










25年2月来自清华、上海姚期智研究院、上海AI实验室、UC Berkeley 和 UCSD 的论文“Video2Policy: Scaling up Manipulation Tasks in Simulation through Internet Videos”。
模拟为通才策略提供一种廉价的规模化训练数据的方法。为了可扩展地从多样化和现实的任务中生成数据,现有的算法要么依赖于大语言模型 (LLM),这可能会产生机器人不感兴趣的任务;要么依赖于数字孪生,这需要仔细的真实-到-模拟对齐并且难以规模化。为了应对这些挑战,引入 Video2Policy,这是一个利用互联网 RGB 视频根据日常人类行为重建任务的框架。该方法包括两个阶段:(1) 从视频中在模拟中生成任务;(2) 迭代利用上下文 LLM 生成奖励函数进行强化学习。通过重建 Something-Something-v2 (SSv2) 数据集中的 100 多个视频来证明 Video2Policy 的有效性,该数据集描绘 9 种不同任务上的多样化和复杂的人类行为。该方法可以成功地在这些任务上训练 RL 策略,包括投掷等复杂且具有挑战性的任务。最后,生成的模拟数据可以扩大以训练通用策略,并且可以以 Real2Sim2Real 的方式将其迁移回真实机器人。
训练通才策略需要收集大量不同的机器人专家数据。然而,通过遥操作收集数据受到高操作成本的限制,而从自主策略收集数据可能不安全,或导致数据质量低下。模拟为现实世界数据提供一种有吸引力的替代方案,它不会受到这些挑战的影响,并且可以用来训练通用和稳健的策略(Hwangbo,2019;Andrychowicz,2020)。最近的研究探索在模拟中自动生成多样化和相关的任务,以此作为创建可扩展的机器人数据生成流水线的方法(Deitke,2022;Wang,2023b;c;Makatura,2023)。
然而,现有的方法主要依赖于使用大语言模型 (LLM) 的纯文本任务规范,而这些模型没有扎实的机器人知识。它们通常会产生缺乏多样性、行为无趣或使用无趣的目标资产的任务,因此对于训练通才策略不太有用。为了更好地捕捉任务行为和目标在现实世界中的分布,利用互联网上的 RGB 视频来创建相应的任务。与为单个场景构建数字孪生的 Real2Sim 方法(Hsu,2023;Torne,2024)不同,这是为多个场景训练通才策略,因此不需要完美的重建。相反,利用大量互联网视频来捕获与任务相关的信息,例如目标资产和场景布局。然后,用视觉语言模型 (VLM) 生成模拟任务,该模型可以获取视频、视频字幕、目标网格、大小和 6D 姿势,并生成相应的任务代码,执行这些代码即可生成场景。
除了任务提议之外,还需要一种高效且自动化的方法来解决任务。单纯地应用强化或模仿学习是具有挑战性的,因为它需要人工为每个任务创建演示或奖励函数。受到 LLM 在各种任务代码生成方面的最新进展启发(Achiam,2023;Roziere,2023),一些研究人员提出通过使用 LLM 直接生成策略代码(Huang,2023b;Liang,2023;Wang,2023b)或生成奖励函数代码(Ma,2023;Wang,2023c)来实现策略学习或部署的自动化。Gensim(Wang,2023b)利用这个想法进行无监督任务生成。然而,预测目标将其限制在简单任务上,因为它不考虑动态任务或涉及复杂目标交互的任务。
相比之下,强化学习 (RL) 可有效解决复杂任务(Schulman,2017;Ye,2021;Hafner,2023;Wang,2024;Springenberg,2024)。RoboGen(Wang,2023c)利用 LLM 生成的奖励函数进行 RL。但是,由于它需要手动成功函数,因此很难扩展。
