










24年11月来自清华、早稻田大学、明尼苏达大学、多伦多大学、厦门大学马来西亚分校、电子科大(成都)、智平方科技和河南润泰数字科技的论文“FASIONAD : FAst and Slow FusION Thinking Systems for Human-Like Autonomous Driving with Adaptive Feedback”。
确保安全、舒适和高效的导航是自动驾驶系统开发和可靠性的基础。虽然在大型数据集上训练的端到端模型在标准驾驶情况下表现良好,但它们往往难以应对罕见的长尾事件。大语言模型 (LLM) 的最新进展带来改进的推理能力,但它们的高计算需求使自动驾驶汽车的实时决策和精确规划变得复杂。本文的 FASIONAD,是一个受认知模型“思考,快与慢”启发的双-系统框架。快速系统通过快速的数据驱动路径规划有效地管理常规导航任务,而慢速系统则处理不熟悉或具有挑战性的场景中的复杂推理和决策。由分数分布和反馈引导的动态切换机制,允许快速和慢速系统之间的无缝过渡。快速系统的视觉提示,促进慢速系统中类似人类的推理,这反过来又提供高质量的反馈以增强快速系统的决策。为了评估方法,引入一个源自 nuScenes 数据集的新基准,旨在区分快速和慢速场景。FASIONAD 为该基准设定新标准,开创一个区分自动驾驶中快速和慢速认知过程的框架。这种双-系统方法为创建更具适应性和更像人类的自动驾驶系统提供一个有希望的方向。
