










25年1月来自上海AI实验室、香港中文大学、上海交大、南京大学、复旦大学和新加坡南洋理工的论文“InternLM-XComposer2.5-Reward: A Simple Yet Effective Multi-Modal Reward Model”。
尽管大视觉语言模型 (LVLM) 在视觉理解方面表现不俗,但它们偶尔也会生成错误的输出。虽然具有强化学习或测试-时间规模化的奖励模型 (RM) 具有提高生成质量的潜力,但仍然存在一个关键差距:用于 LVLM 的公开多模态 RM 很少,专有模型的实现细节通常不清楚。通过 InternLM-XComposer2.5-Reward (IXC-2.5-Reward) 弥补了这一差距,这是一个简单有效的多模态奖励模型,可将 LVLM 与人类偏好相一致。为了确保 IXC-2.5-Reward 的稳健性和多功能性,建立一个高质量的多模态偏好语料库,涵盖不同领域的文本、图像和视频输入,例如指令遵循、一般理解、富文本文档、数学推理和视频理解。 IXC-2.5-Reward 在最新的多模态奖励模型基准测试中取得优异的成绩,并在纯文本奖励模型基准测试中表现出色。IXC-2.5-Reward 的三个关键应用包括:(1)为 RL 训练提供监督信号;将 IXC-2.5-Reward 与近端策略优化 (PPO) 相结合,产生 IXC-2.5-Chat,它在指令遵循和多模态开放式对话方面表现出持续的改进;(2)从候选响应中选择最佳响应以进行测试-时间规模化;(3)从现有图像和视频指令调整训练数据中过滤异常值或噪声样本。
奖励模型 (RM) [8, 48, 55, 78, 88, 91, 92, 98, 104, 105, 121] 提供了关于 AI 模型的输出与人类偏好匹配程度的关键方向指导,并有利于大语言模型 (LLM) 的训练和推理。在训练期间,RM 通常与从人类反馈中强化学习 (RLHF) [7, 66, 70, 71] 一起使用,以惩罚不良的模型行为并鼓励符合人类价值观的输出。在推理时,RM 促进测试-时间规模化策略 [27, 80],例如从候选输出中选择最佳响应或为复杂的推理任务提供分步评论 [29, 107]。