机器人的 Real2Sim 场景生成。为机器人生成真实而多样的场景最近已成为一项重大挑战,旨在通过模拟解决数据问题。一些研究人员已经开发用于图像-到-场景或视频-到-场景生成的 Real2Sim 流水线。某些研究(Hsu,2023;Torne,2024)专注于构建数字孪生,以促进从现实世界-到-模拟的过渡;然而,这些方法通常依赖于特定的现实世界扫描或大量的人工协助。(Dai,2024)引入数字表亲的概念,而(Chen,2024)采用逆图形学来增强数据多样性。然而,他们实现多样性的方法主要涉及替换各种资产。任务级多样性的缺乏阻碍捕捉现实世界任务分布的能力,特定数据格式的限制,使机器人数据的可扩展性变得复杂。尽管 Real2Code(Mandi,2024)旨在从图像构建模拟场景,但它专注于关节部分,并且需要域内代码数据。
规模化模拟任务。以前,研究人员的目标是构建模拟基准,以促进可扩展的技能学习和标准化工作流程(Li,2023;Gu,2023;Srivastava,2022;Nasiriany,2024 年)。大多数这些基准都是手动构建的,因此难以扩展。最近,一些研究人员专注于文本到场景的生成,强调创造多样化的场景。诸如 (Deitke,2022;Makatura,2023;Liang;Chen,2023) 之类的方法利用程序资产生成或域随机化,而 (Jun & Nichol,2023;Yu,2023a;Poole,2022) 则从事文本-到- 3D 资产生成。尽管这些方法可以在机器人任务中实现资产级或场景级多样性,但它们在提供任务级多样性方面却不足。Gensim (Wang,2023b) 尝试使用大语言模型 (LLM) 生成丰富的模拟环境和专家演示,以实现任务级多样性。但是,基于文本的任务生成,在目标选择及其关系方面往往具有任意性,从而限制了其表示现实世界中任务真实分布的能力。
通过 LLM 进行策略学习。为了实现高质量的自动策略学习,研究人员越来越多地求助于大语言模型 (LLM)。一些研究 (Liang et al., 2023; Huang et al., 2023a; Lin et al., 2023; Wang et al., 2023a) 建议为决策问题生成结构化代码输出,其中大多数依赖于预定义的原语。其他工作 (Yu et al., 2023b; Ma et al., 2023; Wang et al., 2023c) 使用 LLM 为强化学习生成奖励函数。尽管如此,Eureka(Ma,2023)需要预定义成功函数来迭代更新奖励函数,而 RoboGen(Wang,2023c)选择最高奖励作为下一个子任务的初始状态,这会由于生成的奖励函数变化而引入噪音。
本文提出框架 Video2Policy,进一步通过互联网视频进行任务提议和策略学习,以提供多样化和逼真的任务以及相应的学习策略。它包括两个阶段:任务场景生成和策略学习。如图所示:
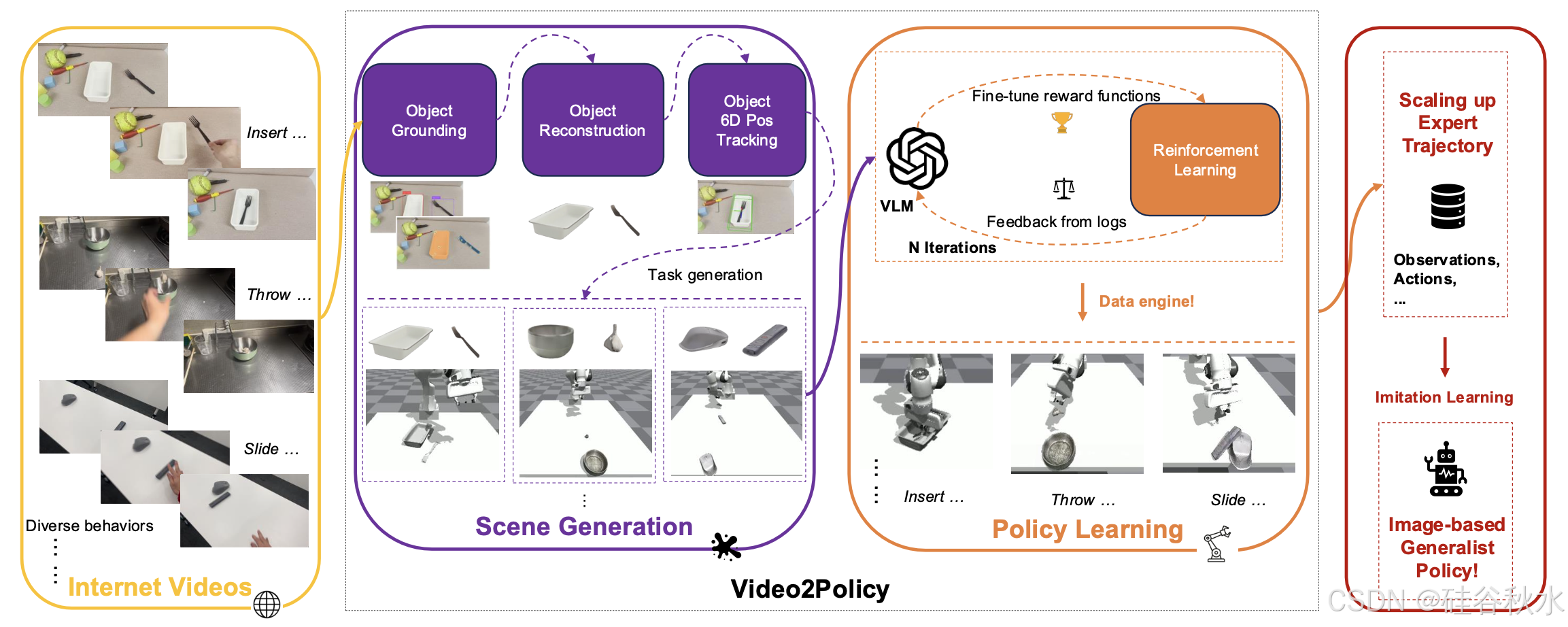
由于这项工作的目标是从视频中学习策略而不是自动重定位轨迹,场景重建阶段专注于重建被操纵的目标及其相对关系。为了掌握视频中展示的技能,允许每个目标在初始状态下随机定位和定向。步骤如上图所示:(1)使用文本字幕检测和分割视频中被操纵的目标;(2)从视频中重建目标网格并估计网格的实际大小;(3)对视频中的每个目标执行 6D 位置跟踪。之后,获得一个包含视频和目标信息的 JSON 文件。
目标落地。首先使用 Grounding DINO(Liu et al., 2023)检测视频第一帧中的被操纵目标。由于 SSv2 数据集(Goyal et al., 2017)同时提供视频字幕和目标标签,将它们用作检测的文本提示。对于更具挑战性行为的自采集视频,手动提供视频字幕和目标名称。之后,用 SAM-2 模型 (Ravi et al., 2024) 执行视频分割。具体而言,使用检测过程中获得的边框对第一帧中的目标进行分割,并在每个目标掩码中选择五个正像素点进行视频分割。此过程产生包含被操作目标掩码的分割视频。
