







25年6月来自USC、Nvidia 和 Georgia Tech 的论文“OG-VLA: 3D-Aware Vision Language Action Model via Orthographic Image Generation”。
OG-VLA,是一种架构和学习框架,它将视觉语言动作模型 (VLA) 的泛化优势与 3D -觉察策略的稳健性相结合。其解决将自然语言指令和多视图 RGB-D 观测映射到准静态机器人动作的挑战。3D -觉察机器人策略在精确的机器人操作任务上实现最先进的性能,但在泛化到未见过的指令、场景和物体方面却遇到了困难。另一方面,VLA 擅长跨指令和场景进行泛化,但对相机和机器人姿势变化比较敏感。本文利用嵌入在语言和视觉基础模型中的先验知识来改进 3D -觉察关键帧策略的泛化。OG-VLA 将来自不同视图的输入观测投影到点云中,然后从规范正交视图渲染该点云,从而确保输入视图的不变性和输入-输出空间之间的一致性。这些规范视图由视觉主干网络、大语言模型 (LLM) 和图像扩散模型处理,生成编码终端执行器在输入场景中下一个位置和方向的图像。在 ARNOLD 和 COLOSEUM 基准测试中的评估表明,该模型在未见过环境中具有最佳的泛化能力,相对性能提升超过 40%,同时在见过环境中保持稳健的性能。
本文研究将自然语言指令和多个 RGB-D 观测值映射到机器人动作的问题,特别关注可分解为一系列末端执行器关键帧的准静态操作任务。此类任务种类繁多,例如拾取和放置、打开/关闭门和容器、操作按钮、阀门、开关等等。构建能够在未知环境中解决此类任务的鲁棒策略仍然是一项开放性挑战,它可以实现众多工业和家庭应用,从清洁和分类机器人到机器维护。
VLA 最近已成功推广到机器人训练数据中未知的概念 [1, 2, 3, 4],例如基于语言指令操作新物体。虽然在泛化方面取得了突破,但它们需要大量的训练数据集 [3, 5, 4],并且通常只接受单个 RGB 视图输入。因此,尽管训练数据量巨大,但生成的系统仍然对相机和机器人姿态的变化很敏感,这削弱了它们对新应用的适应性 [6]。它们在预测动作(通常作为 LLM tokens)时也缺乏明确的视觉推理,这限制了它们执行精确、可泛化的 3D 空间推理的能力。
相比之下,基于 3D -觉察关键帧的策略可以从少量演示中有效学习,并能很好地泛化到新的相机姿态和目标位置 [7, 8, 9, 10],Pumacay [11] 的相机扰动评估研究证实了这一点。这种成功源于模型中的 3D 场景表示,例如体素图 [7]、典型正交视图 [8] 或点云 [10]。然而,与 VLA 不同,这些系统对训练场景和物体存在过拟合,无法接受涉及新的、以前未见过目标的指令。