自动驾驶有可能通过提高效率、减少人工工作量和最大限度地减少事故来改变交通运输[26]。传统的自动驾驶系统通常采用模块化设计,具有用于感知、预测、规划[26]和控制的独立模块。然而,这些系统在动态和复杂环境中的适应性较差,并且在解决长尾问题和冗余方面面临挑战[46, 63],这限制了它们的可扩展性和适用性。
为了解决这些限制,端到端(E2E)学习方法,如模仿学习(IL)[9, 23, 24, 39, 57]和强化学习(RL)[8, 27],已被广泛探索。然而,模仿学习(IL)方法容易发生协变量漂移,导致在关键场景中缺乏鲁棒性[32, 42],即使有从错误中学习(LfM)[2]等改进。强化学习(RL)方法虽然在模拟中有效,但在实际应用中面临重大的安全问题并遇到挑战,特别是由于奖励设计和模拟-到-现实的迁移困难 [11]。最近的研究如 DriveCoT [55] 和 DriveInsight [28] 旨在提高可解释性,但通常需要花费大量时间才能在不同场景中有效泛化。
随着大语言模型 (LLM) 和视觉语言模型 (VLM) 的最新进展,研究人员已开始探索它们在自动驾驶中的应用,包括操控任务 [50]、空间落地 [48] 和技能学习 [49]。然而,尽管取得了这些进展 [45、47、56、58],LLM 和 VLM 仍然面临空间落地和实时决策方面的挑战 [60]。平衡安全性和性能仍然是一个关键问题 [54],这个限制它们在复杂的现实世界自动驾驶环境中的更广泛应用。
本文提出 FASIONAD,一种自适应反馈框架,无缝集成快速和慢速思维方法。如图所示 FASIONAD 的动机:传统的 E2E 方法在可解释性和泛化方面存在困难,基于 LLM 的方法面临决策速度慢、空间定位问题和潜在的幻觉。双-系统流水线 [51] 使用 LLM 来融合规划,但缺乏安全反馈机制。如图比较不同的自动驾驶运动规划方法,展示该方法能够自适应上下文-觉察决策,提供更好的解释和反馈。
