










24年6月来自CMU和上海交大的论文“OmniH2O: Universal and Dexterous Human-to-Humanoid Whole-Body Teleoperation and Learning”。
OmniH2O(Omni Human-to-Humanoid),这是一种基于学习的全身类人机器人遥操作和自主系统。OmniH2O 使用运动姿势作为通用控制界面,使人类能够以各种方式用灵巧的双手控制全尺寸的类人机器人,包括通过 VR 耳机、口头指令和 RGB 摄像头进行实时遥操作。OmniH2O 还可以通过从遥操作演示中学习或与 GPT-4o 等前沿模型集成来实现完全自主。 OmniH2O 通过遥操作或自主操作展示各种现实世界全身任务的多功能性和灵活性,例如进行多种运动、移动和操纵目标以及与人类互动。本文开发基于 RL 的模拟-到-现实流水线,其中涉及大规模重定位和增强人体运动数据集,通过模仿特别教师策略,学习具有稀疏传感器输入的现实世界可部署策略,以及奖励设计以增强鲁棒性和稳定性。制作第一个人形机器人全身控制数据集 OmniH2O-6,其中包含六个日常任务,并展示从遥操作数据集进行的人形全身技能学习。
如图所示:(a) OmniH2O 可以遥操作全尺寸的人形机器人 (UnitreeH1),以完成需要高精度操纵和运动的任务。 (b) OmniH2O 还可以通过视觉输入实现完全自动化,由 GPT-4o 或从遥操作演示中学习的策略控制。

如何才能最大限度地释放人形机器人作为通用智能最有前途的物理具身之一的潜力?受最近预训练视觉和语言模型 [1] 成功的启发,一个潜在的答案是在现实世界中收集大规模人类演示数据并从中学习人形机器人技能。人形机器人和人类之间的具身一致,不仅使人形机器人成为一个潜在的通用平台,而且还能够无缝集成人类认知技能以实现可扩展的数据收集 [2、3、4、5]。
然而,全尺寸人形机器人的全身控制具有挑战性 [6],许多现有研究仅关注下半身 [7、8、9、10、11、12、13] 或分离的下半身和上半身控制 [14、4、15]。为了同时支持稳定的灵巧操作和稳健的运动,控制器必须协调下半身和上半身。对于人形遥操作界面 [2],对动作捕捉和外骨骼等昂贵设备的需求,也阻碍了大规模人形机器人数据收集。简而言之,需要一种强大的控制策略,支持全身灵巧的操控,同时无缝集成易于使用且易于访问的遥操作界面(例如 VR),以实现可扩展的演示数据收集。
基于学习的人形机器人控制。由于人形机器人具有高自由度 (DoF) 且缺乏自稳定性,因此控制人形机器人是一个长期存在的机器人问题 [16, 17]。最近,基于学习的方法已显示出有希望的结果 [7, 8, 9, 10, 11, 12, 13, 3, 18]。然而,大多数研究 [7, 8, 9, 10, 11, 12, 13] 主要侧重于学习稳健的运动策略,并没有完全释放人形机器人的所有能力。对于需要全身操控的任务,下半身必须作为灵活而精确的上半身运动支撑 [19]。腿部运动中使用的传统目标达成 [20, 21] 或速度跟踪目标 [18] 与此类要求不相容,因为这些目标需要额外的特定于任务下半身目标(来自其他策略)来间接解释上下半身的协调。