目标重建。利用每帧每个目标的分割掩码,基于这些图像执行网格重建。由于大多数互联网视频都是从单个视点录制的,利用 InstantMesh 模型 (Xu et al., 2024) 重建 3D 网格,该模型支持从单个图像生成网格。通常,选择第一帧来重建网格;但是,对于第一帧中目标被严重遮挡的视频,将使用最后一帧。为了建立更真实的目标间尺寸关系,提出一种简单有效的尺寸估计方法。用 UniDepth(Piccinelli,2024)预测相机本征矩阵 K 和图像 I_i,j 的深度 d_i,j,其中 i,j 是像素坐标。给定目标的掩码区域 M,可以计算出实际掩码区域的最大距离 D_image:Dimage = max_(i_1, j_1), (i_2, j_2) ∈ M || p(i_1, j_1) − p(i_2, j_2) ||,其中 p(i, j) = K^−1·[x, y, 1]^T · d_i,j。这里 p 是相机坐标系中每个掩码像素的 3D 位置。然后,计算网格目标中顶点的最大距离,记为 D_mesh。网格目标的尺度 ρ 定义为 ρ = D_image/D_mesh。由于深度估计、内参估计和目标遮挡中的错误,绝对尺寸可能会出现一些噪声。但是,每个目标的相对大小大多是准确的,因为 D_image 和 D_image 是在同一相机坐标系内计算的。
目标的 6D 位置跟踪。重建目标后,预测整个视频中每个目标的 6D 位置,该位置将输入 GPT-4o 进行代码生成。在基于模型的设置中使用 FoundationPose(Wen,2024)来估计目标的位置和方向。该模型将目标网格、预测的相机内参和每帧的深度信息作为输入。最后,根据网格文件和计算出的尺度因子自动为每个目标生成一个 URDF 文件。
将视频中的视觉信息提取到任务 JSON 文件中后,可以在模拟中构建任务场景并基于 GPT-4o 学习策略。这个过程分为两个阶段。首先,生成完整的任务代码,可以直接在 Isaac Gym (Makoviychuk et al., 2021) 环境中执行。其次,受到最近关于 LLM 驱动的奖励函数生成工作的启发,用上下文奖励反思 (Shinn et al., 2023; Ma et al., 2023; Wang et al., 2023a) 迭代地微调生成的奖励函数。和 Eureka (Ma et al., 2023) 相比,本文从头开始生成任务代码(包括奖励函数),而不是依赖预存在的任务代码并从手动定义的成功函数开始奖励反思。
任务代码生成。受前人研究(Ma et al., 2023; Wang et al., 2023b;c)的启发,系统地介绍通用任务代码生成的流程,这有助于通过有条理的方式提示来推断代码。值得注意的是,任务代码由六个部分组成:场景信息、重置函数、成功函数、观察函数、观察空间函数和奖励函数。
(1) 场景信息是指从视频创建的任务场景 JSON 文件。它包含任务字幕、视频文件路径、视频描述和目标信息,包括大小、URDF 路径和跟踪的 6D 位置列表。
(2) 重置函数负责在开始时根据特定的空间关系定位目标。
(3) 成功函数确定成功状态。值得注意的是,重置和成功函数都是由 GPT-4o 根据任务描述、提供的 6D 位置列表和思维链(CoT)示例 (Wei et al., 2022) 生成的。
(4) 此外,可以访问模拟中目标的状态。因此,查询 GPT-4o 以确定是否需要进行额外的观察。有趣的是,它可以包括诸如目标与夹持器之间的距离或朝向目标物体的归一化速度之类的观察结果。