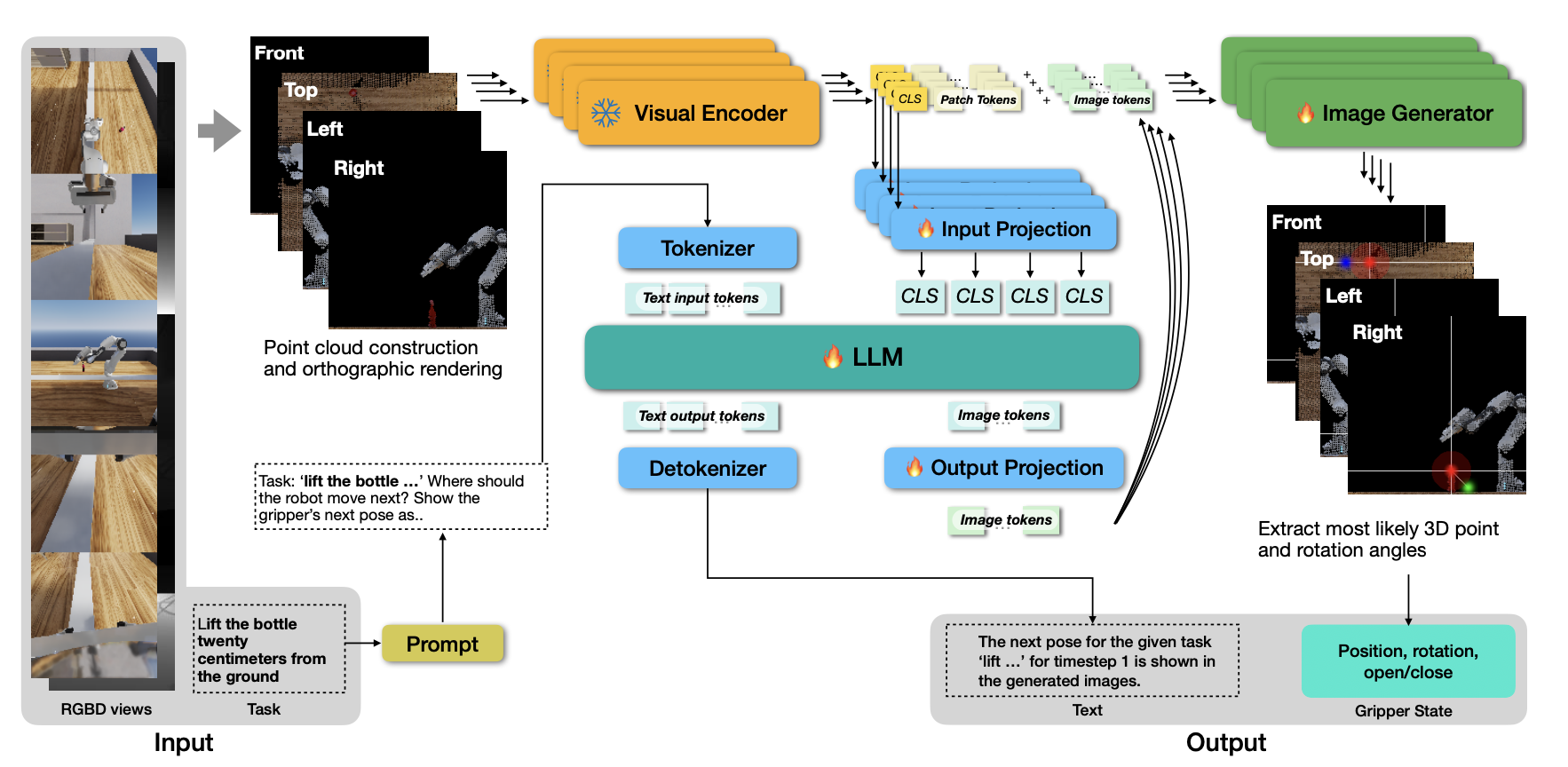
OG-VLA(正交图像生成视觉-语言-动作模型),是一种机器人策略架构,它将 VLA 的泛化优势与 3D -觉察策略的鲁棒性相结合。OG-VLA 使用 LLM 和图像生成,将已摆姿势的 RGBD 图像和语言按序列映射到 6-DOF 末端执行器姿势关键帧。该系统包含四个组件:将场景重建渲染为规范正交视图的点云渲染器、将这些视图编码为视觉嵌入的视觉主干、预测动作 token 的 LLM 以及解码这些动作 token 以通过图像生成预测每个正交视图上动作的图像扩散模型,将其解码为最终的 3D 姿势。LLM 和图像扩散模型是端到端训练的,因此它们可以协同工作以产生机器人操作所需的一致且精确的预测。如图展示整个方法:
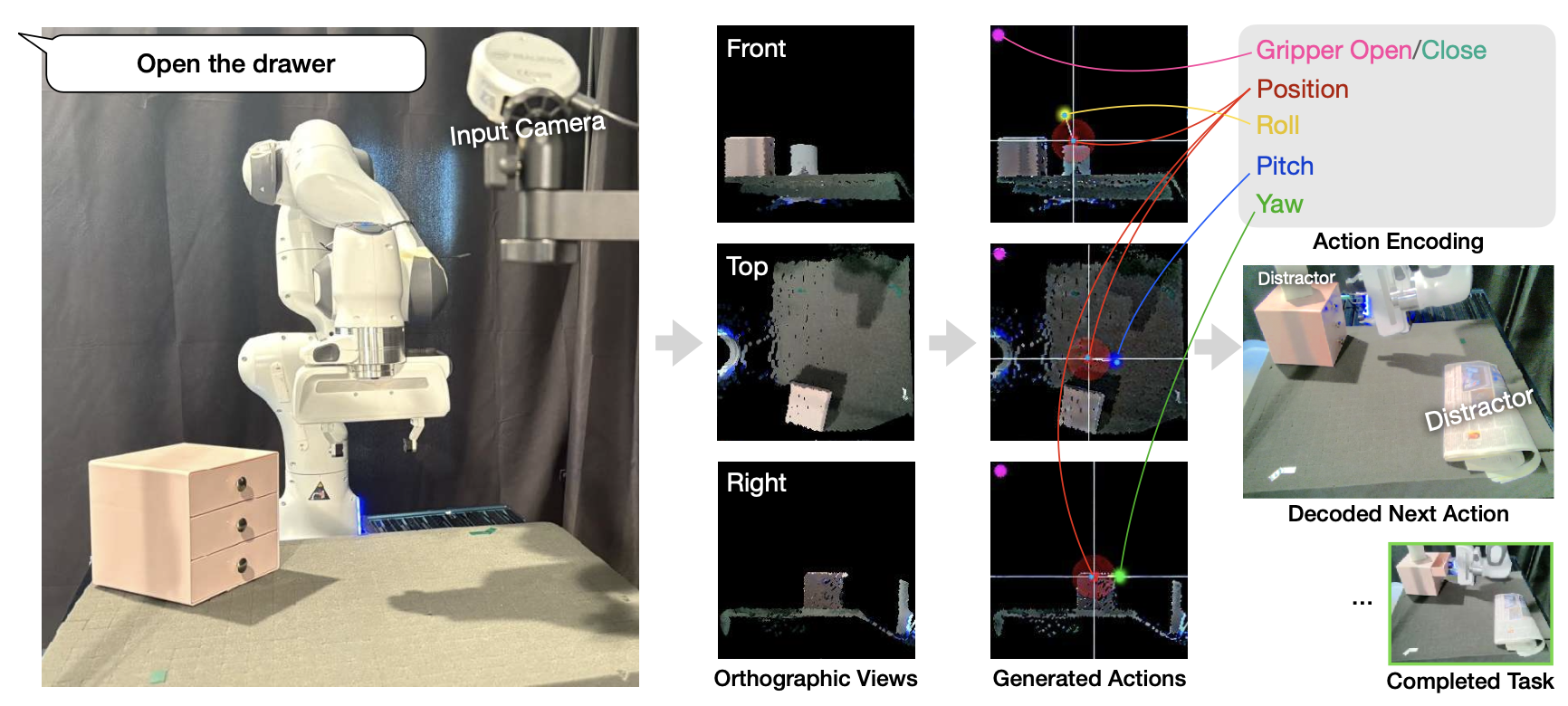
在部署时,系统的输入是一条语言指令 l,以及一组观测值 O_k = {I_k, D_k, P_k, K_k},其中 I_k 是 RGB 图像,D_k 是对应的深度图像,P_k 是相机姿态,K_k 是相机内参,相机索引为 k。系统的输出是末端执行器状态 s = ⟨p, ω⟩,它由位置目标 p 和旋转目标 ω 组成。为了完成一项任务,按顺序执行系统,在每个时间步使用运动规划器达到预测的 s,并获得下一组观测值。如图展示模型架构:
多模态视觉与语言模型
系统的核心是一个大型语言模型 (LLM)。LLM 将一系列输入token(向量)⟨t_1,…,t_i⟩作为输入,并生成一系列输出 token(向量)⟨t_i+1,…,t_i+j⟩。用三种类型的输入和输出 token:(1) 文本token,由文本 token 化器和嵌入表计算得出;(2) 输入图像 token,可以是图像块 token 或图像 CLS token [29],由视觉编码器计算得出,并通过学习的 MLP 输入投影,投影到 LLM 空间;(3) 输出图像(动作)token,将其添加到 LLM 词汇表中,并使用额外的 MLP 解码器将其解码为特殊 token。输出图像 token 代表机器人的下一个动作。用图像扩散模型,通过生成包含注释的图像将图像 tokens 解码为动作,这些注释描述夹持器在一组输入场景视图上的位置和旋转。末端执行器状态 s 是从这些图像注释中解码出来的。
基于正交投影的 3D -觉察推理
为了使 LLM 具备 3D-觉察能力,将所有输入相机图像反投影到规范工作区中的点云中。然后,从一组固定的视图(与输入相机姿态无关)渲染场景,然后再将它们输入到 LLM。这使得输入和输出位于同一空间中,并且对视图的选择(正交视图,例如“正面”、“顶部”、“左侧”、“右侧”,以正交模式渲染)确保了输出中没有歧义。
