










25年2月来自牛津大学的论文“Agentic Reasoning: Reasoning LLMs with Tools for the Deep Research”。
本技术报告介绍智体推理(Agentic Reasoning),这是一个通过集成外部工具使用智体来增强大语言模型 (LLM) 推理的框架。与仅依赖内部推理的传统 LLM 推理方法不同,智体推理动态地参与网络搜索、代码执行和结构化推理上下文记忆,以解决需要深入研究和多步逻辑推理的复杂问题。该框架引入思维图智体(Mind Map agent),它构建一个结构化知识图来跟踪逻辑关系,从而改进演绎推理。此外,网络搜索和编码智体的集成实现实时检索和计算分析,提高推理准确性和决策能力。对博士级科学推理 (GPQA) 和特定领域深入研究任务的评估表明,该方法明显优于现有模型,包括检索增强生成 (RAG) 系统和闭源 LLM。此外,结果表明,智体推理可以提高专家级知识综合、测试-时间可扩展性和结构化问题解决能力。代码位于:https://github.com/theworldofagents/Agentic-Reasoning。
最近,大型推理模型,例如 OpenAI o1(Jaech,2024)、Qwen-QwQ(Team)和 DeepSeek-R1(Team,2024),通过大规模强化学习展示对长序列进行逐步推理能力。这些进步为复杂的推理任务提供有希望的解决方案(Wei,2022;Lewkowycz,2022;OpenAI),并启发基础性努力,以在更广泛的模型中复制类似 o1 的推理模式(Qin,2024;Huang,2024;Zhang,2024)。
例如,DeepSeek-R1 在训练期间完全依赖基于规则的结果奖励,例如评估数学解决方案是否正确或一段代码是否成功执行。虽然这种方法产生非凡的推理能力,与 o1 在数学和代码等领域的表现相当,但它也带来明显的权衡。正如作者所承认的,这种类型的训练削弱模型表达其推理过程的能力。DeepSeek-R1 的响应通常合乎逻辑且准确,但缺乏对思维之间转换或论点之间更精细联系的详细解释。
虽然当前的推理方法在数学和代码等结构化领域表现出色 - 结果很容易验证 - 将这些技术应用于结构性较差或主观性较强的任务仍然是一项重大挑战。将这些策略应用于答案本身并不明确的领域,是一个关键的研究空白。如何训练模型来处理需要判断、解释或细微理解而不是二进制正确性的任务?
此外,并非所有问题都能从形式推理方法中受益。许多领域,如社会科学、伦理学或经验学科,都依赖于抽象概念、传统智慧、事实验证、理解复杂的逻辑关系或道德推理。当模型试图将数学或编码式推理强加到这些领域时,它们往往会产生有缺陷或过于僵化的结果。开发能够满足这些独特要求的方法,对于提高推理模型在当前领域的适用性至关重要。
对开放式问题的深入、深思熟虑的回答通常需要广泛的研究、反复的验证、信息检索、计算分析和复杂逻辑关系的组织——这是人类推理的基本步骤。在这个过程中,人类严重依赖外部工具,例如用于收集信息的互联网搜索、用于定量分析的计算工具、或用于组织思想的白板和思维图。这就提出一个有趣的问题:大语言模型能否同样利用外部工具来增强其推理能力并解决跨不同领域的密集知识工作?