尽管多模态 RM 在训练和推理中都发挥着至关重要的作用,但与 LLM 的纯语言 RM 相比,大型视觉语言模型 (LVLM) 的多模态 RM 仍然未被充分探索。由于当前的偏好数据主要是基于文本的,并且偏向特定领域(例如安全),数据稀缺对训练图像、视频和文本等不同模态的多模态 RM 构成了重大挑战。因此,现有的多模态 RM [87, 95] 在很大程度上局限于狭窄的领域(例如缓解幻觉)或依赖于带有评估提示的 LVLM,有效地充当生成 RM [94]。多模态 RM 的局限性随后限制了开源 LVLM 的功能,例如指令跟随和安全-应-拒绝,从而妨碍了多模态聊天场景中的用户交互体验。
大语言模型中的奖励模型。奖励模型 (RM) 对于从人类反馈中进行强化学习 (RLHF) [7, 66] 和测试-时间规模化定律 [29, 80] 都至关重要。RM 具有不同的实现形式,例如 (1) 判别性 RM [8, 48, 55, 88, 92, 98, 104, 121],通常是一个序列分类器,将输入序列分为不同的类别,例如二分类(“好”或“坏”),或在更细粒度的范围内 [88, 92]。 (2) 生成性 RM [39, 78, 91, 105],提示以文本的形式生成反馈,通常是对某个输出好或坏的原因的批评或解释。 (3) 隐式 RM [32, 40],使用 DPO [70] 优化的模型,预测对数概率被解释为隐式奖励信号。此外,RM 还可以分为结果 RM (ORM) [16] 和过程 RM (PRM) [46, 75, 86]。
大型视觉语言模型中的奖励模型。先前的 LVLM RM [87, 94, 95] 仅限于特定领域(例如,减少幻觉)或使用相对较弱的基础模型开发,这使得实现的模型明显不如 LLM RM。缺乏有效的多模态 RM 造成视觉 RLHF 的瓶颈,迫使研究人员仅仅使用离线-策略 DPO 算法的变型 [70]。先前的研究使用开源 LVLM 作为生成式 RM [65, 95, 102],使用数据增强技术注入幻觉 [21, 22, 25, 33, 67, 120, 122] 和基于规则的选择 [9, 53] 进行 DPO 数据选择,与 PPO [71] 等基于策略 RL 的解决方案相比,这可能会影响性能。此外,缺乏多模态 RM 也导致对人工注释 [82, 100] 的依赖或使用专有模型 [109, 116](如 GPT4)作为 DPO 对选择的生成式 RM,这对于大规模应用来说是昂贵且不可持续的。
