










24年11月来自TX Austin和波士顿AI研究所的论文“LEGATO: Cross-Embodiment Imitation Using a Grasping Tool”。
跨具身模仿学习使在特定具身上训练的策略能够在不同的机器人之间迁移,从而释放出既经济高效又可高度重用的大规模模仿学习的潜力。LEGATO,是一个跨具身模仿学习框架,用于跨各种运动形态进行视觉运动技能迁移。引入一种手持式夹持器,它统一动作和观察空间,允许在机器人之间一致地定义任务。使用此夹持器,通过模仿学习训练视觉运动策略,应用运动不变变换来计算训练损失。然后使用逆运动学将夹持器运动重定位为高自由度全身运动,以便在不同的具身中部署。在模拟和真实机器人实验中评估,突出了该框架在学习和跨各种机器人迁移视觉运动技能方面的有效性。
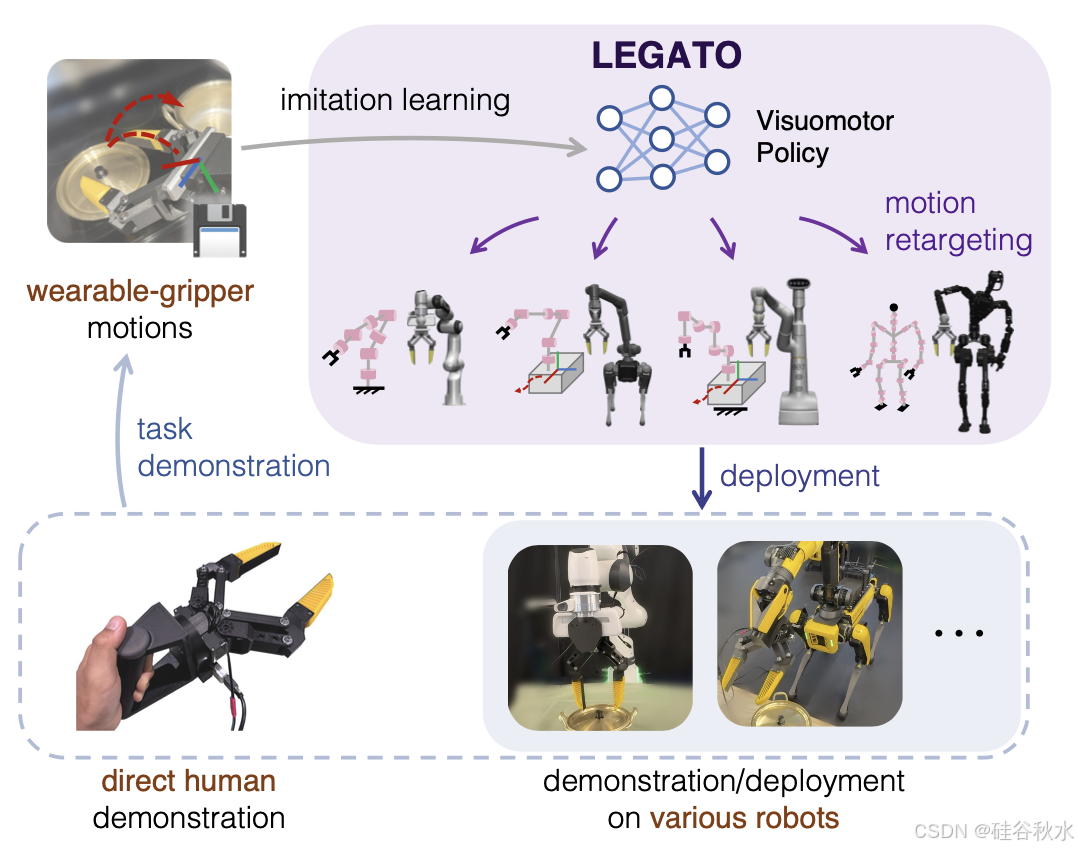
如图所示 LEGATO 概述。LEGATO 解决在不同的机器人具身之间迁移视觉运动技能的挑战。介绍一种跨具身模仿学习框架,该框架使用一种多功能手持抓取工具,可确保不同具身之间的物理交互一致。使用该工具从人类或遥控机器人演示中训练的策略可以部署在配备相同夹持器的各种机器人上。运动重定向可以在不同的机器人上执行轨迹,而无需特定于机器人的训练数据。
机器人硬件方面的最新进展(从轮式操纵器到人形机器人 [1–5])极大地增加了对各种机器人平台的访问。为了充分利用这些进步来更好地支持人类活动,机器人必须自主执行各种复杂任务。与传统的基于规则的方法相比,深度模仿学习在训练感知运动技能的自主策略方面表现出了良好的前景,减少了对大量人类编程的需求。它在复杂的机器人系统 [6, 7] 和各种灵巧的操作任务 [8–10] 中取得了令人印象深刻的成果。然而,这些方法通常需要来自特定目标机器人本身的演示数据,由于硬件成本高昂以及在演示期间操作机器人的工作量大,限制了可扩展性。此外,对每个机器人进行个性化训练限制了跨实体应用,因为数据无法在不同的机器人系统之间迁移,即使是类似的任务也是如此。
为了实现可扩展的演示,开创性的工作已经引入了数据收集工具,允许人类在演示期间直接进行操作 [11–14]。这些方法能够训练可部署到指定目标机器人的视觉运动策略,减少人工工作量并避免使用真实机器人进行数据收集所产生的成本和风险。然而,这些方法需要为特定的机器人夹持机制设计专门的数据收集工具,或者用定制的硬件替换机器人原有的夹持器。这个限制了这些工具对具有各种夹持机制的机器人的适用性。例如,通用操作接口(UMI) [14] 专为带有平行钳口机制的 Schunk WSG-50 夹持器设计,但不适用于其他机制,如枢纽(hinge)类型。