先前的努力已尝试将搜索或检索增强生成 (RAG) 集成到推理过程中(Shao,2024;Khaliq,2024;Islam,2024;Li,2025),其中著名的例子包括 Gemini 的 Deep Research。然而,这些模型是封闭的,其确切方法仍未公开。相比之下,开源模型通常专注于推理过程中的检索或网络搜索,与闭源模型相比,其性能存在显著差距。
智体推理,是一种通过集成外部 LLM 智体作为工具来增强推理过程的框架。这种方法使 LLM 能够执行多步骤推理,并通过将特定任务委托给这些辅助智体来更有效地解决复杂问题。
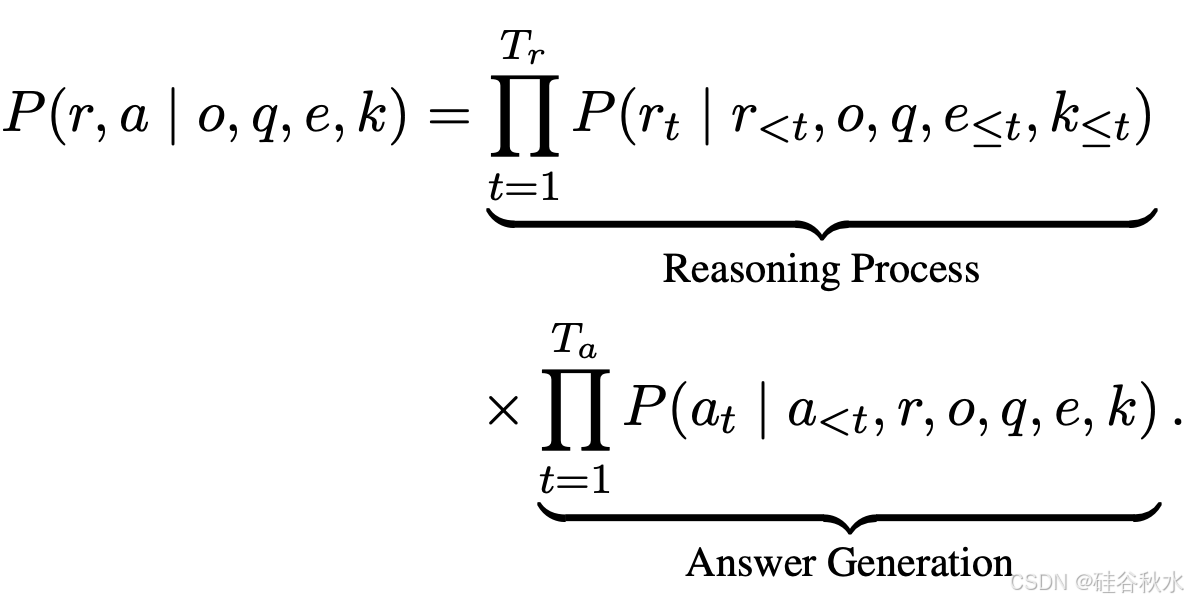
考虑一个需要多步骤复杂推理的专家级任务。在模型推理过程中,它可以检索外部工具的使用情况,以及先前推理的结构化记忆。目标是为每个查询 q 生成一个逻辑推理链 r 和一个最终答案 a。为了实现这一点,推理模型会动态地与外部工具 e(通常是网络搜索和 Python 编码)交互,并在整个推理过程中从有组织的记忆 k 中检索结构化知识。
正式地,在问题解决流水线中确定四个主要输入:任务指令 o,定义总体任务目标,查询 q,需要多步骤推理的复杂问题,外部工具输出 e,从网络搜索或编码等工具中动态检索的内容,推理记忆 k,包含结构化知识图。
目标是整合 o、q、e、k 以生成连贯的推理链 r 和最终答案 a。该过程可以表示为映射:(o,q,e,k)→(r,a)。
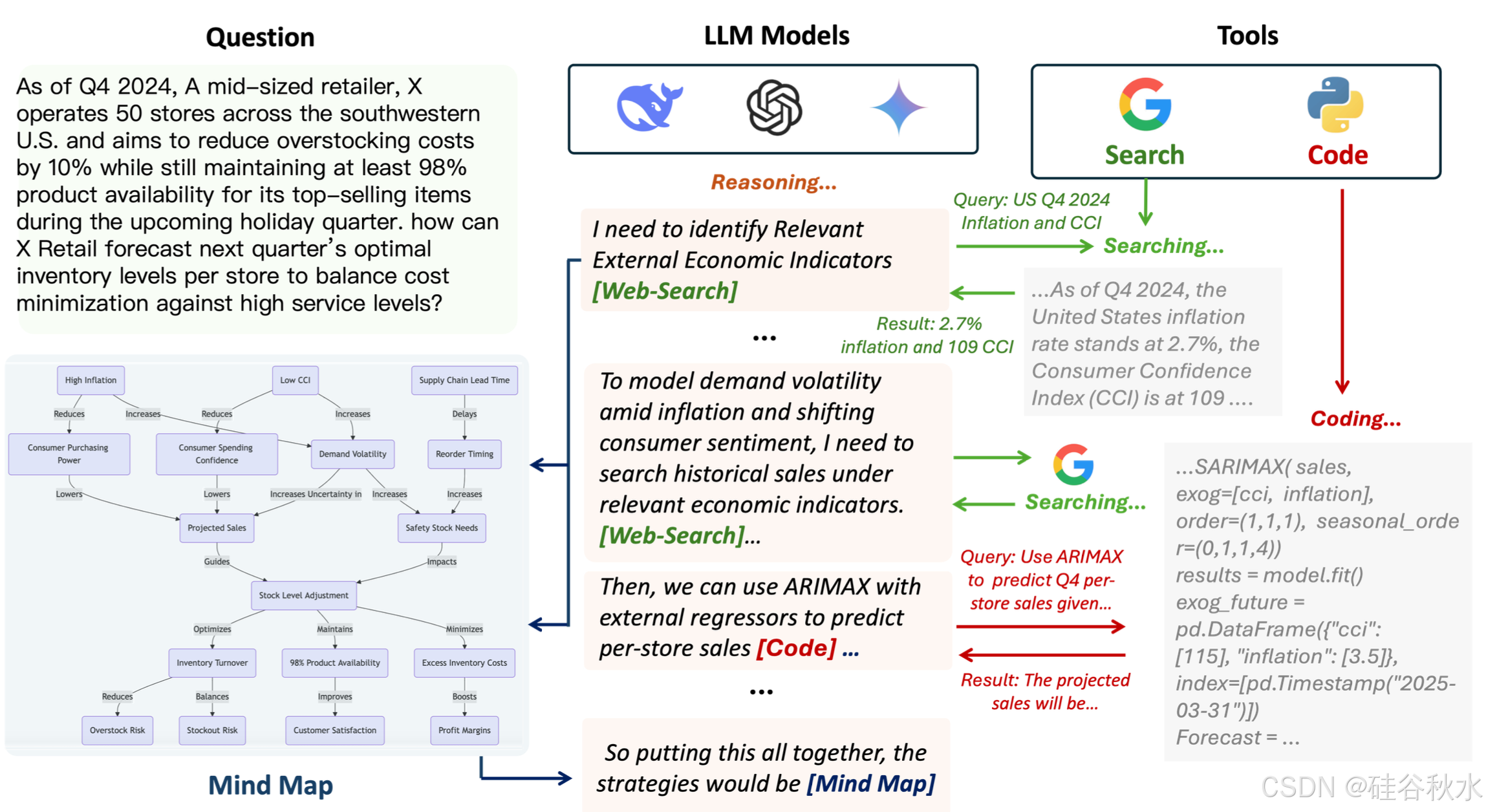
如图所示:智体推理的总工作流
用以下联合概率公式对 r 和 a 的生成进行建模:
核心思想是在推理过程中部署基于外部 LLM 智体来增强模型推理能力。该框架使推理 LLM 模型能够以智体方式与外部信息交互。在推理过程中,它可以调用外部工具来帮助解决问题,也可以使用称为思维图的结构化记忆来存储其推理上下文。从本质上讲,智体机制使模型能够实时确定何时需要更多信息。每当模型在推理过程中识别出需要外部信息时,它就会主动将专门的token嵌入其推理token中。这些token通常可以分为网络搜索token、编码token和思维图调用 token。除了token之外,推理模型还会根据迄今为止开发的推理上下文,生成精确的查询作为消息,与这些外部智体进行交互。
在检测这样的token后,推理过程会暂时停止,以提取查询及其推理上下文。然后,它们被发送到外部智体(例如搜索引擎或思维图)以生成相关内容。生成过程会同时考虑收到的消息和推理上下文,以确保返回最相关的结果。然后,这些结果将重整到推理链中,使模型能够使用更新和丰富的知识继续推理。
这种迭代检索和推理循环根据需要继续进行,使模型能够动态地完善其结论,直到得到完全合理的最终答案。
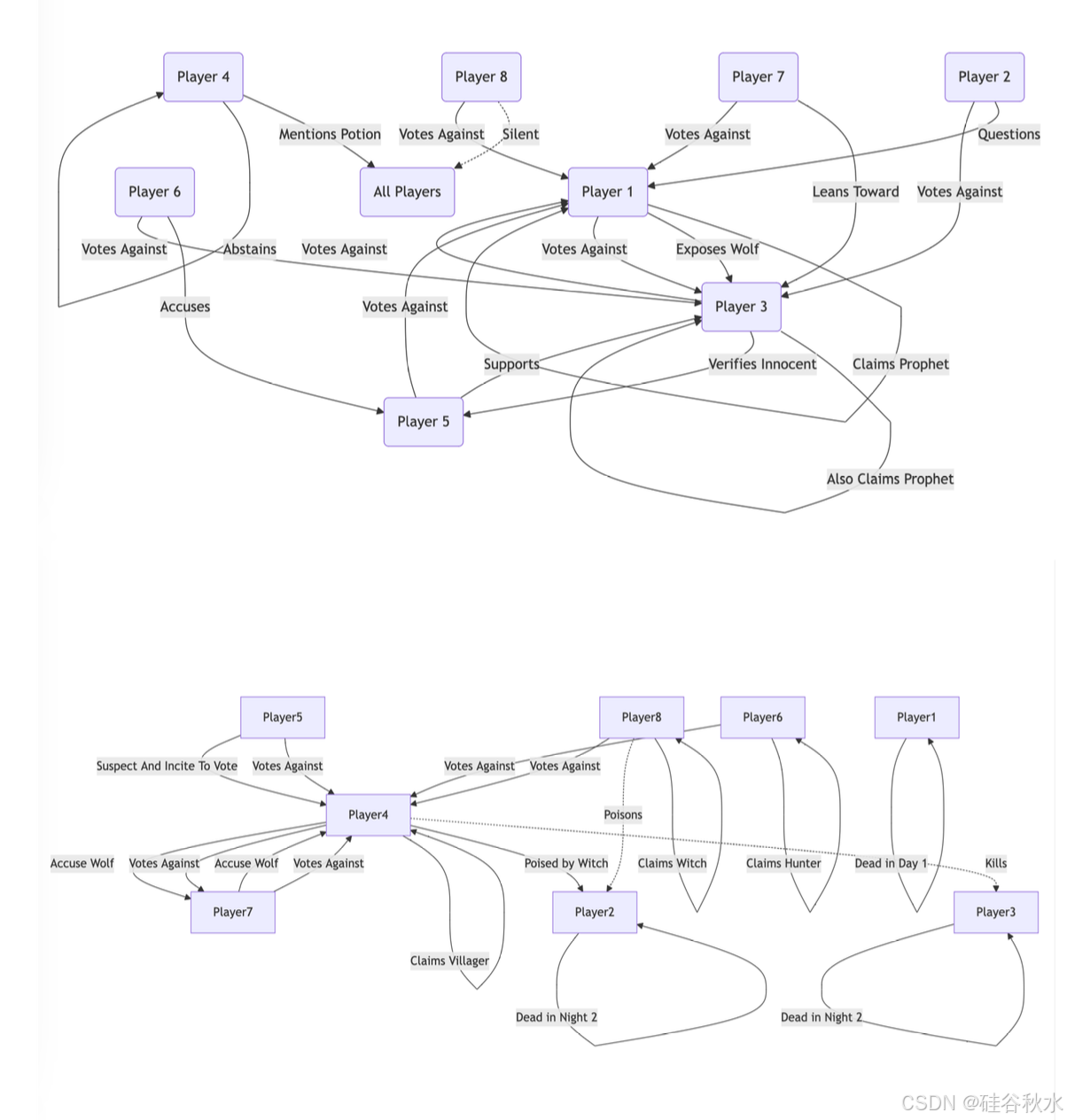
构建一个思维图来存储和构建推理模型的实时推理上下文。该思维图是通过将原始推理链转换为结构化知识图谱来构建的。具体而言,用图-构造 LLM 从推理链中提取实体并识别相关实体之间的语义关系,其过程类似于 GraphRAG 中使用的过程(Edge,2024)。
思维图有两个主要功能。首先,它将推理上下文聚类为不同的组并总结每个主题。这是通过在知识图谱上应用社区聚类(Edge,2024)并使用 LLM 为每个组生成简明摘要来实现的。其次,可以使用特定问题查询知识图谱,例如“杰森的曾祖父是谁?”使用知识图谱上的标准检索增强生成 (RAG)(Edge,2024),检索并返回相关信息。