奖励模型评估。评估基准的开发对于改进 RM 至关重要。已经提出几种用于评估 LLM RM 的综合基准,例如一般能力 [41, 51, 119]、多语言 [28, 81]、RAG [34] 和数学过程奖励 [117]。多模态 RM 的可用性有限阻碍了评估基准的开发,现有基准 [43] 仅关注生成 RM,缺乏对过程监督的评估。然而,考虑到 RM 关键重要性,未来多模态 RM 基准测试将取得重大进展。
社区对 RLHF 和测试时间扩展的兴趣日益浓厚,凸显对多模态 RM 的需求,这样本文提出 InternLM-XComposer2.5-Reward(IXC-2.5-Reward)。不是直接将单模态(文本)奖励模型 (RM) 转移到视觉模态,而是在现有的 LVLM(InternLM-XComposer2.5)上增加一个评分头来预测奖励分数。一个有效的多模态 RM 理想情况下应该具备两个关键属性:(1)能够预测图像、视频和文本输入的奖励分数;(2)能够跨不同领域进行泛化,例如指令跟随、知识、富文本图像(例如文档)、推理任务等。为此,开发一个流程(如图(a)所示)来构建多模态偏好数据,并结合现有的高质量数据集。该流程从不同领域中选择文本、图像和视频输入的提示,生成相应的响应,然后使用 GPT-4o [31] 或验证器 [40] 执行偏好判断。 IXC-2.5-Reward 在偏好数据上进行训练,可以有效地评估视觉(图像和视频)和文本输入(如图 (b) 所示)。
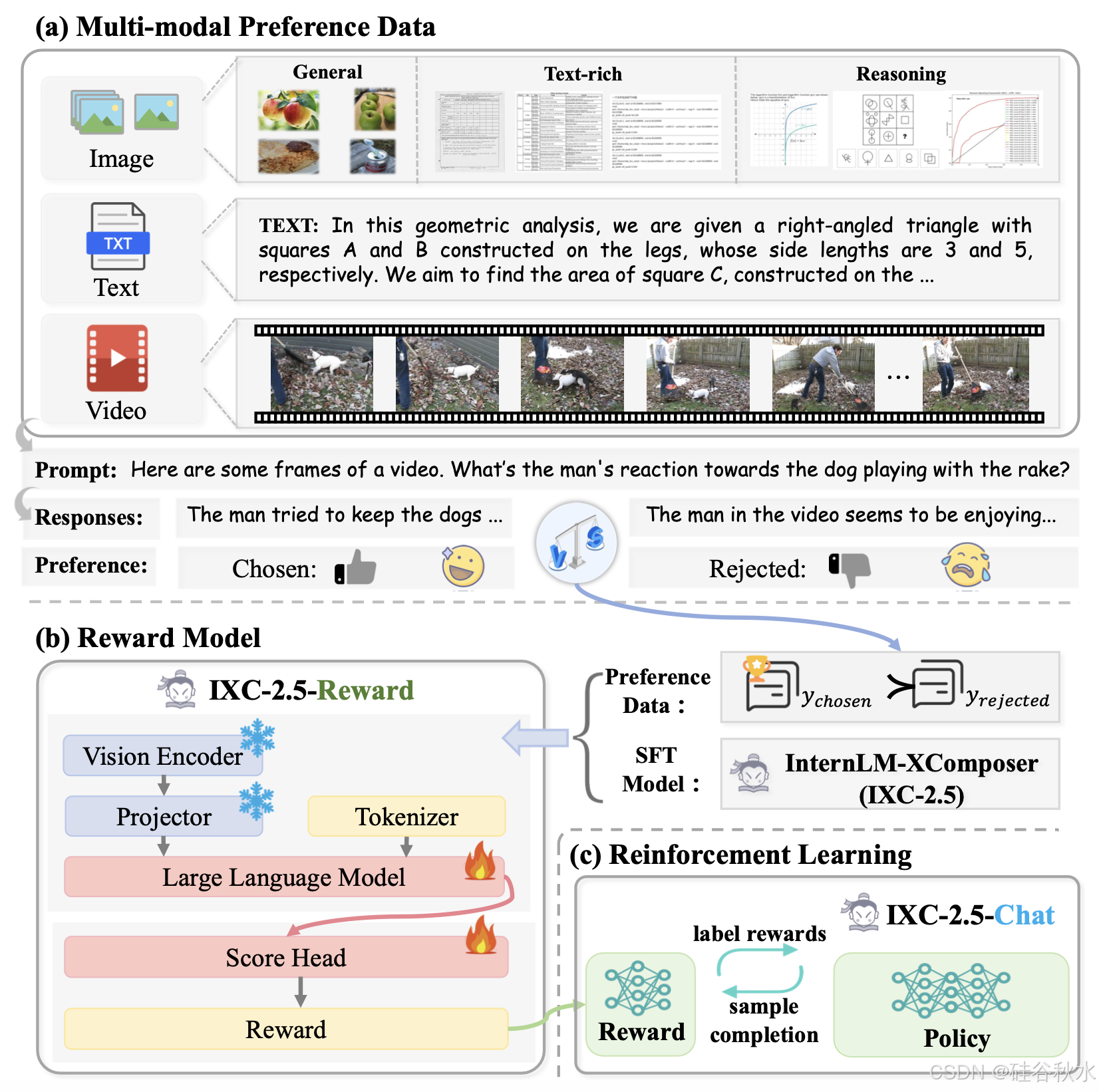
数据准备。奖励模型使用反映人类偏好的成对偏好注释(例如,提示 x 具有选定的响应 yc 和拒绝的响应 yr)进行训练。虽然现有的公共偏好数据主要是文本,图像有限且视频示例稀少,但使用开源数据和新收集的数据集来训练 IXC-2.5-Reward,以确保更广泛的领域覆盖。
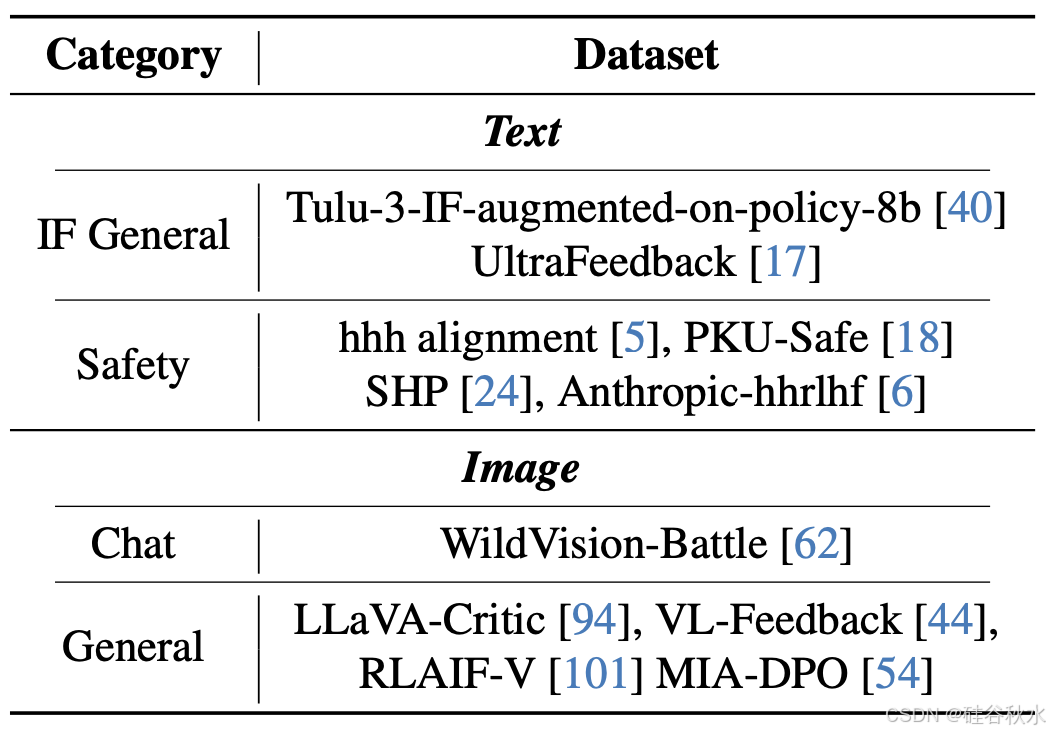
