










25.1 香港中文大学、北大和上海AI实验室的论文“Can We Generate Images with CoT? Let’s Verify and Reinforce Image Generation Step by Step”。
思维链 (CoT) 推理已在大模型中得到广泛探索,以解决复杂的理解任务。然而,这种策略是否可以应用于验证和强化图像生成场景仍然是一个悬而未决的问题。本文全面研究 CoT 推理增强自回归图像生成的潜力。其专注于三种技术:规模化测试-时间计算,进行验证、直接偏好优化 (DPO) 的模型偏好对齐、以及集成这些技术,产生互补效果。结果表明,这些方法可以有效地调整和组合,显着提高图像生成性能。此外,鉴于奖励模型在研究结果中起着关键作用,提出潜在评估奖励模型 (PARM) 和 PARM++,专门用于自回归图像生成。PARM 通过潜在评估方法自适应地评估每个生成步骤,融合现有奖励模型的优势,PARM++ 进一步引入反思机制来自我纠正生成的不令人满意的图像。使用的推理策略,可增强基线模型 Show-o,取得优异的结果,在 GenEval 基准上显著提高 24%,超过 Stable Diffusion 3 15%。
大语言模型 (LLM) [6–8] 和大型多模态模型 (LMM) [9–11] 在语言 [12, 13]、2D 图像 [14, 15]、时间视频 [16, 17] 和 3D 点云 [18, 19] 领域取得了显著成就。在一般理解技能的基础上,最近人们致力于通过复杂的思维链 (CoT) 推理能力增强 LLM 和 LMM [2, 20–22],例如 OpenAI o1 [23],这有助于在数学 [3, 24]、科学 [25, 26] 和编码 [27, 28] 方面取得优异表现。
尽管在多模态理解方面取得了成功,但多步推理策略是否可以有效应用于图像生成仍未得到充分探索。考虑到两个任务之间的差异,自回归图像生成 [5, 29–31] 的输出方式与 LLM 和 LMM 的性质相似。具体来说,其都将目标数据(语言和图像)量化为离散的 token,并迭代地预测以先前生成 token 为条件的部分内容。