此外,机器人之间的控制延迟和轨迹跟踪误差存在差异,而这些在人工演示中是不存在的,这使得具身之间的策略迁移变得复杂。Chi [14] 通过补偿控制和观察延迟来解决这个问题,而 Song [11] 则通过对目标机器人系统进行反复试验进行微调。然而,这些策略很难在不同的机器人上泛化,因为由于硬件和控制器的差异,不同平台之间的控制延迟会有所不同。
跨具身的技能学习
跨具身策略迁移允许从更简单或成本更低的具身中收集演示数据,并允许在不同的机器人具身中重复使用这些数据。一种方法是从直接人类演示的视频中学习,这在早期的方法 [15–20] 中得到了广泛的探索。然而,机器人部署受到对第三人称视觉观察的依赖以及缺乏现实世界物理交互数据的限制。
另一种方法集成专门为演示收集而设计的工具。一种方法涉及使用具有本体感受传感器模式的领导者-跟随者方法,这种方法已经被探索并证明是成功的 [21, 22]。这些工作将人类演示限制在与目标机器人具有相同运动学的领导者硬件上,从而允许完全访问跟随机器人的关节状态。但是,它们需要执行特定于每种机器人运动类型的演示。另外,最近的研究使用手持工具记录手上的视觉观察和演示中的相应动作 [11, 12, 14, 23]。虽然这些方法简化了工具设计,但它们仍然需要系统专用工具或对机器人原始硬件进行修改,以确保末端执行器的物理交互与记录的视觉观察之间一致性。
全身运动重定向
运动重定向能够在不同的具身中生成实际运动。目前,已有大量研究针对相似形态之间的运动重定向,例如从人类到人形机器人,采用基于模型的方法 [24–27] 或数据驱动的方法 [28–30]。然而,由于任务的模糊性,将人类运动转化为不同目标形态的等效运动是一项挑战。最近的研究调查了具有不同形态实施方案之间的运动重定向 [31–33]。虽然这些研究成功地展示了从人形到非人形形态的运动重定向,但它们通常依赖于实施方案特定或任务特定的训练模型。
轨迹表示
为了有效地在不同具身之间迁移运动,运动基元提供了一种实用的解决方案。这些基元有助于基本运动的组装,如文献中广泛记录的那样 [34–36]。然而,它们的适应性本质上受到设计的限制,使得它们对于新任务或环境的效率较低。最近的进展,例如将轨迹投射到潜空间的编码器-解码器框架,显著提高了运动基元的学习 [37–39]。将运动编码到学习的潜空间有助于将人类运动转移到模拟人形模型 [40],并使其适应具有不同运动结构的机器人具身 [33]。然而,这些方法在实现不同场景的广泛泛化时经常遇到挑战。