下表列出 IXC-2.5-Reward 中使用的开源成对数据,主要侧重于指令跟随、安全和一般知识。
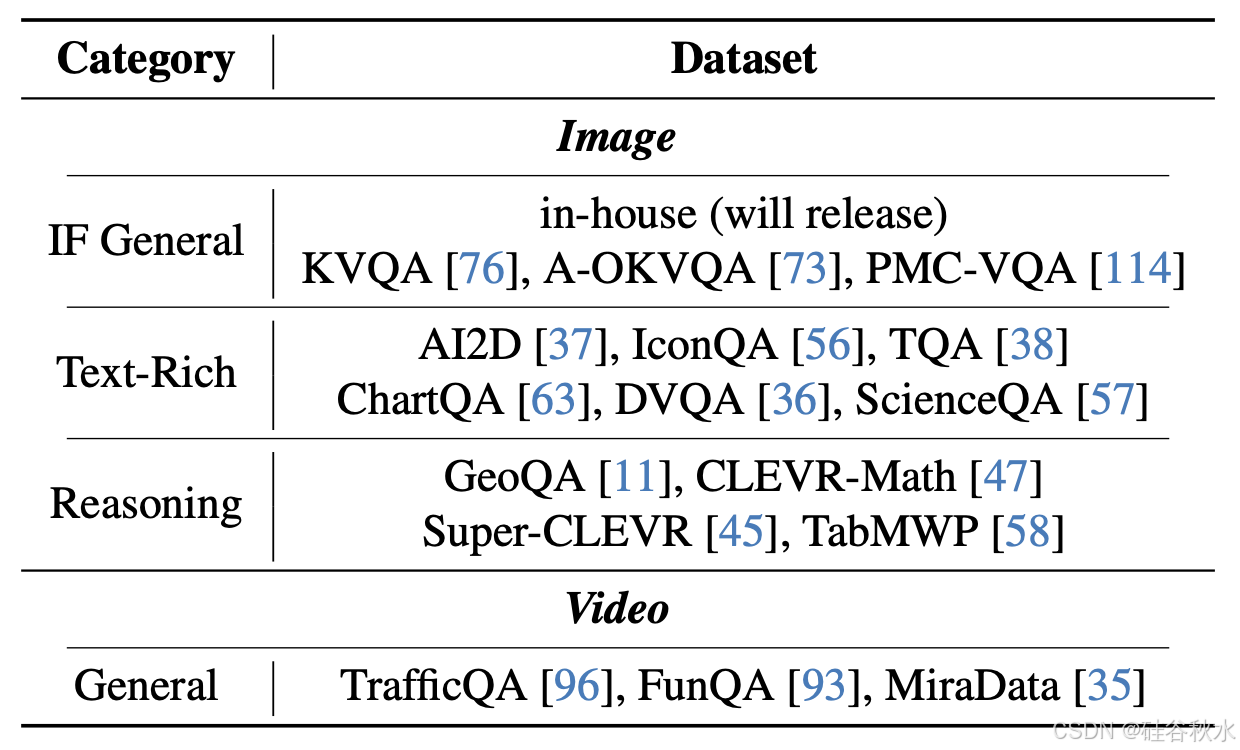
而下表详细介绍新收集的数据的来源,它最初是监督微调 (SFT) 数据,由提示 x 和相应的选定响应 y/c 组成,涉及不同的领域:富文本文档理解、数学推理和视频理解。还收集一些关于指令跟随的内部数据,这些数据将在未来发布。
为了获得被拒绝的回答,提示 SFT 模型 InternLM-XComposer-2.5 (IXC-2.5) [112] 为每个提示生成多个输出,然后采用不同的选择标准。对于一般和文本丰富的数据,用 GPT-4o [31] 和成对评估提示来确定评估结果比 SFT 真实答案更差的被拒绝回答。对于数学推理和指令跟随数据,构建验证器函数 [40],将生成的响应与真实解决方案进行比较,以标记选定和被拒绝的数据。新收集的数据补充现有的开源数据,创建一个全面、高质量的多模态偏好数据集。
模型架构。奖励模型 InternLM-XComposer 2.5-Reward (IXC-2.5-Reward) 建立在 SFT 模型 (IXC-2.5) [111] 之上。如上图 (b) 所示,大部分(例如视觉编码器和 MLP 投影器)使用 IXC-2.5-Chat 的预训练权重,这些权重已将图像和视频数据与文本模态对齐。因此,IXC-2.5-Reward 仅需要训练偏好数据来预测奖励分数,而不必使用其他预训练数据进行模态对齐。
将 IXC-2.5 的最终线性层替换为 IXC-2.5-Reward 的得分头 f,以预测奖励分数。给定输入提示 x 和响应 y,得分头 f 将所有标记的平均隐状态特征转换为二进制标量 r(x, y)。该标量值 r(x, y) 用作输入的预测奖励分数。
损失函数。奖励模型通过以下损失函数进行训练:
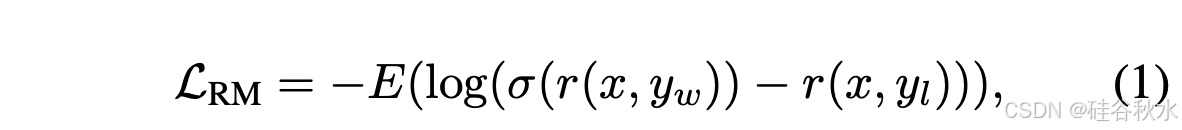
其中 r(x, y/w) 和 r(x, y/l) 分别表示使用所选数据 y/w 和拒绝数据 y/l 分配给提示 x 的奖励分数。