这些功能将思维图集成到智体推理过程的各个方面。它为外部工具提供上下文推理支持,使它们能够生成更多上下文感知响应。此外,当推理模型对其声明不确定或在扩展推理过程中迷失方向时,它可以查询思维图以获取相关信息,将其视为外部工具,并根据检索的答案继续推理。
如图所示:游戏智体推理中思维图
调用搜索智体从网络上检索最相关的文档。这些网页不会被以原始形式合并,而是被暂时保存以备进一步处理。这确保只提取最相关的信息并将其集成到主推理链中,从而保持连贯性和相关性。
搜索智体检索相关网页后,用 LLM 提取与当前推理上下文最相关的内容简明、重表述的摘要。此智体在用户查询和推理上下文中处理网页,蒸馏出可直接应用于当前问题的关键见解。摘要的格式和长度会根据推理任务动态调整,例如,对于“2024 年美国人口是多少?”这样的事实查询,结果将是一个简单的数字答案。对于像寻找主题的新视角这样的探索性推理,搜索智体将提供总结性的、详细的、细致入微的观点。对于假设验证,例如评估假设的支持证据,结果将包括在检索到的网页中发现的支持或矛盾程度。然后,在适当的时刻,将经过处理的片段集成到主要推理过程中,确保外部见解增强而不是破坏逻辑流程。
与直接提示推理模型生成代码相比,将编码任务委托给专门的编码 LLM 更有效。推理模型将相关上下文和查询消息发送给编码 LLM,然后编码 LLM 编写所需代码,通过编译器执行并返回结果。这种方法确保推理模型专注于其核心推理过程,而不会受到编码任务的干扰,从而实现更长、更连贯的推理链。具体来说,将编码请求格式化如下:“编写代码以执行<推理模型的代码消息>,给定上下文 <思维图中的推理上下文> 来回答查询 <用户查询>。”编码 LLM 被指示始终以自然语言返回其输出,确保与推理模型无缝集成。