LEGATO,是一个跨具身的模仿学习框架,由高级视觉运动策略和低级运动重定向组成,如图所示。视觉运动策略通过模仿学习任务演示进行训练,这些演示来自直接使用工具的人,或来自手持工具的遥控机器人。不同机器人之间手持夹持器运动和自我中心视觉观察动作空间的一致性,使得可以部署到各种具身中。低级运动重定向将这些夹持器轨迹实现为跨不同机器人平台的全身运动。
将跨具身操作问题建模为离散时间马尔可夫决策过程 M = (S, A, P, R, γ, ρ/0),其中 S 是状态空间,A 是动作空间,P(·|s, a) 是转换概率,R(s, a, s′) 是奖励函数,γ ∈ [0,1) 是折扣因子,ρ/0(·) 是初始状态分布。目标是学习一个闭环视觉运动策略 π(a/t|s/t),以最大化不同机器人系统的预期回报。
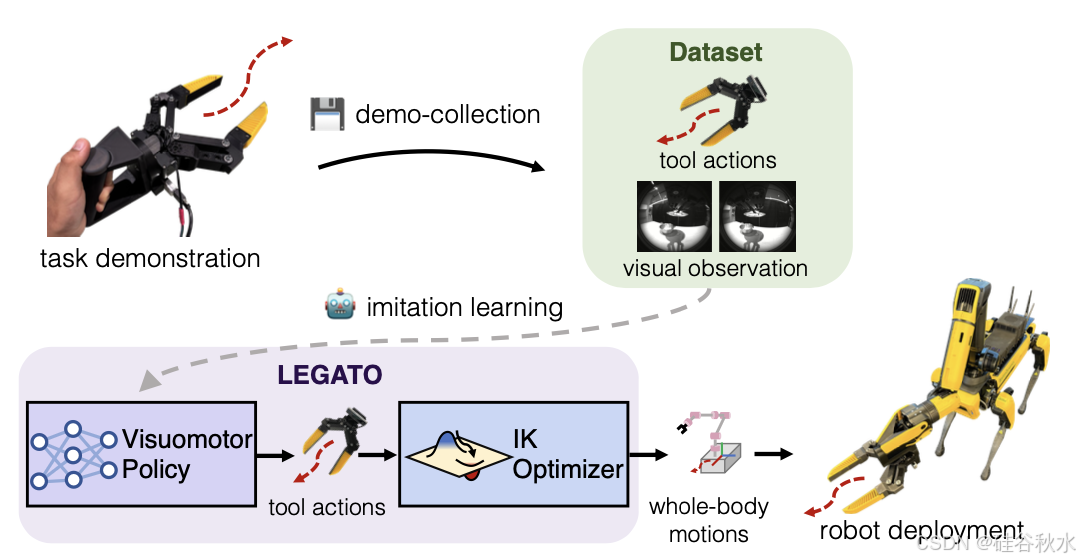
为了处理视觉运动技能的复杂性并确保策略 π 可在各种机器人系统中部署,将策略分解为两级层次结构。高层次是跨具身的视觉运动策略 π/H,它以神经网络的形式实现,用于计算手持式夹持器 u 的目标运动轨迹。通过模仿学习训练 π/H,用户操作手持式夹持器收集直接人体演示。在低层次,用全身运动优化器 π/L,它通过逆运动学 (IK) 确定关节配置以遵循 π/H 建立的轨迹 u。这样就无需在目标机器人系统上进行额外的训练。通过这种分层结构,整个策略可以表示为 π(a/t|s/t) = π/L(a/t|s/t, u/t)π/H (u/t|s/t)。
采用 LEGATO 夹持器,它可以在不同的机器人系统之间共享。受 Noguchi 的启发 [42],每个机器人都使用自己的夹持器来握住手持式夹持器,将其集成为具身的一部分。手持式夹持器保持一致的形状和视点,统一各个具身之间的视觉观察和动作空间。这降低跨具身问题的复杂性,简化手持式夹持器运动的映射,并协调全身运动以执行它们。
将动作空间定义为连续时间步骤之间 SE(3) 中的差分姿态。该动作空间适用于浮动底座机器人上可泛化的全身操纵,因为它消除对固定全局参考系的依赖。因此,动作在当前手持式夹持器框架中表示。从高斯混合模型 [43] 采样的差分 SE(3) 姿态动作捕捉人类演示的多模态性质和不变空间内的基本运动信息。
采用基于优化的 IK 方法来处理受限 IK 问题。这使运动优化器 π/L 能够通过利用自由度 (DOF) 冗余,同时尊重驱动界限和其他约束,有效地将命令映射到机器人的轨迹。该方法通过使用运动冗余来满足部署期间的关节和其他约束,解决机器人具身中的运动差异、约束和 DOF 多样性,而无需额外的机器人特定演示。