训练策略。如上图 (b) 所示,冻结从 IXC-2.5 [112] 初始化的模型视觉编码器和投影器,仅训练 LLM(InternLM [112])和评分头。IXC-2.5 的其他组件(例如用于高分辨率输入的动态图像分区机制)保持不变。
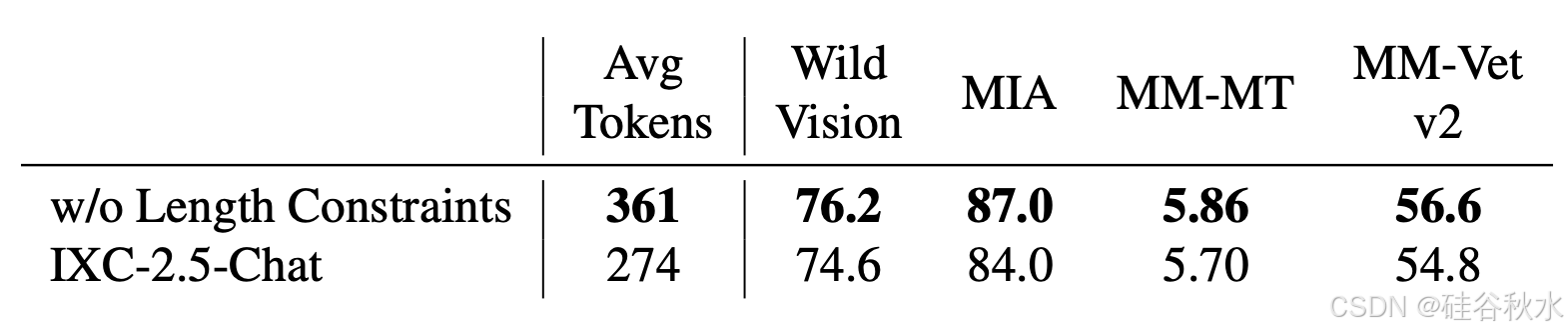
长度约束。删除所选响应 y/w 长度明显大于被拒绝响应 yl 长度的数据对。这有助于防止奖励模型学习将长度与质量联系起来。值得注意的是,基于 LLM 的评估容易受到长度偏差的影响,这是 LLM 中已知的问题 [23],这对 LVLM 也有重要影响。具体来说,使用 LVLM(例如 GPT-4o)作为评判的开放式视觉问答 (VQA) 基准,容易受到过长回答导致的分数膨胀影响。因此,取消奖励模型的长度限制可提高 PPO 策略性能。下表提供了详细分析。
IXC-2.5-Reward 的三个应用分别为:(1) RL 训练;(2) 测试时间扩展; (3) 数据清理。
IXC-2.5-Reward 用于强化学习训练
有了奖励模型 IXC-2.5-Reward,就可以应用基于策略的强化学习算法(例如 PPO [71]、RLOO [2]、GRPO [77])来直接优化 LVLM 性能,以实现所需的人类偏好。使用 PPO [71] 算法,随后训练策略模型 (IXC-2.5-Chat,π/θ),以最大化奖励模型 (IXC-2.5-Reward) 的预期奖励,同时保持接近参考模型 (IXC-2.5,π/ref) 以保持稳定性。从 IXC-2.5-Reward 初始化的批评模型 V 与 π/θ 一起训练,以减少策略更新的方差。
数据准备。与 [30] 中的发现类似,平均奖励分数在不同任务领域(例如,一般、文本丰富、推理)之间存在差异。这项工作的重点是提高策略模型的指令跟随和开放式聊天能力,这对于流动聊天和人机交互等现实世界的应用至关重要 [110]。同时,确保其他领域(例如,富文本、推理)的性能相对于 SFT 模型 IXC-2.5 不会降低。使用多模态偏好数据(用于训练 IXC-2.5-Reward),策划一个提示集,该提示集优先考虑一般聊天和指令遵循,同时通过包含富文本文档、数学推理和视频理解来确保多样性。