规模化测试-时间计算。人类通常投入大量时间和精力来解决复杂问题。受此启发,许多研究集中于规模化大语言模型 (LLM) 的测试时间计算,以解决数学问题解决 [30、34、61、62]、代码合成 [27、63、64] 和工作流生成 [65–67] 等推理任务。一条研究路线调整输入空间以利用思维链 (CoT) 功能,使用上下文 CoT 示例 [2] 或零样本 CoT 提示 [68] 等方法。另一个分支修改或集成输出空间内的推理路径,利用自洽性 [69]、CoT 解码 [69] 和基于验证器的选择 [1、32、70] 等策略。其中,测试-时间验证器在增强推理性能方面表现出通用性和鲁棒性。例如,早期工作 [70] 训练结果奖励模型 (ORM) 来评估最终输出并选择 N 个候选中的最佳以获得最佳结果。后来,Lightman [1, 33] 采用过程奖励模型 (PRM) 来评估中间推理步骤,从而实现更高的效率。Snell [32] 进一步强调,在训练期间规模化测试-时间计算通常比规模化模型参数更有影响力。最近,OpenAI o1 [71] 在各种复杂且具有挑战性的场景中展示卓越的推理能力,凸显这种方法的潜力。
强化偏好对齐。经过强大的预训练和微调后,LLM 通常可以获得大量知识。然而,通常需要一个训练后调整阶段来调整它们的输出偏好,以满足特定目标,比如人类反馈 [72–74] 或思维链 (CoT) 推理 [34, 35, 37]。传统方法 [75–78] 通常利用强化学习 (RL) 来应对这一挑战。这些方法通常涉及两个步骤:首先,在偏好模型(例如 Bradley-Terry 模型 [79])中优化基于神经网络的奖励函数,然后使用近端策略优化 (PPO) [48] 等技术对目标 LLM 进行微调以最大化该奖励。然而,基于 RL 的方法经常遇到与复杂性和不稳定性相关的问题。为了克服这些挑战,Rafailov [46]引入直接偏好优化 (DPO),它参数化奖励模型,以便通过闭式解推导出最优策略。该方法已有效应用于增强数学推理 [34, 80] 和代码生成 [50, 81, 82] 中的 CoT 能力。进一步的进展是使用逐步的偏好数据 [35, 37] 扩展 DPO,以实现更细粒度的监督和多模态学习 [4, 83],以支持视觉推理。
自回归图像生成。具有自回归输出方案的 Transformer 架构 [7, 9, 39, 47, 51, 60] 已证明在语言和多模态方面是一种非常成功的建模方法。受此类进展的推动,一系列工作,例如 DALL-E [84]、LlamaGen [85] 和 Chameleon [55],利用这种带有随意注意机制的自回归建模来学习图像像素内的依赖关系,以用于图像生成任务,而非流行的扩散模型 [41、43、44、53、86、87]。