少即是多。与为模型提供大量外部工具的一般智体框架不同,仅需两种外部工具(网络搜索和编码)就足以完成大多数任务,即使是那些需要专家级熟练程度的任务。添加更多工具可能会降低性能,因为会增加工具选择不当的风险。此外,外部工具输出的不准确性会对整体响应质量产生负面影响。虽然额外的工具对基于语言的推理没有显著的好处,但它们对于处理非文本模态(如财务数据、医学图像和遗传数据)至关重要。为不同数据模态开发专门的工具可以进一步增强 LLM 推理能力,将在未来的更新中探索相关结果。
在多个基于 LLM 智体之间分配计算工作负载可提高效率。不是让主推理模型处理所有与工具相关的任务(例如,编写代码或构建知识图谱),也不是调用非 LLM 工具(如纯搜索引擎或代码编译器),而是将这些任务委托给专门的基于 LLM 智体,例如,编码 LLM 根据主推理模型的查询和上下文生成代码,或者知识图谱 LLM 从推理链构建结构化表示(例如,思维图)。这种方法有两个主要优点:1. 最大限度地减少中断。主推理模型可以保持更长、更连贯的推理,而不会被辅助任务分散注意或超出token限制。2. 利用专业化。不同的 LLM 擅长不同的任务 - 例如,DeepSeek-R1 专注于推理,而 Claude-Sonnet 擅长编码。通过将任务分配给最适合它们的模型,可以实现更高的整体性能。
对于单个问题,用更多工具调用的推理链往往会产生更好的结果。而在不同的问题中,那些需要过度使用工具的问题往往表明初始推理中存在固有的歧义或不准确性。这种洞察力可以用作测试-时间推理验证器。通过选择工具使用率最高的推理链,可以实现最佳 N 选择或定向搜索,这些技术通常用于数学和编码推理任务,因为它们可以轻松构建验证器,到开放域、知识密集型问答,提高准确性和稳健性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