PPO。PPO 训练从提示集中采样提示开始。然后,策略 θ/π 模型生成响应,奖励模型计算时间步长 t 处每个状态 s/t 的奖励分数 r/t。给定奖励分数 r/t 和批评者模型 V,计算时间差异(TD)误差 δ/t、广义优势估计(GAE)[72] A/t 和回报 R/t,如下所示:
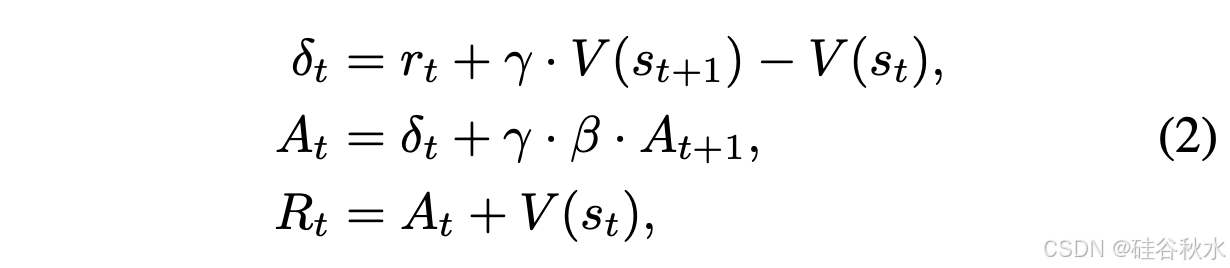
优势 A 表示策略模型的表现比预期好多少,回报 R 是累积奖励。基于优势 A,计算策略梯度损失 L/PG 来更新策略模型 π/θ:
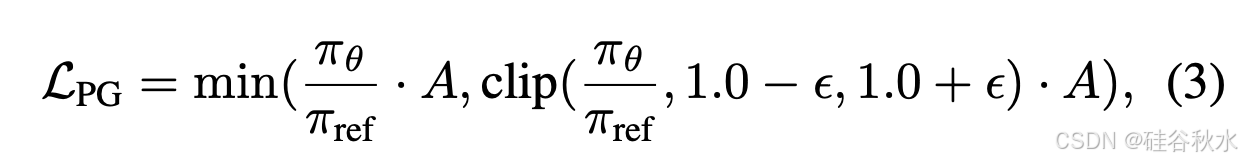
进一步通过均方误差(MSE)损失更新批评者模型,以最小化状态 V(s/t)的预测值与从状态 t 获得的实际回报 R/t 之间的差异。
IXC-2.5-Reward 用于测试-时间规模化
进一步证明 IXC-2.5-Reward 对于 LVLM 的推理-时间规模化能力至关重要。选择 Best-of-N (BoN) 采样技术,该技术通过使用奖励模型来提高生成文本的质量。具体来说,IXC-2.5-Chat 模型针对给定的提示使用不同的随机种子生成多个 (N) 不同的文本输出。随后,奖励模型 IXC-2.5-Reward 对这 N 个输出中的每一个进行评分,并选择奖励模型中得分最高的输出作为最终输出。
IXC-2.5-Reward 用于数据清理
垃圾进,垃圾出。指令调整数据集中的问题样本会对 LVLM 训练产生负面影响。虽然现有方法 [13] 使用 CLIP [69] 等分类器进行过滤,但这些方法存在局限性,尤其是对于长上下文输入 [108]、高分辨率图像或视频。如图所示,低 IXC-2.5-Reward 分数与问题样本之间存在很强的相关性,包括幻觉、空答案和不相关的图像/视频文本配对。因此,IXC-2.5-Reward 可以有效地清理 LVLM 的训练前和训练后数据。

对于 IXC-2.5-Reward的训练设置,学习率为 1e-5,批量大小为 256。对于 IXC-2.5-Chat,学习率为 5e-5,批量大小为 256。PPO 超参 γ = 0.99、β = 0.95 和 ε = 0.2。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