然而,由于 VQ-VQE 压缩的离散token数量不断增加,这种光栅顺序自回归在合成高分辨率和高保真图像时会面临严重的时间消耗和性能限制 [45、88–90]。为了应对这些挑战,MaskGiT [29] 提出学习一种具有并行迭代解码策略的双向自回归Transformer,以提高生成性能和效率。最近,这种方法得到了有效的扩展,主要集中在两个方面:视觉理解和生成的统一(Show-o [5])及其与扩散技术的集成(MAR [91])。考虑到这种生成范式与 LLM 非常相似,用离散token表示数据并根据先前的token进行迭代预测,探索将 LLM 中的 CoT 推理技术应用于自递进图像生成的潜力。通过深入调查,证明其对增强图像生成能力的良好效果。
如图所示,LMM 利用 CoT 将复杂的数学问题分解为可管理的步骤,从而能够使用奖励模型 [1, 32–34] 扩展测试-时间计算,并使用强化学习进行偏好对齐 [4, 35–37]。同样,通过逐步解码的自回归图像生成可以生成中间图像,可能允许类似的验证和强化技术。这就提出一个问题:能否使用 OpenAI o1 揭示的策略逐步验证和强化图像生成?
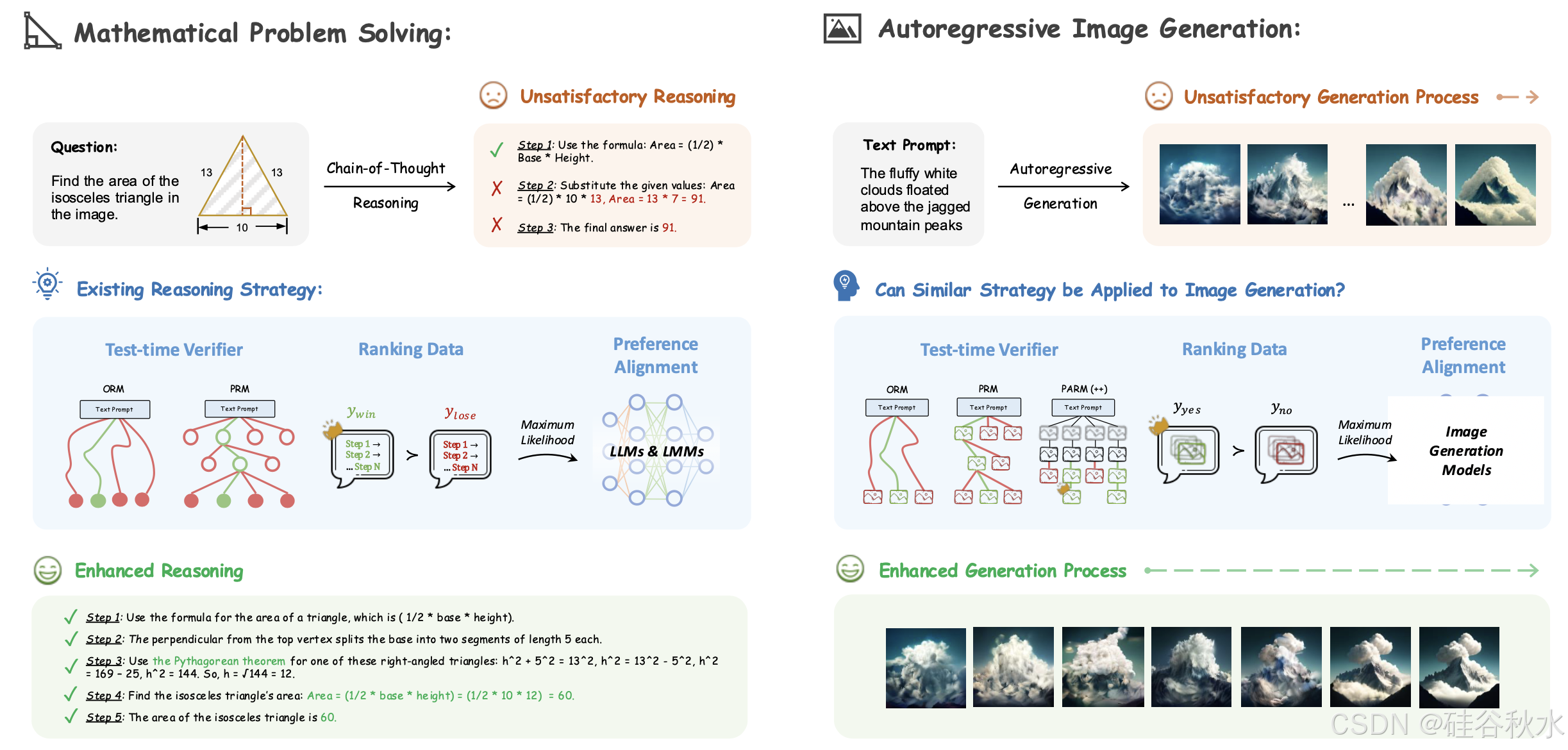
为此,本文系统地研究 CoT 推理在自回归图像生成中的潜力。采用最新的离散生成模型 Show-o [5] 作为基线,并在具有挑战性的文本-到-图像生成基准 GenEval [38] 上进行评估。
具体来说,专注于研究两个关键观点:1)使用结果/过程奖励模型 (ORM/PRM) 作为验证器扩展测试时间计算;2)通过直接偏好优化 (DPO) 强化偏好对齐。
本文专注于自回归图像生成任务,该任务由 MaskGiT [29] 和 LlamaGen [30] 等模型演示。此任务采用的数据表示和输出范式类似于 LLM 和 LMM 中使用的范式,同时实现与连续扩散模型 [42–44] 相当的性能。具体而言,它利用量化自动编码器 [45] 将图像转换为离散tokens,从而允许在训练后使用直接偏好优化 (DPO) [46] 的交叉熵损失。此外,它在每个步骤中迭代预测一个或多个tokens,以先前的输出为条件,从而创建适合使用奖励模型进行分步验证的推理路径。