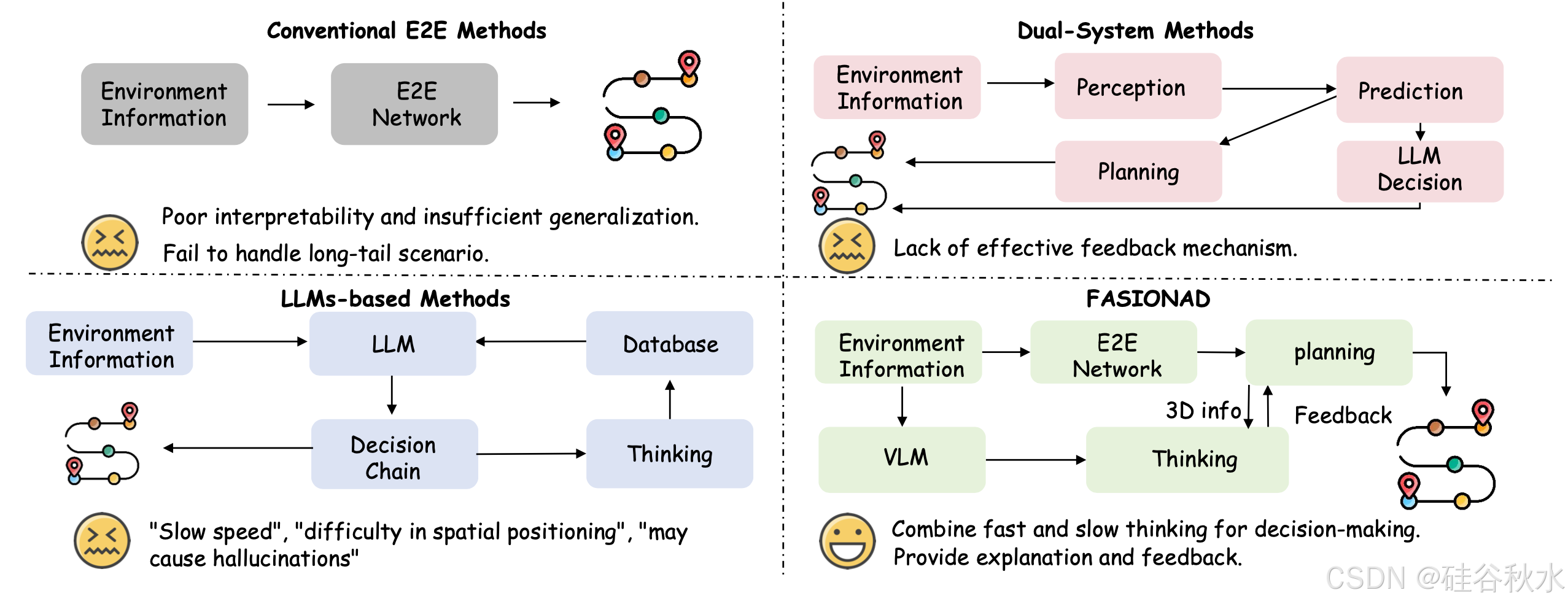
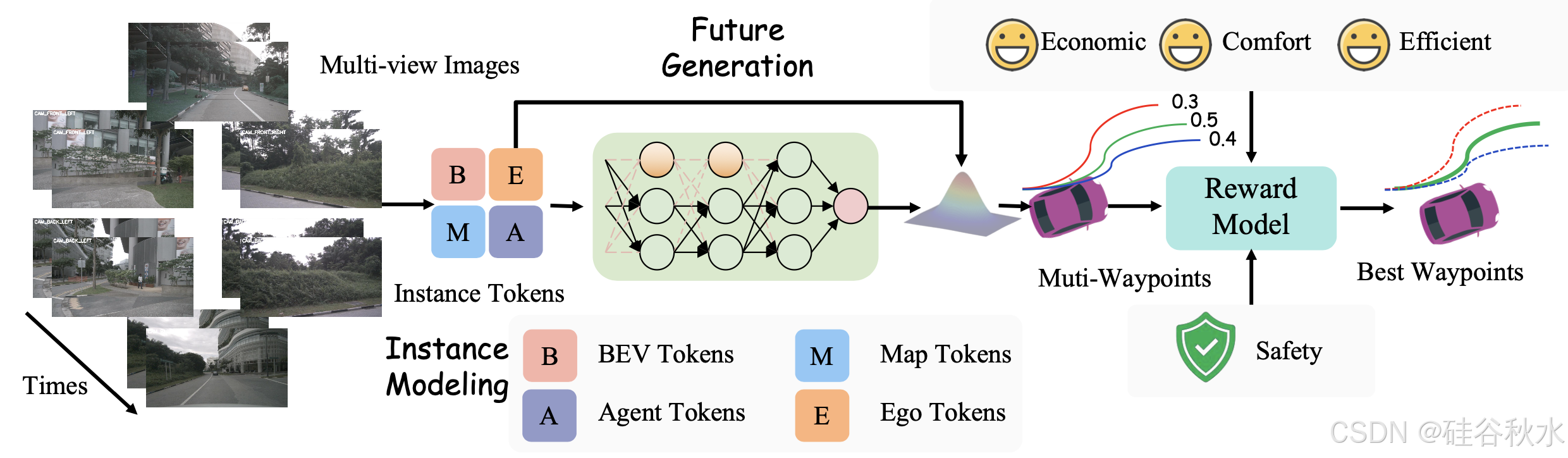
如图所示,FASIONAD 框架采用双-路径架构:快速路径用于快速实时响应,慢速路径用于在不确定或具有挑战性的驾驶场景中进行全面分析和复杂决策。
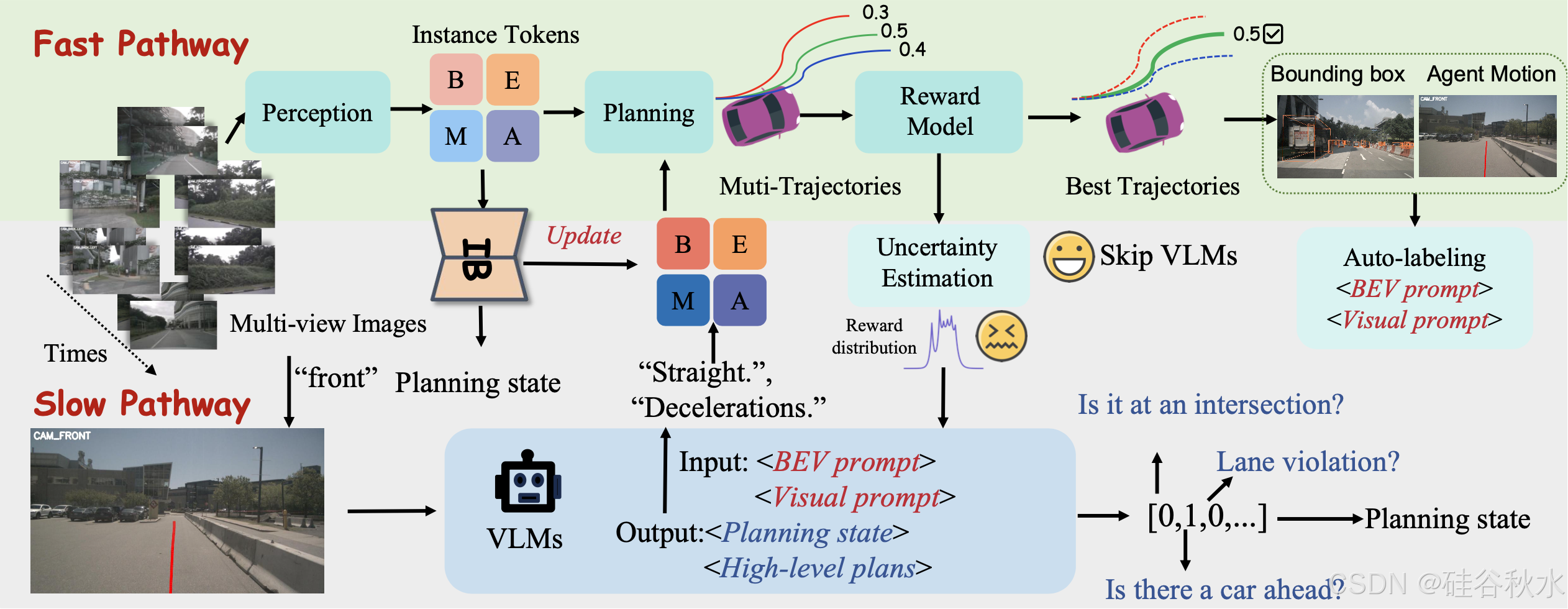
在快速路径中,给定一组 N 个多视图图像 I_t = {I_1t, I_2t, …, I_Nt} 和高级导航命令 C_t,模型会生成一个航路点序列 W_t = {w_1t, w_2t, …, w_Mt},其中每个航路点 w_it = (x_it, y_it) 表示自车在时间 t + i 的预测鸟瞰图 (BEV) 位置。该路径可以表示为:
FASIONAD(快速路径):(I_t, C_t) → W_t (1)
相比之下,慢速路径仅处理多视图图像 I_t 以生成规划状态 P_t 和高级元动作 A_t,为复杂场景中的决策提供更详细的评估和战略指导。该路径补充快速路径,使其能够在不确定或具有挑战性的条件下进行更深入的分析。慢速路径表示为:
FASIONAD(慢速路径):I_t → (P_t, A_t) (2)
为了协调快速路径和慢速路径,引入基于不确定性的航点预测和轨迹奖励。该机制根据环境背景和复杂性动态,激活任一路径,优化响应性与准确性,从而在需要时实现即时反应和彻底分析。