(5) 同时,它计算出构建神经网络的正确观察形状。
(6) 关于奖励函数,遵循 (Ma et al., 2023) 中的说明和 CoT 示例。
编写一个任务代码生成模板,只需查询一次 VLM 即可生成包含所有六个部分的可执行代码。生成八个示例代码,并通过重新检查 GPT-4o 的正确性、合理性和效率选择一个,这是后续上下文奖励反思阶段的基本代码候选。
强化学习和奖励函数迭代。给定生成的任务代码,在奖励函数 Rˆ 和成功函数 R_0|1 下通过强化学习训练策略。值得注意的是,我们为成功奖励分配了较高的权衡,将训练奖励函数制定为 Rˆ + λR_0|1,λ = 100。此外,按照 Eureka (Ma et al., 2023) 中的方法,应用上下文奖励反思,使用 GPT-4o 迭代设计奖励函数。每次都会为训练策略采样 N = 8 个不同的奖励函数,并收集训练和评估日志。然后,从上一次迭代中选择最佳函数,并根据这些日志以及特定说明和 CoT 示例生成新的奖励函数。例如,除了提供来自先前任务的良好示例外,还优先考虑成功轨迹的累积奖励超过失败轨迹的累积奖励的训练输出。
正如最近从具有特定格式大规模数据集进行策略学习的成功所见证的那样(Padalkar,2023;Reed,2022;Team,2024;Brohan,2023),想要研究如何从互联网视频中学习通用策略,该策略直接输出机器人的可执行动作,而不是不可执行的未来视频(Du,2024;Qin,2023)或语言 tokens(Liang,2023;Brohan,2023)。将 Video2Policy 视为一个数据引擎,用于从互联网视频中生成成功的策略。然后,可以在模拟中获得与视频行为相匹配的专家轨迹。值得注意的是,这些专家轨迹可以是想要的任何格式,例如状态、2D 图像或 3D 图像。在这项工作中,选择 RGB 图像观察。从视频中训练 RL 策略,并从学习的策略中收集成功的轨迹。之后,使用模仿学习通过行为克隆(BC)从收集的数据集中学习通用策略。最后,将学习的策略迁移到现实世界。为了弥合模拟与现实之间的差距,在数据收集中应用一些域随机化,并将分割图作为部署的输入。
实验设置。用 Issac Gym (Makoviychuk et al., 2021) 作为所有实验的模拟引擎,该引擎由于计算效率高和物理仿真度高的优点,常用于机器人任务。专注于桌面操作任务,目标会在开始时随机重置在桌面上。任务的范围设置为 300,并行环境的范围为 8192。对于每个任务,用不同种子在 3 次运行中对 10 个评估事件的成功率进行平均。
视频数据源。为了从互联网 RGB 视频中重建场景,选择 Something Something V2 (SSv2) 数据集 (Goyal et al., 2017),这是一个机器人社区常见且多样化的视频数据集。它包括人类用手操纵目标的各种行为。为了进一步研究框架对更复杂的目标或行为的能力,自己录制三个不同行为的野外视频。值得注意的是,在实验中使用的所有视频都是仅具有 RGB 的 3 通道,可访问性最高。对于视频质量,可以容忍相机的微小运动,并且将分辨率设定为 1024。
场景生成。对所有目标进行 6D 位置跟踪。考虑到随机化所有目标的初始状态,仅将第一帧和最后一帧的 6D 位置输入到提示中。这在大多数任务中都是合理的,因为这两帧对于推断目标之间的关系非常重要。即使这种简化会错过某些行为(例如投掷)的运动信息,也提供任务描述来设计奖励函数,以便 LLM 生成速度奖励分量。此外,明确计算 6D 位置之间的差异,并将信息输入 LLM 以考虑成功函数。对于大多数单个目标的 SSv2 视频,存在严重遮挡,使得重建网格资产变得困难。手动选择第一帧或最后一帧来重建网格,并在同一流水线中预测 6D 位置。在获得视觉信息后,以课程方式生成任务代码(Ma et al., 2023; Wang et al., 2023b)。从一开始,提供到达方块和抓取方块的示例代码。然后,将成功生成的任务示例添加到下一个任务池中。最后,它甚至可以学习使用方向速度奖励进行动态任务并解决它们。如图给出一些生成任务的演示。