实验设置。选择 Show-o [5] 作为研究的基线模型,这是一种自回归图像生成模型。为了全面评估不同的策略,在一个严格的基准上评估了文本-到-图像的生成性能:GenEval [38]。这种情况要求模型不仅要生成具有高视觉质量和图像文本对齐的图像,还要生成具有准确目标属性和共现性的图像。
ORM 与 PRM 作为测试-时验证器
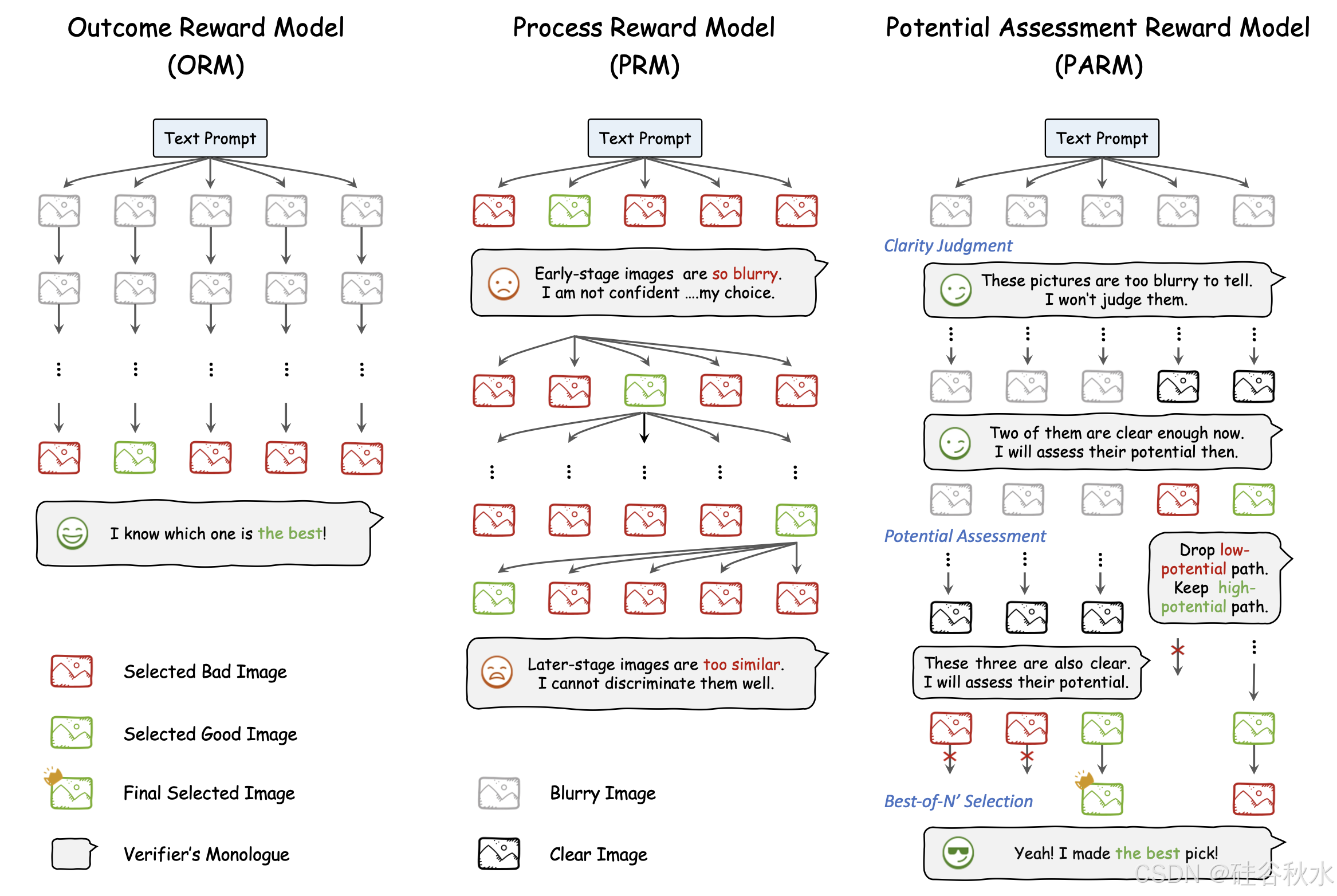
规模化测试-时计算 [1, 32–34] 以增强推理能力,已成为扩展训练成本的有效替代方案。当前的方法通常在 CoT 推理路径中使用奖励模型作为测试时验证器,通常使用两个主要类别:结果奖励模型 (ORM) 和过程奖励模型 (PRM)。受这些方法的启发,分别在自回归图像生成的背景下实现和评估它们,如图所示。
ORM
基于多个完整的推理输出,ORM 为每个候选分配一个复述分数,并使用 best-of-N 策略选择最有信心的分数。在研究中,仅采用 ORM 来评估最后一步生成的图像,而不是数学推理任务中的整个 CoT 过程。具体来说,从零样本 ORM 开始,然后整理文本-到-图像排名数据集以微调 ORM 进行增强,如下所述:
• 零样本 ORM:用预训练的 LLaVA-OneVision (7B) [39](泛化的 LMM)作为零样本 ORM。将文本提示与生成的图像一起输入到 LLaVA-OneVision 中,并设计一个提示模板以激活其视觉理解能力。该模型评估候选图像的质量,提供二元响应,“是”(质量好)或“否”(质量低)。然后选择“是”概率最高的候选图像,作为最终输出。
• ORM 排名数据管理:为了提高结果奖励的准确性,整理一个包含 288K 个文本-到-图像排名示例的数据集,用于微调 ORM。首先,提示 GPT-4 [47] 生成一个包含 200 个可数的日常目标名称和特定颜色的列表。使用这些目标,应用 GenEval 中的六个以目标为中心的提示模板,构建一组多样化的 13K 个文本提示。执行严格的过滤以确保这些提示不与 GenEval 测试样本重叠。然后,使用基线模型 Show-o,在高温设置下为每个提示合成大约 50 张图像。之后,使用 GenEval 中的评估指标为每个图像贴上“是”或“否”的二元注释。
• 微调 ORM:使用精选的排名数据集,对 LLaVA-OneVision 进行微调,以增强其评估图像质量和跨模态对齐的能力。训练数据格式与零样本 ORM 中使用的提示模板一致,并结合构建的 288K 文本提示和相关图像。该模型针对一个epoch进行微调,使用批量大小 8 和学习率为 1e-5。此微调过程使 ORM 能够捕捉目标组成的更复杂方面和细微的视觉文本关系,从而获得更可靠的评分。