快速路径
快速通道的第一步是处理传感器输入,以获得对周围环境的高级描述。受人类驾驶员决策过程的启发,将决策所需的信息分为两个层次:低级感知信息(观察到什么?)和高级感知信息(了解观察元素之间的相互作用)。低级感知信息包括有关交通参与者和地图特征的详细信息,而高级感知信息则捕获这些元素之间的相互作用,如图所示。
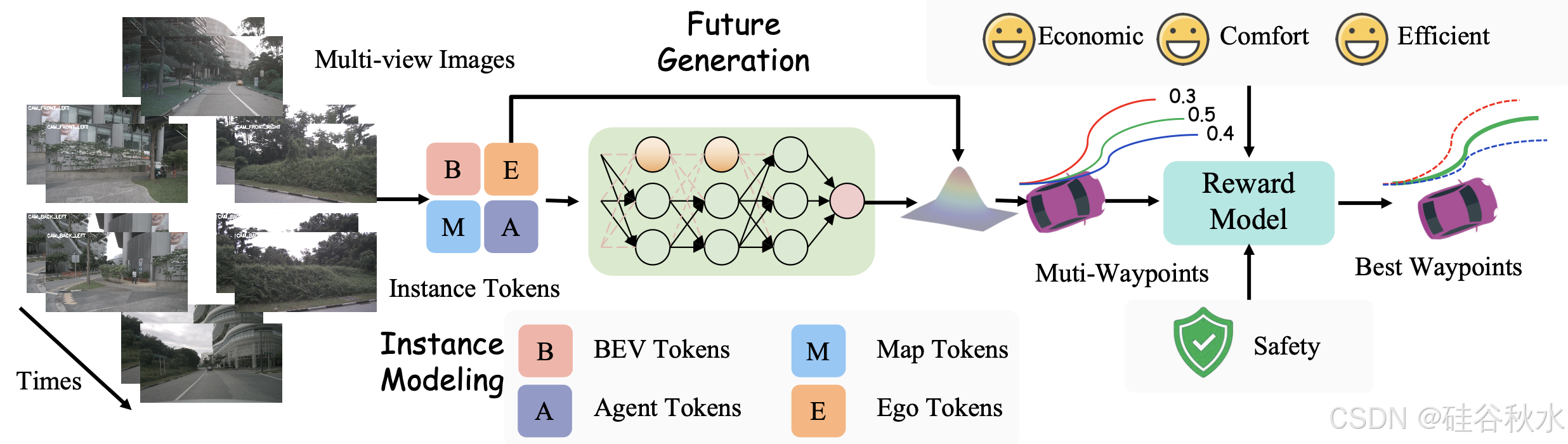
航点预测和奖励评估
轨迹生成器。轨迹生成器输出航点预测 W = {w_t},每个航点 w_t = (x_t, y_t) 表示 BEV 坐标中的空间位置。为了捕捉交通参与者之间的互动,采用受 GenAD [61] 启发的生成框架,将轨迹预测建模为未来轨迹生成问题。
奖励模型。该模型生成 N_C × N_K 条候选轨迹 T = {T_i},其中每条轨迹 T_i 表示在时间范围 T_s 内的航点序列。这里,N_C 是导航命令的数量,N_K 表示前 K 个采样的多模态轨迹。每个轨迹 T_i 由奖励模型 F_Reward 分配一个奖励 r_i,该模型综合考虑安全性、舒适性、效率和经济性等因素:
F_Reward = α_safety C_safety + α_comfort C_comfort + α_efficiency C_efficiency
+ α_economic C_economic (3)
其中 α_safety ,α_comfort ,α_efficiency, α_economic 是确定每个因素相对重要性的权重。