人形机器人遥操作。遥控人形机器人在释放人形机器人系统的全部功能方面具有巨大潜力。人形机器人遥操作的先前研究使用了任务空间控制 [4, 22]、上半身重定位遥操作 [23, 24] 和全身遥操作 [25, 26, 27, 28, 29, 30, 3, 4]。最近,H2O [3] 提出一种基于 RL 的全身遥操作框架,该框架使用第三人称 RGB 摄像头来获取人类遥操作员的全身关键点。然而,由于基于 RGB 姿势估计的延迟和不准确性以及对全局线速度估计的要求,H2O [3] 在测试时需要 MoCap,仅支持简单的移动任务,并且缺乏灵巧操作任务的精度。相比之下,OmniH2O 可在室内和野外实现高精度灵巧的移动操作。
全身人形机器人控制界面。为了控制全尺寸的人形机器人,提出了许多界面,例如外骨骼 [31]、MoCap [32、33] 和 VR [34、35]。最近,基于 VR 的人形机器人控制 [36、37、38、39] 因其能够使用稀疏输入创建全身运动而引起了图形学社区的关注。然而,这些基于 VR 的方法,仅专注于动画的人形机器人控制,不支持移动操作。另一方面,OmniH2O 可以控制真实的人形机器人来完成现实世界的操作任务。
开源机器人数据集和模仿学习。机器人社区面临的一个主要挑战是与语言和视觉任务相比,公开可用的数据集数量有限 [40]。最近的研究 [40、41、42、43、44、45、46、47] 专注于使用各种具身方案为不同任务收集机器人数据。然而,这些数据集中的大多数都是使用固定底座机械臂平台收集的。即使是迄今为止最全面的数据集之一 Open X-Embodiment [40],也不包括人形机器人的数据。
问题表述。将学习问题表述为目标条件的 RL,用于马尔可夫决策过程 (MDP),由状态 S、动作 a/t、转换 T、奖励函数 R 和折扣因子 γ 的元组 M = ⟨S, A, T , R, γ⟩ 定义。状态 s/t 包含本体感受 sp/t 和目标状态 sg/t 。目标状态 sg/t 包括来自人类遥控操作员或自主智体的运动目标。基于本体感受 sp/t、目标状态 sg/t 和动作 a/t,定义奖励 r/t = R(sp/t , sg/t , a/t)。动作 a/t 确定目标关节角度,一个 PD 控制器启动电机。应用近端策略优化算法 (PPO) [48] 来最大化累积折扣奖励 E【sum (γt−1r^t)】。
本文研究运动模仿任务,其中策略 π/OmniH2O 经过训练可以跟踪实时运动输入,如图所示。此任务为人形机器人控制提供了一个通用接口,因为运动姿势可以由许多不同的来源提供。将运动姿势定义为 q/t ≜ (θ/t, p/t),由人形机器人上所有关节的 3D 关节旋转 θt 和位置 pt 组成。要定义速度 q/1:T,将 qt ≜ (ωt, vt) 表示为角速度 ωt 和线速度 vt。作为一种符号约定,用~· 来表示来自 VR 耳机或姿势生成器的运动量,使用 ^· 来表示来自 MoCap 数据集的真值,并使用普通符号来表示来自物理模拟或真实机器人的值。
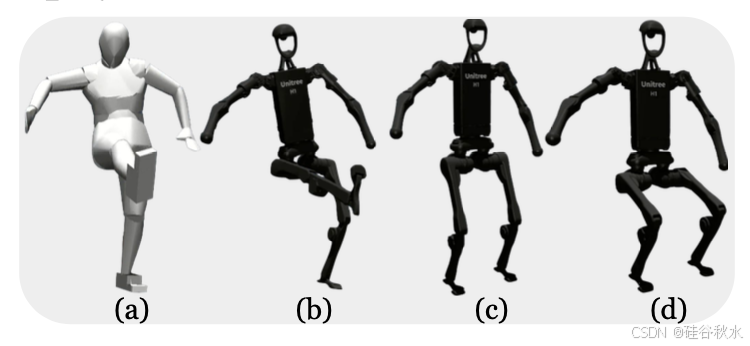
人体运动重定向。用来自 AMASS [49] 数据集的重定向运动来训练运动模仿策略,使用与 H2O [3] 类似的重定向过程。H2O 的一个主要缺点是人形机器人倾向于采取小的调整步骤而不是静止不动。为了增强稳定站立和蹲下的能力,添加包含固定下半身运动的序列来偏置训练数据。具体来说,对于来自数据集的每个运动序列 qˆ/1:T,将根位置和下半身固定为站立或蹲下位置来创建一个“稳定”版本 q^stable/1:T,如图所示:(a)源运动;(b)重定位运动;(c)站立变型;(d)蹲姿变型。