输入重投影到标准视图。对于每个具有 N_k 个有效深度像素的相机观测值 {I_k,D_k,P_k,K_k},计算一个点云 C_k,其中每个点云包含固定参考系中的 RGB 颜色和 3D 坐标。计算所有输入相机的聚合点云 C = U C_k。接下来,定义一组 m 个标准相机 {P_c^C , K_c^C},其中每个 P_c^C 代表一个相机姿态,K_c^C 代表给定正交相机 c 的内参。然后,将点云渲染为每个正交相机看到的 RGB 图像 I_c^C。
系统允许根据应用程序和工作空间几何形状调整标准相机参数集。本研究用四个正交相机,分别从前、左、右和顶部方向观察工作空间,以使工作空间填满相机图像。如上图展示输入的 RGBD 视图和生成的正交图像。虽然使用点云,但本文方法可以适应任何支持规范视图渲染的 3D 表示(例如,神经辐射场 [30, 31] 或新视图合成方法 [32])。
LLM 输入和输出。规范视图 {I_cC} 构成 VLM 系统的视觉输入。用 VISUALENCODER 处理每个视图,并获得图像嵌入(CLS token)e_cCLS,以及一系列图像块嵌入⟨e_c1, …, e_cn⟩。接下来,应用输入投影神经网络将每个 CLS 嵌入 e_cCLS 映射到与 LLM 输入空间兼容的 token t_cCLS。最后,LLM 的输入序列是以下 token序列:⟨PROMPT(l), t1_CLS, … , tm_CLS⟩,其中 PROMPT(l) 是一个函数,它为指令 l 构建一个提示符,并以与 LLM 兼容的方式对其进行 token 化。
将输入序列输入到 LLM 中,生成以下格式的输出序列:⟨t_a1, t_a2, t_a^3, t_a4, t_1^o, t_2o, . . . , t_jo⟩,其中 t_a^(·) ^是四个图像 tokens,它们共同代表下一个动作,并附带文本 token 作为对输入提示的响应。在上图中展示缩写的提示符。
用于动作预测的图像 token 解码。成功的机器人操作,例如拾取物体或抓住抽屉把手,需要非常精确的末端执行器位置预测。虽然 LLM 能够以文本形式输出抓取器姿态,并且预测结果通常较为接近,但它们缺乏实际应用所需的精度。因此,将图像 token 解码为每幅标准图像上的动作标注。根据这些标注,可以通过解码和聚合 3D 图像标注来推断下一个 3D 抓取器的位置和方向。