快速路径损失函数。采用 [24, 61] 中的损失函数设计,它由规划损失 L_plan、辅助 3D 检测损失 L_det 和地图分割损失 L_seg 组成。总损失函数为:
L_fast = λ_plan L_plan + λ_det L_det + λ_seg L_seg (4)
其中 λ_plan、λ_det 和 λ_seg 是平衡辅助损失的权重。
慢速路径
在复杂场景中,准确解释环境因素对于安全决策至关重要。慢速路径模拟类似人类的推理来推断背景并预测未来行动,类似于人类驾驶员。
面向规划的 QA
提出一系列面向决策的问答 (QA) 任务,以促进自动驾驶系统中的类人推理。如图说明 QA 问题的类型。
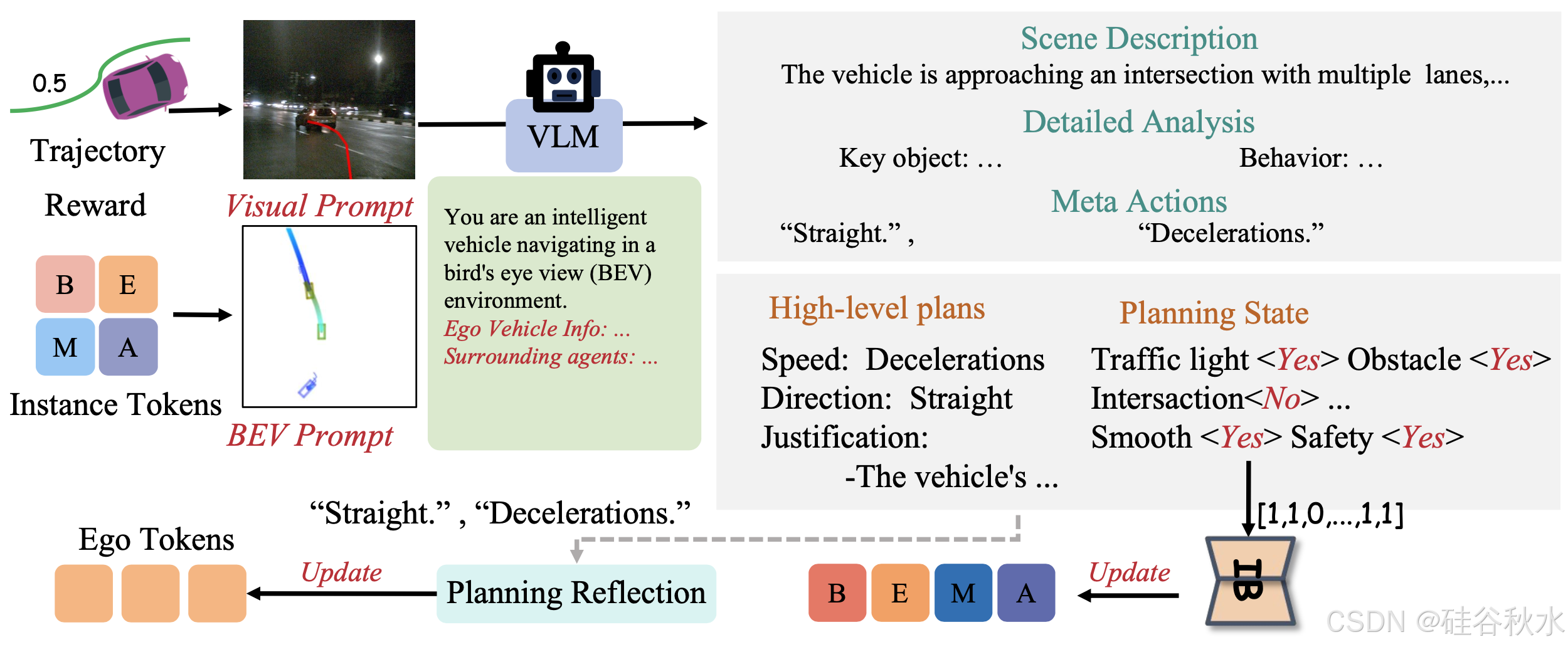
本研究解决通过提高系统对类人驾驶行为的理解和复制来增强自动驾驶系统稳健性的五个关键方面:
场景分析。这涉及评估环境因素,例如天气条件(例如晴天、雨天、下雪天)、一天中的时间(早上、下午、傍晚、夜晚)、交通密度(轻或重)和道路状况(潮湿、干燥、结冰)。彻底分析这些因素使系统能够解释更广泛的背景,从而影响速度和机动选择等关键决策。
交通标志识别。这项任务侧重于识别和解释各种交通标志,包括交通信号灯、停车标志、让行标志和限速标志。准确的标志识别,对于法规遵从性和安全性至关重要,是类人驾驶行为的基本组成部分。
关键目标识别和行为分析。这涉及识别和分析环境中的关键目标,例如车辆、行人、骑自行车者和动物,并根据过去的动作预测它们未来的行为。准确的识别和行为预测对于预测危险和实现主动决策以避免碰撞至关重要。