奖励和域随机化。为了训练适合作为现实世界可部署学生策略的老师 π/privileged,同时采用模仿奖励和正则化奖励。以前的工作[18,3]经常使用正则化奖励,如脚在空中的时间(feet air time)或脚的高度(feet height)来塑造下半身的运动。然而,这些奖励导致人形机器人跺脚以保持平衡而不是站着不动。为了鼓励在运动过程中站着不动并迈出大步,提出一个奖励函数,即每一步的脚最大高度(max feet height for each step)。每一步奖励的脚最大高度旨在通过根据脚在每一步的空中阶段达到的最大高度来奖励机器人,从而鼓励机器人迈出更高的步。将这种奖励与精心设计的课程结合使用,可以有效地帮助 RL 决定何时站立或行走。
老师:特别的模仿策略。在人形机器人的现实世界远程操作过程中,许多在模拟中可访问的信息(例如,每个身体链接的全局线速度/角速度)不可用。此外,遥操作系统的输入可能很稀疏(例如,对于基于 VR 的遥操作,只有手和头部的姿势是已知的),这使得 RL 优化具有挑战性。为了解决这个问题,首先训练一个使用特别状态信息的教师策略,然后将其蒸馏为具有有限状态空间的学生策略。访问特别状态可以帮助 RL 找到更优的解决方案,如先前的研究 [50] 和实验所示。正式地,训练一个特别运动模仿器 π/privileged(a/t |sp-privileged/t,sg-privileged/t),如图所示。本体感觉定义为sp-privileged/t ≜ [p/t,θ/t,q̇/t,ω/t,a/t-1],它包含人形刚体位置p/t,方向θ/t,线速度q̇/t,角速度ω/t,和之前的动作a/t-1。目标状态定义为 s^g-privileged/t ≜ [θˆ/t+1 ⊖ θ/t, pˆ/t+1 − p/t, vˆ/t+1 − v/t, ωˆ/t+1 − ω/t, θˆ/t, pˆ/t+1],其中包含人形机器人所有刚体的参考姿势 (θˆ/t, pˆ/t) 以及参考状态与当前状态之间的一帧差。
如图所示:(a)OmniH2O 重定位大规模人体运动并过滤掉不适合人形机器人的运动。 (b)模拟-到-现实策略是通过使用特别信息从 RL 训练的教师策略中进行监督学习而蒸馏出来的。 (c)OmniH2O 的通用设计支持多种人机控制界面,包括 VR 耳机、RGB 摄像头和语言等。系统还支持由 GPT-4o 等自主智体或使用遥控收集的数据集进行训练的模仿学习策略进行控制。
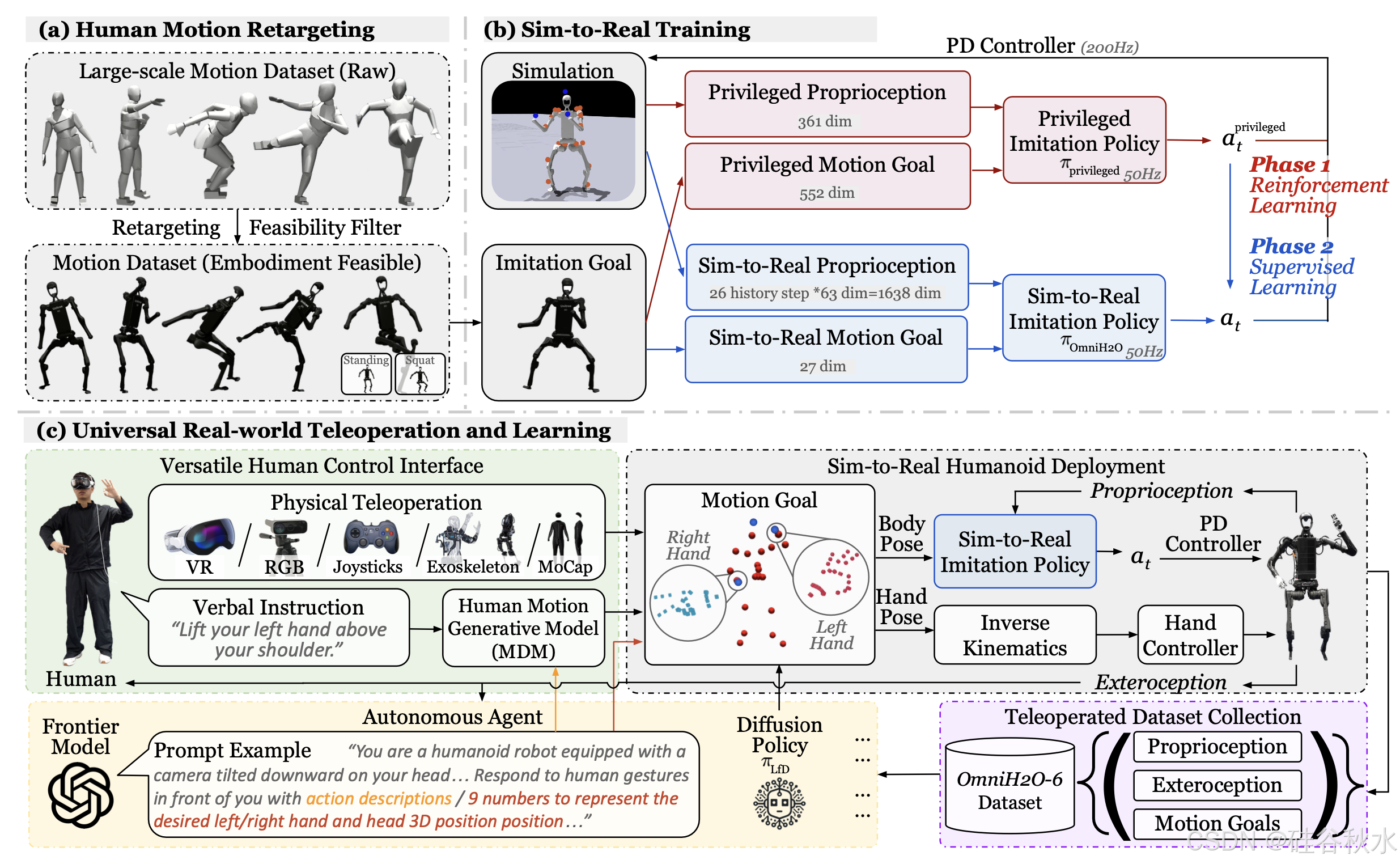