首先,将每个输出图像 token ti_a 投影回具有输出投影层的视觉嵌入空间,以获得一组嵌入 ei_a ;i ∈ {1, …, 4}。接下来,用这些嵌入以及 VISUALENCODER 的输出(所有块嵌入 <e1_c , … , en_c>,以及 CLS token e_cCLS)来为每个正交相机 c ∈ {1, … , m} 调节 IMAGEGENERATOR 网络。该网络输出一幅 RGB 图像,其动作预测叠加在输入的典型视图上:Hc =IMAGEGENERATOR(e^i_a, e^x_c),i ∈{1,…,4},c ∈ {1,…,m},x ∈ {CLS,1,…,256},其中 Hc 是输入典型图像 IC_c 的重建,其叠加编码夹持器位置和方向的注释。如上图所示,每幅图像都与 m 个典型输入视图 c 中的一个对齐。虽然可以使用任何图像生成器,但用 StableDiffusion 1.5 [33]。ei_a 充当文本条件,ex_c 充当 IMAGEGENERATOR 的视觉条件。实际上,用 e^i_a + CLIP(PROMPT(l)) 进行文本条件,本质上是从直接文本编码中添加残差跳连接,这是根据经验实验得出的设计选择。 CLIP 是用于预训练 StableDiffusion 1.5 模型的文本编码器。
从生成的图像中提取 3D 位置和旋转。将夹具位置和欧拉旋转生成为高斯分布,并以不同的颜色通道叠加在输入正交视图上。通过求解以下优化问题,推断出一个能够最好地解释每个正交视图中预测结果的 3D 位置 p^hm:
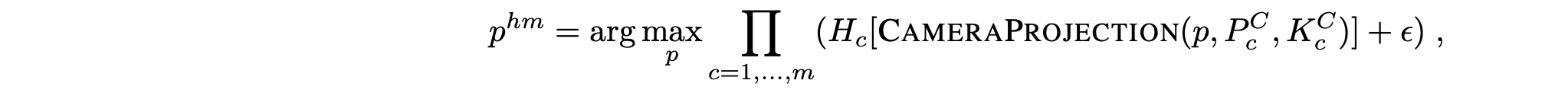
其中,CAMERAPROJECTION 将 3D 点 p 投影到相对于正交相机 c 的 2D 图像坐标上。方括号表示带有插值的 2D 像素级索引运算,以支持亚像素坐标。ε 是添加的一个小值,用于在某个热图对于所有 3D 点都为零的情况下进行解码。预测图像上的欧拉旋转,以便使用 3 种不同的颜色将沿某个轴的旋转叠加到沿该轴的正交视图上。
如上图所示,在正面视图上呈现 x 轴旋转,在左右视图上呈现 y 轴旋转,在顶视图上呈现 z 轴旋转。旋转以 30 像素为半径,参考从平移点向图像右侧绘制的水平线,以高斯分布的形式叠加。为了解码旋转先使用滤波操作,从高斯分布中提取最有可能旋转的像素位置 (r_xc,r_yc) 和平移点 (p^c_x, p^c_y),然后使用反正切函数计算旋转角度。夹持器的打开/关闭状态通过图像左上角的二进制彩色热点进行编码。
训练与实现细节
架构基于 X-VILA [34],这是一个支持语言、视觉、视频和音频模态的多模态聊天模型。OG-VLA 基于 X-VILA 的预训练权重进行初始化,以利用其任意模态对齐,专注于文本-图像输入到文本-图像输出的对齐。将使用其他模态来丰富人机交互的研究留待未来研究。用 DeepSpeed [35] 训练 OG-VLA。冻结视觉编码器,并使用端到端梯度流调整 LLM、输入和输出投影网络以及 IMAGEGENERATOR。