PRM
与仅评估最终输出的 ORM 不同,利用 PRM 在整个生成过程中以不同的步骤为每个候选人提供奖励分数。与之前的研究类似,从零样本 PRM LLaVA-OneVision 开始,然后精选 10K 逐步的文本-到-图像排名数据以获得微调的 PRM。
测试-时间验证器和偏好对齐
后训练已广泛应用于现有的 LLM 和 LMM,以使模型输出与人类偏好保持一致。常用技术包括使用奖励模型的强化学习,例如近端策略优化 (PPO) [48],以及使用分类目标的简化版本,例如直接偏好优化 (DPO) [46]。鉴于大多数自回归图像生成模型本质上都在分类框架内运行,利用 DPO 对齐的简单性来提高生成图像的质量。
DPO 排名数据管理
为了绕过强化学习,DPO 利用隐式奖励机制,通过对成对的偏好和不喜欢的响应排名数据集进行训练,在该案例中对应于生成良好但质量较差的图像。幸运的是,已经构建大量用于训练 ORM 的排名数据,并用“是”和“否”标签注释以指示生成质量。在此基础上,利用 ORM 训练数据集中的 13K 个独特文本提示,对于每个提示,随机配对两个生成的图像,一个标记为“是”,另一个标记为“否”,从而产生 10K 个配对数据用于 DPO 对齐。
DPO 用于自回归图像生成
由于自回归图像生成模型也是使用交叉熵损失进行训练的,因此可以将 DPO 中的最大似然目标直接应用于设置。具体来说,参数化策略从 Show-o 初始化并在训练期间进行优化,而参考策略也从 Show-o 初始化但保持冻结。该目标鼓励模型为首选图像分配比不首选图像更高的似然,与策划的偏好结构保持一致。训练在一个epoch内进行,批量大小为 10,学习率为 1e-5。
DPO 迭代训练
在 DPO 对齐的初始阶段之后,该模型已经学会生成与首选响应更一致的图像。受到迭代 DPO [49] 的启发,应用新对齐的模型,根据 D 中的文本提示生成更新的排名数据,进一步完善这种对齐。同样用“是”或“否”标签注释这些新图像。对于每个提示,我们收集标记为 y/yes 和 y/no 的配对图像,并排除所有图像都收到相同标签的样本,从而得到一个包含 7K 个样本的精炼 DPO 排名数据集。通过进行另一轮 DPO,该模型可以通过从更具信息的偏好关系中学习而得到进一步改进。用相同的训练配置迭代一次 DPO 训练过程。
DPO 对齐 + 测试-时验证器