强化学习。对于策略学习,在一个经过良好调整的实现代码库(Makoviichuk & Makoviy-chuk, 2021; Ma et al., 2023)中选择 PPO(Schulman et al., 2017)算法。在所有任务和所有基准上共享代码库中推荐的相同参数。至于评估指标,为每个生成的任务编写真实成功函数。与 Eureka (Ma et al., 2023) 不同,不允许在训练期间访问评估指标,并且手动评估最终模型的结果。对于 SSv2 数据集,在强化学习期间进行 5 次迭代并在每次迭代中抽样 8 个奖励函数。在收集的视频中,进行 8 次迭代并抽样 8 个奖励函数。
训练细节。选择行为克隆 (BC) 来学习通用策略。对于模型架构,应用预训练的 Resnet18 (He et al., 2016) 作为主干来提取特征并堆叠 2 帧作为观察值。然后在 3 层 MLP 中构建策略头,隐藏状态为 512 维。此外,策略在收集的轨迹上训练 30 个 epochs,批次大小为 1024。策略头的学习率为 3e-4,而 Resnet 主干的学习率为 3e-5。对于评估,评估 3 个种子 10 个提升任务的最终检查点,并对每个种子 10 条轨迹的结果取平均值。评估任务包括 5 个具有新形状和新纹理的目标,以及 5 个具有未见过类别的目标。
策略学习基线。由于将互联网 RGB 视频转换为任务策略的工作很少,因此在实验中专注于策略学习部分。根据以下基线对方法进行基准测试。(1)代码即策略(CoP)(Liang,2023),它使用环境中的所有状态查询 LLM 来为机器人编写可执行代码。为了确保 CoP 有更好的性能,用闭环控制并每 50 步重新生成一次代码策略。(2)RoboGen,它不需要成功函数并且无需奖励反思迭代即可学习。(3)Eureka,它使用 LLM 为奖励和成功函数生成代码,而不使用视频信息。为了进行公平的比较,对所有基线使用相同的目标网格和从视频生成的任务代码。
通用策略的基线。对于通用策略,将提出的 Video2Policy 视为专家轨迹收集的数据引擎。因此,其他数据引擎是基线,可以在重建的场景中生成成功的轨迹。比较以下模型:(1)Code-as-Policy(CoP),可以直接使用状态输入而不是图像,应用于新任务;(2)BC-CoP,从 CoP 收集的数据训练 BC 通用策略;(3)BC-V2P,与 BC-CoP 相同,但使用 V2P 收集的数据。CoP 基线展示基于状态的通用策略效果,而后者 BC-CoP 和 BC-V2P 结果说明通用策略在不同数据引擎下的性能。
输入表示和网络架构。将图像的分割掩码、机器人的末端执行器 (EEF) 状态和夹持器状态作为输入。采用 SAM-2 进行分割,其中目标物体的像素位置在第一帧中手动提供作为输入,如图所示。堆叠 2 帧并添加额外的多层感知器 (MLP) 层以将机器人状态映射到 256 维特征向量中。此外,动作的旋转分量按 0.2 的倍数缩放。

域随机化。在模拟中的数据收集过程中,对噪声水平为 0.02 且随机延迟为 0.01-0.02 秒的动作应用随机化。此外,物体的物理属性(例如大小和重量)也是随机的。确保模拟和现实中的相机姿势一致。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