学生:带历史的模拟-到-真实模仿策略。本文设计了兼容多种输入源的控制策略,使用运动学参考运动作为中间表示。由于估计全身运动 q ̃/t(旋转和平移)很困难(尤其是使用 VR 头戴式设备),选择仅在遥操作时以位置 p ̃/t 来控制人形机器人。具体来说,对于现实世界的遥操作,目标状态是 sg-real/t ≜ (p ̃real/t −preal/t , v ̃real/t −vreal/t , p ̃real/t )。上标 real 表示使用 VR 耳机提供的 3 个点(头部和手部)。对于其他控制界面(例如 RGB、语言),用相同的 3 点输入来保持一致性,但可以轻松扩展到更多关键点以减轻歧义。对于本体感受,学生策略 sp-real/t ≜ (d/t-25:t, d ̇/t-25:t, ωroot/t-25:t, g/t-25:t, a/t-25:t) 使用现实世界中易于获取的值,其中包括关节 (DoF) 位置 d/t−25:t、关节速度 d ̇/t−25:t、根角速度 ω^root/t-25:t、根重力 g/t-25:t 和先前动作 a/t-25-1:t-1 的 25 步过去数据。过去数据的加入,有助于提高该策略与师-生监督学习的稳健性。请注意,观察结果中不包含全局线速度 v/t 信息,并且该策略使用过去信息隐式地学习速度。这消除了对 H2O [3] 中 MoCap 的需求,并进一步增强野外部署的可行性。
策略蒸馏。按照 DAgger [51] 框架训练可部署的遥操作策略 π/OmniH2O。
灵巧手控制。如上图 © 所示,用 VR [52, 53] 估计的手部姿势,并直接根据逆运动学计算现成低级手部控制器的关节目标。用 VR 进行灵巧手控制,但手部姿势估计也可以由其他接口(例如 MoCap 手套 [54] 或 RGB 相机 [55])代替。
真实机器人采用 Unitree H1 平台 [61],配备 Damiao DM-J4310-2EC 电机 [62] 和 Inspire 手 [63] 以实现其操作能力。有两个版本的真实机器人计算设置。
(1)第一个版本在 H1 机器人的背面安装两台 16GB Orin NX 计算机。第一个 Orin NX 连接到安装在 H1 腰部的 ZED 摄像头,该摄像头执行计算以确定 H1 自身的定位位置。摄像头以 60 Hz FPS 运行。此外,这个 Orin NX 通过 Wi-Fi 连接到 Vision Pro 设备,持续从人类操作员那里接收运动目标信息。第二个 Orin NX 充当主要控制中心。它接收运动目标信息,并将其用作控制策略的输入。然后,该策略输出机器人每个电机的扭矩信息,并将这些命令发送给机器人。由于对机器人手指和手腕的控制不需要推理,因此它直接从 Vision Pro 数据映射到机器人上的相应关节。策略的计算频率设置为 50 Hz。两个 Orin NX 单元通过以太网连接,通过通用 ROS(机器人操作系统)网络共享信息。发给 H1 的最终命令由第二个 Orin NX 合并和分派。整个系统的延迟很低,只有 20 毫秒。值得注意的是,以这种方式设计系统的部分原因是 ZED 相机需要大量的计算资源。将第一个 Orin NX 专用于 ZED 相机,将第二个 Orin NX 专用于策略推理,确保每个组件都以最佳性能运行。
(2)在第二个版本中,一台笔记本电脑(第 13 代 i9-13900HX 和 NVIDIA RTX4090,32GB RAM)用作计算和通信设备。所有设备(包括 ZED 摄像头、控制策略和 Vision Pro)都通过这台笔记本电脑上的 ROS 系统进行通信,从而实现集中数据处理和命令调度。这两种设置的性能相似,在实验中交替使用它们。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