介绍三种方法整合DPO对齐和测试-时间验证器这两种技术,以评估它们在图像生成中的互补潜力,同时利用验证器的适应性和 DPO 的强化。
带有奖励模型指导的 DPO
如前文 [50] 所述,由于排名数据集的分布变化,DPO 可能会难以应对分布外(OOD)的响应。一个潜在的解决方案 [51, 52] 是在训练后合并仅提示数据集,并利用奖励模型提供在线偏好指导。按照这种方法,采用经过微调的 ORM 作为显式奖励模型来提供更通用的偏好反馈,并添加具有原始 DPO 损失的在线目标。保持与初始 DPO 对齐阶段相同的训练数据和配置。
DPO 对齐后的验证
验证和 DPO 技术可能在两个关键方面自然地相互补充:1) 它们在实施的不同阶段独立运行,即后训练和测试时;2) DPO 细化模型内部知识分布以增强推理能力,而验证则侧重于在这个细化的分布中选择最佳推理路径。因此,在 DPO 对齐后,直接在模型上应用微调后的 ORM 进行最佳 N 选择。
DPO 后使用奖励模型指导进行验证
在这种方法中,结合 DPO 与奖励模型指导和测试-时验证的优势。目标是实现最佳对齐,增强模型在训练期间的泛化能力,同时确保在推理时可靠的图像生成路径。
奖励模型通过实现解码路径选择和偏好奖励指导而证明其价值。然而,仍然有相当大的改进奖励模型的空间。
ORM 和 PRM 的局限性
- ORM 通过选择最佳最终输出展示了强大的性能,但它缺乏在每个生成步骤提供细粒度、逐步评估的能力。 2) 虽然 PRM 在理解数学等任务方面已证明是有效的,但它不太适合自回归图像生成。由于只有少数区域被解码,PRM 在处理早期图像时会遇到困难,因为这些图像太模糊而无法进行可靠的评估。在后期阶段,从类似的先前步骤中得出的图像缺乏足够的区别,这对 PRM 的区分提出挑战。
PARM
提出潜在评估奖励模型 (PARM),这是一种专门为自回归图像生成量身定制的奖励模型,如上图所示。PARM 结合了两全其美的优势:1) 它以逐步的方式自适应地运行,使用潜在评估机制来克服 PRM 的评估挑战;2) 它在 N ′ 个(N ′ ≤ N )高潜力推理路径中执行 N ′ 中最佳的选择,从而继承 ORM 的优势。具体来说,PARM 的方法包含三个渐进式任务:
- 清晰度判断。在 N 中最佳的设置中,、、、首先对 N 个不同的推理路径进行采样以生成图像。然后,在每个中间步骤,PARM 评估部分生成的图像是否包含足够的视觉清晰度以进行有意义的评估,并分配二进制标签。如果标记为“否”,模型将跳到下一步。如果标记为“是”,模型将继续进行下一个任务以进行潜在评估。这种预先判断可以防止对缺乏信息内容的早期模糊图像进行评分(如 PRM 中所示),从而确保只有足够清晰的步骤才会被考虑用于奖励。
- 潜力评估。对于通过清晰度判断的每个清晰步骤,PARM 都会评估当前步骤的潜力,以确定它是否可以产生高质量的最终图像,同样使用二进制标签。如果标记为“否”,则立即截断生成路径。如果标记为“是”,则保留路径以生成最终图像。这种方法基于这样的观察:一旦给定步骤中的图像足够清晰以进行评估,其整体布局和结构就不太可能在后续步骤中发生显着变化,使其成为潜力评估的可靠候选。此任务有助于识别有希望的中间步骤,从而在推理过程中有效地修剪低潜力的候选。
- 从 N ′ 中选择最佳。完成上述两个任务后,假设剩余 N′ 条高潜力路径来生成最终图像(N′ ≤ N)。然后,PARM 执行 N′ 中最佳选择,以确定最有希望的图像候选作为输出。如果 N′ = 0,则模型默认选择具有“否”标签概率最低的推理路径作为输出。这项最终任务利用 ORM 的全局选择功能来确保生成高质量的图像。
PARM 排名数据管理
为了赋予 PARM 强大的功能,重新注释 ORM 排名数据中 13K 文本提示,管理一个包含 400K 个实例的新排名数据集。数据集分为三个子集,分别包含 120K、80K 和 200K 个实例,分别对应三个评估任务。
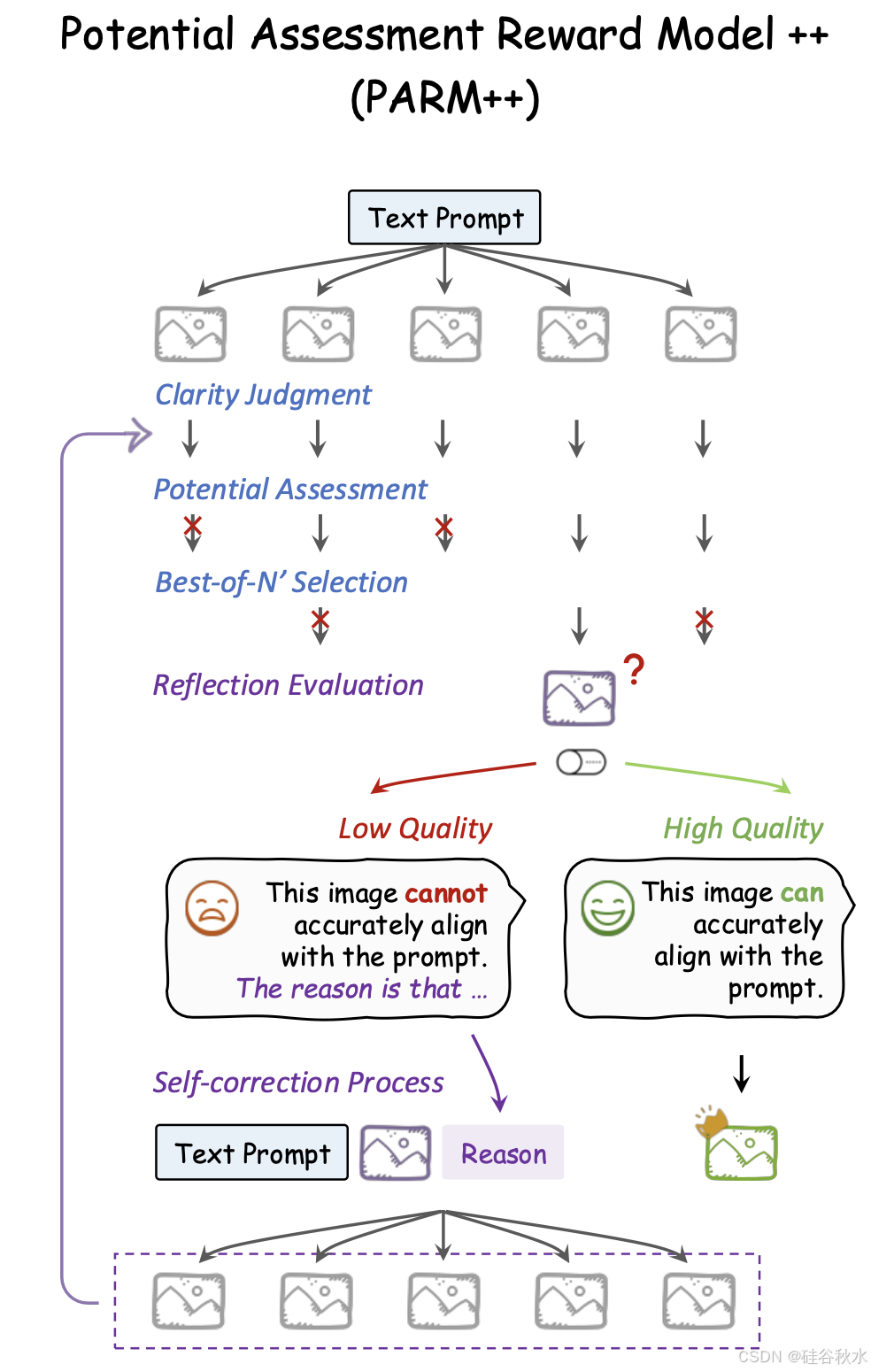
除了循序渐进的推理之外,人类还经常进行反思过程来验证他们之前的想法是否正确。为了探索其在图像生成中的潜力,引入 PARM++,如图所示,它通过反思机制增强 PARM,以改进文本-到-图像的质量。
图像生成中的反思
反射策略最近也应用于 LLM [58, 59],通过自我纠正提高性能。与可以生成和解释自由格式语言来审查和改进其输出 LLM 不同,图像生成模型通常依赖文本提示(通常是描述性的而不是指导性的)作为输入,并且仅输出图像模态。因此,反思能力必须主要由外部奖励模型处理,该模型的任务是识别错位并提供解释。此外,图像生成模型本身也需要进行微调,以有效理解和响应这些反思文本以进行自我纠正。