沿袭 X-VILA 的思路,用 ImageBind [36] 作为视觉编码器,使用线性层进行输入和输出投影,并使用 Stable Diffusion 1.5 [37] 作为 IMAGEGENERATOR。LLM 基于 Vicuna-7b v1.5 架构。 ImageBind 使用 CLS token 将图像编码为 256 个块(16×16)。每个训练样本包含自然语言指令 l、视觉观测 I_k、D_k、P_k、K_k 和真值抓取器状态 sˆ。借鉴前人研究 [7, 8],为每个关键帧增强 N SE(3) 变换后的扰动:平移方向为 [±0.1m, ±0.1m, ±0.1m],旋转方向为 [±0°, ±0°, ±90°]。所有所有模型均训练一次,LLM 经过 LoRA 微调。推理在单个 A100 GPU 上完成。对于从 Stable Diffusion 1.5 中采样的推理时间图像,用 100 个步和 7.0 的指导尺度。这些参数可以产生合理的采样图像质量,并避免模型潜在空间中采样图像的抖动。
如图所示,在安装在桌面上的 Franka Emika Panda 手臂上进行真实世界实验,该手臂配备一个前置摄像头。为 4 个真实世界任务收集 3-5 个演示(总共 22 个演示),并使用人工注释的关键帧和一个运动规划器 [40] 来获得带注释的关键帧。在这个数据集上训练基线和模型。对于模型,用 10 个 SE(3) 扰动来增强每个关键帧,并对 Arnold 预训练的 OG-VLA@30k 检查点进行另外 10k 次迭代微调,批量大小为 64。对于 π0-FAST [4] 用提供的预训练检查点,该检查点已在各种机器人设置上的超过 10k 小时的机器人数据上进行训练,动作涉及关节和末端执行器控制空间。在数据集上对其进行微调,使用关节角度动作进行 30k 次迭代,批量大小为 32,这与他们在大多数预训练和微调实验中使用的方法相同 [4, 22]。在推理过程中,该模型预测一个包含 10 个动作的动作块;为了加快执行速度,执行序列中的最后一个动作。

利用 ArUco 板,通过 MoveIt 手眼对齐系统标定摄像头。以30 Hz的帧率记录轨迹。为了训练OG-VLA,仅使用轨迹中每个带注释的关键帧动作之前的1/5轨迹,以增强每个关键帧之前的状态。

















 730
730

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