任务演示可以在任何能够在其关节空间内执行任务的具身上执行。收集的演示数据集 D 由状态-动作对 D = (s/i, u/i) 组成。此处,N 表示数据点的总数。观测值 s/i 包括从机器人机载摄像头视角获得的立体视觉图像和先前动作的历史缓冲区 u/k。视觉观测值以 128 × 128 像素大小的立体灰度图像提供。演示命令 u/i 包括手部 (6D) 和抓握动作 (1D) 的后续 setpoints。
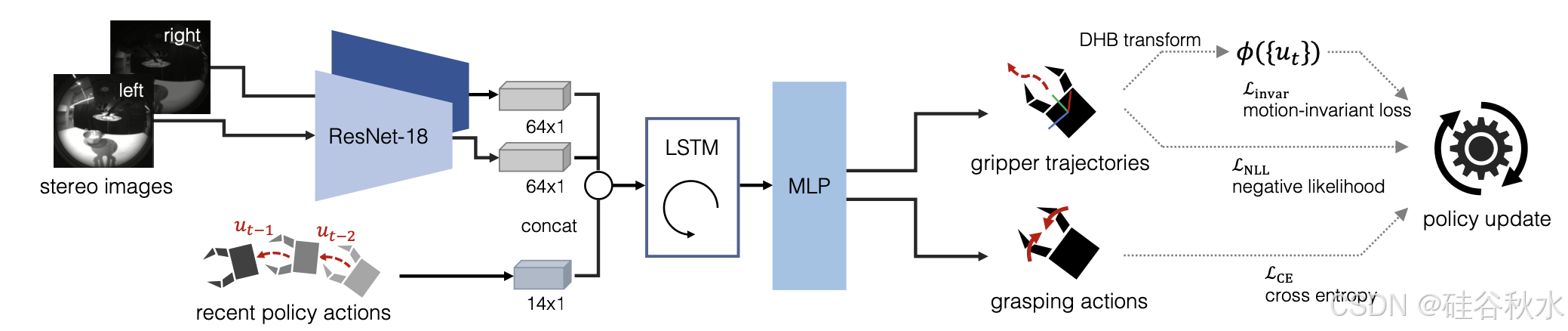
用深度模仿学习算法训练策略 π/H,具体来说,使用带有 LSTM 网络的行为克隆策略 [45, 46],如图所示。视觉运动策略采用两个独立的基于 ResNet18 的图像编码器 [47],具有相同的架构,并进行端到端训练。编码特征被扁平化并由两层 LSTM 网络处理,每层有 400 个隐藏单元。策略输出由三层多层感知器 (MLP) 生成,每层包含 2048 个隐藏单元。对于手部轨迹,策略输出高斯混合模型 (GMM) 参数,根据与前一帧的空域和旋转差异确定下一个目标姿态,使用 5-模式 GMM。抓取动作以二元分类提供,用于打开和关闭夹持器。
LEGATO 夹持器设计是在真实硬件上实现的。它专为直观使用而设计,既可用于直接的人工演示,也可用于机器人操作,如图所示。在人工演示期间,用户携带 LEGATO 夹持器并控制抓取动作。另一方面,机器人可以使用其原始夹持器握住工具,而无需进行任何硬件修改。


为了便于连接和更换,设计采用模块化,特别是机器人抓握的手柄部件,如上图所示。因此,只需为不同的机器人更换手柄部件,即可在各种应用中共享所有其他核心组件。LEGATO 夹持器具有两对平行四连杆机构,每对由一个自由度驱动,从而实现更广泛、更灵活的开口距离范围。该工具采用柔性鳍射线(fin-ray)机构的指尖,在接触过程中具有高柔性和适应性。 LEGATO 夹持器由 3D 打印部件制成,指尖采用 TPU 95A,其他部件采用 PLA,比典型的商用夹持器轻得多。这些关键特性促进将工具作为具身一部分进行集成的概念,即使在机器人有限的有效载荷能力下,同时支持可泛化的抓取动作。
LEGATO 夹持器配备 Realsense T265 [49](或者另一个立体视觉跟踪摄像头,如 SeerSense XR50 [50]),它具有鱼眼立体视觉摄像头和 IMU,用于流式传输视觉观察并通过视觉里程计(VO)估计手持夹持器的运动。在演示收集期间,会记录立体视觉图像和视觉里程计数据以形成观察-动作对。相比之下,在实际机器人部署期间,只传输立体视觉图像。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