从 N′ 个图像候选中选择出最佳输出后,PARM++ 会整合一个反射评估任务,检查最终图像与输入文本提示之间的对齐情况。如果图像满足对齐标准,PARM++ 会输出“是”并将其视为最终结果。否则,它会对差异进行详细分析,包括图像与提示之间错位的具体原因。然后,将三个输入输入到图像生成模型中,以自我校正其图像输出,包括原始文本提示、先前生成的次优图像和已识别的错位原因。这个迭代细化过程一直持续到 PARM++ 在反思评估中得出“是”的结果,从而逐步提高视觉保真度和图像与文本的对应性。本文反思迭代的最大次数设置为 3。
PARM++ 排名数据管理
在用于 PARM 的 400K 数据集的基础上,为反思评估任务另外准备 120K 个实例,从而为训练 PARM++ 产生总共 520K 个数据点。对于负样本数据,从 ORM 排名数据集中选择标记为“否”的样本,代表需要改进的低质量图像,并利用 GPT-4o [60] 提供简洁的注释,详细说明图像与文本的差异。对于正样本数据,直接利用 ORM 排名数据集中标记为“是”的样本,代表通过反思评估的高质量图像。数据集中负实例与正实例的比例约为 80%:20%。
自我修正微调
由于基线模型(例如 Show-o)未经过预训练以根据文本指令改进低质量图像,因此专门对 Show-o 进行微调,使其具有自我修正生成图像的能力。幸运的是,Show-o 支持同时输入文本和图像,从而能够通过文本反馈引导图像细化。为了整理训练数据,从 PARM++ 排名数据集中提取 10K 个实例组。每个组由一个文本提示、一个低质量(负面)图像、一个高质量(正面)图像和带注释的反思原因组成。此数据集用于微调 Show-o 以进行迭代图像细化,逐步提高生成图像的质量和对齐方式。
如图所示不使用(上)和使用(下)本文推理策略的自回归图像生成。采用 Show-o [5] 作为基线模型,其文本-到-图像生成效果不理想。在使用本研究的推理策略(将 PARM 与迭代 DPO 相结合,用于奖励模型指导和测试时验证)后,生成过程得到了有效增强。

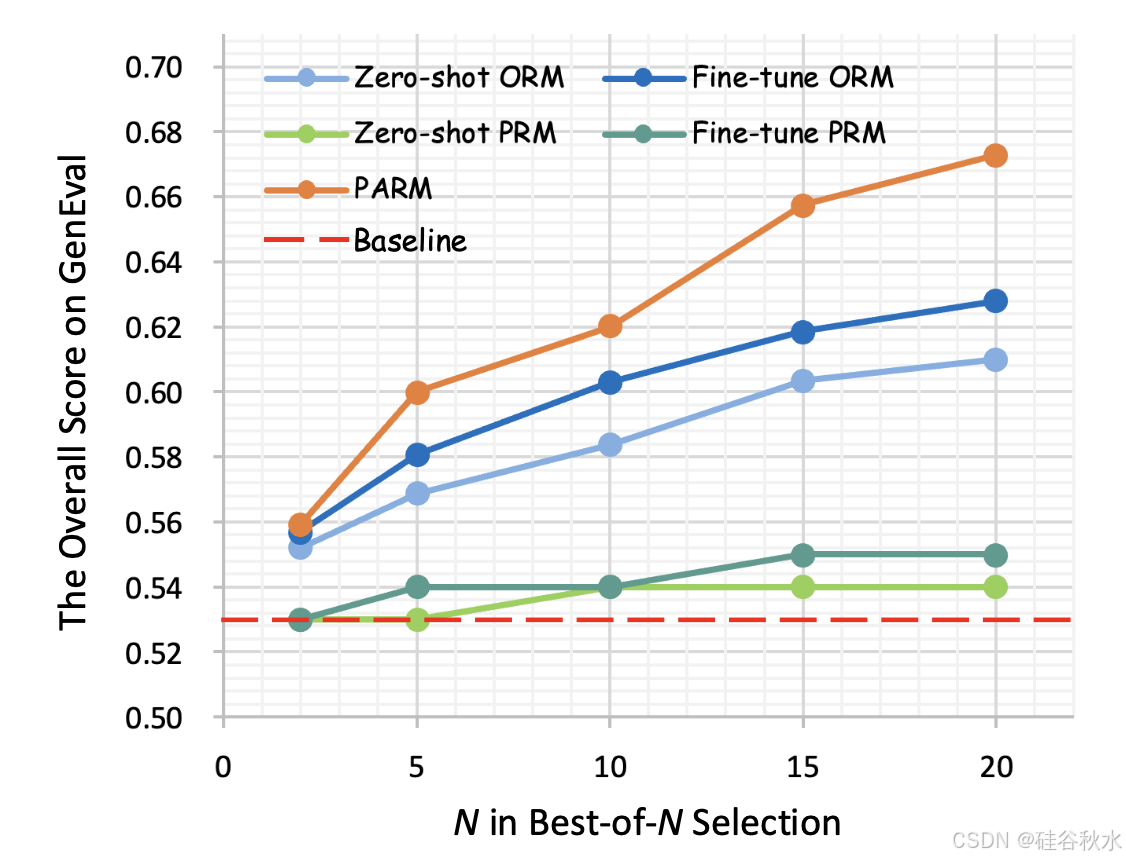
如图所示作为测试-时验证器的奖励模型比较。用 Show-o [5] 作为“基线”,并在 GenEval [38] 基准上评估 Best-of-N 选择。
最后如图所示PARM++ 中的反思定性结果。所提出的 PARM++ 结合反思评估阶段来检测文本-图像错对齐,并提供详细的解释来指导自回归图像生成模型中的自我校正过程。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









