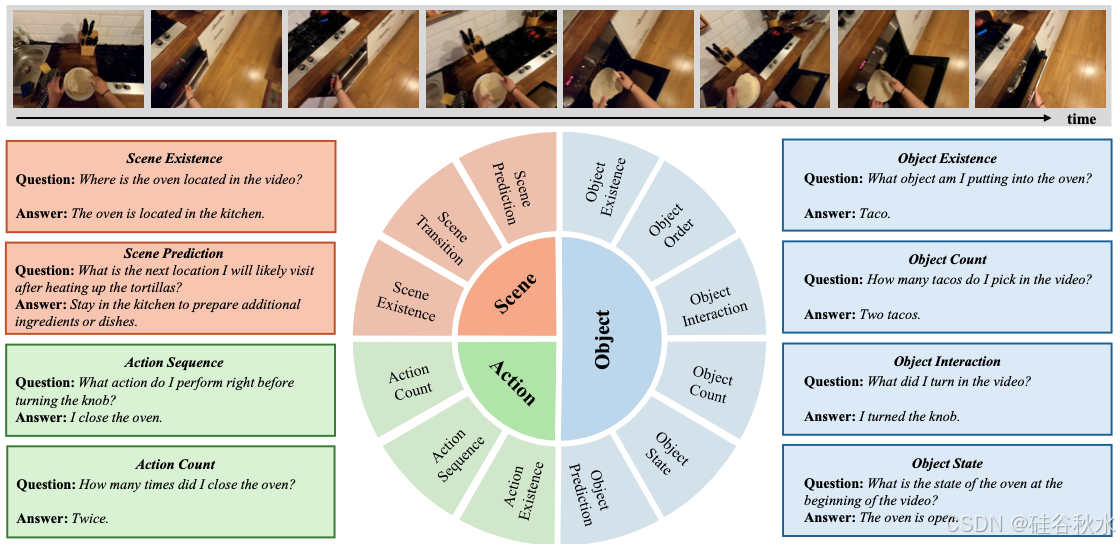
观察目标、与目标互动是人类视觉系统的基本能力。以自我为中心的视频强调“自己”看到或使用的目标。进一步将目标类别划分为六个细粒度的维度:(1)目标存在性(OE):确定目标是否出现在视频中;(2)目标顺序(OO):确定目标在视频中出现的顺序;(3)目标交互(OI):评估目标是否在视频中使用过以及如何使用;(4)目标计数(OC):计数特定类型的目标总数;(5)目标状态(OS):评估目标的状态是否发生变化;(6)目标预测(OP):预测某个目标会发生什么。
动作识别涉及自动识别视频中的特定人类动作。以自我为中心的视频强调与“我自己”互动的事件。动作预测非常重要,并且已成为具身智能的标准任务。进一步将动作维度划分为三个细粒度维度:(1)动作存在(AE):确定视频中是否发生了动作;(2)动作序列(AS):确定视频中动作发生的顺序;(3)动作计数(AC):计数动作发生的频率。
从第一人称视角感知周围场景,对于与环境交互至关重要。在以自我为中心的视频数据中,自我的身体和视点的不断运动,使得描述目标相对于自我的方向位置变得具有挑战性,因此需要与环境背景相结合。还设计三个细粒度维度来感知场景:(1)场景存在(SE):确定视频是否发生在某个场景中; (2)场景转换(ST):识别所访问场景之间的转换;(3)场景预测(SP):预测下一个场景发生的地点。
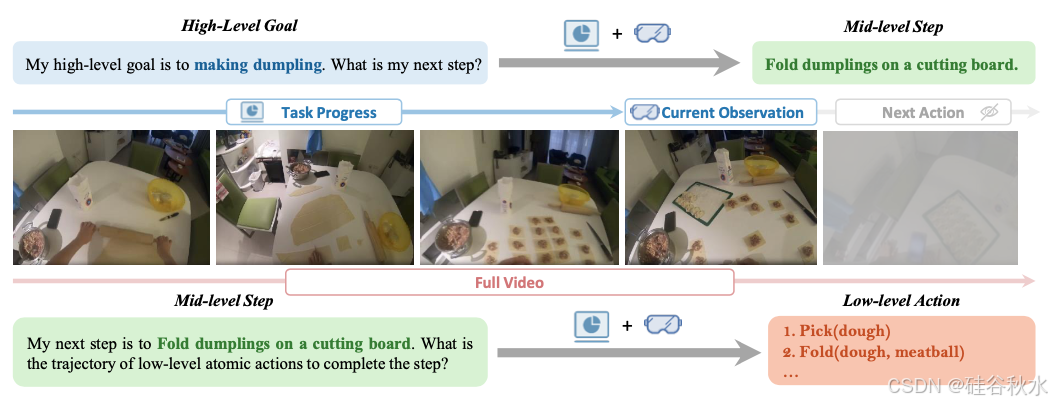
一种分层规划框架(Ahn,2022;Singh,2023;Vemprala,2024),将基础模型和传统方法的优势结合起来,应用于具身智能。具体来说,基础模型被用作规划器,将高级任务指令(例如,“烹饪鲑鱼”)分解为中级步骤(例如,“# 将鲑鱼放入微波炉”)或低级原子动作(例如,“找到(微波炉)”),这更便于控制。尽管 EgoPlan-Bench(Chen,2023c)从第一人称视角探索了规划能力,但它只考虑将高级目标分解为中级步骤,并且其任务格式是多选的,不太自然。
如图所示:设计了两种规划任务,高级目标到中级步骤,中级步骤到低层动作。
虽然自然语言对于人类交流很有效,但它不能直接转化为低级动作或落地于现实世界。因此,视觉落地(Peng,2023;Chen,2023a;Munasinghe,2023)在基于图像和视频的 MLLM 中引起了极大关注。此任务要求模型将复杂的自然语言描述或指令落地于图像或视频中,并输出相应的像素级边框、掩码版或帧。边框和掩码可以直接识别可操作目标(Munasinghe,2023;Zheng,2024a),而帧可以为下游任务提供足够的空间或时间信息(Li,2024c;Chiang,2024)。
如图所示:包括三种场景下的落地任务,目标落地、帧落地和时域落地。

在具身智能中,由于需要准确性和多样性,尤其是对于人类活动,手动设计奖励函数来监督动作具有挑战性。得益于大规模互联网训练语料库,基础模型可以作为具有内置常识和推理能力的奖励模型。将基础模型部署为奖励模型有三种主要方法:(1)使用具有简单二元打分的稀疏智体奖励函数(Kwon,2023);(2)计算相近词汇动作短语和图像之间的相似度(Di Palo,2023;Rocamonde,2023);(3)生成代码以将任务语义转换为组合奖励函数(Yu,2023;Ma,2023)。考虑到针对视频数据的可行性,该文主要关注第一种方法。
如图所示:设计两种奖励建模,批评和反馈。

最近发布的以自我中心视频数据集(Grauman,2022;2024;Huang,2024)推动了具身智能领域的发展。为了确保多样性和普及性,用流行的 Ego4D 数据集(Grauman,2022)来构建 VidEgoThink 基准。Ego4D-v2 包含 3,900 小时的 9,611 个自我中心视频,并带有多样化的人工注释。为了避免数据泄露,从验证数据集中选择视频。然而,由于 MLLM 的视频长度限制,冗长的 Ego4D 视频(从几十分钟到一个多小时不等)并不适合。此外,手动标记的问答数据需要大量的人力。为了解决这些问题,设计策略来自动将视频剪辑到合适的长度并生成相应的问答对。为了防止 VidEgoThink 基准测试因提示工程而受到损害,用于自动注释构建的详细提示将不会发布。VidegoThink 中每个任务的统计数据如表所示。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