规划状态。与规划相关的状态表示为 K 维二进制向量,描述与决策相关的当前环境背景。这种结构化表示通过允许系统优先考虑行动、优化路线和改进决策来支持高级规划。
高级规划和论证。此方面涉及制定路线选择、车道变更和合并机动等动作的高级规划,同时考虑长期目标和约束。通过论证这些决策,系统确保其动作既安全又高效,与总体驾驶目标保持一致。这一组件对于在自主系统中复制类似人类的决策至关重要。
数据收集和自动标记
为了生成这些问答 (QA) 任务,利用快速路径的输出(包括 3D 目标检测框和跟踪轨迹)进行自动注释。此外,利用大型视觉语言模型 (LVLM)(例如 Qwen)来生成与观察场景及其元素紧密相关的描述性 QA。受驾驶决策的认知需求的启发,引入两种类型的提示来增强 QA 生成:视觉提示,有助于以类似于人类感知的方式解释视觉提示和场景元素;BEV 提示,提供自上而下的环境视图,以改善对空间关系和智体交互的理解。
为了解决 VLM 输出中的多变性(可能包含无关或不相关的信息),采用受自然语言处理 (NLP) 中少样本学习启发的正则化策略。但是,与一般的 NLP 应用不同,自动驾驶需要高可靠性和一致性。因此,通过简化过程改进 VLM 输出,确保对快速路径规划器的反馈保持简洁有效,最终支持生成新的、准确的轨迹。
慢速通道流水线可以公式化如下:
P_t, A_t = Φ[E(V^front_t), E(B_t)] (5)
将轨迹视觉提示融入慢速路径规划中。具体来说,将快速路径规划器生成的航点投射到前视摄像头上,从而创建轨迹的视觉表示。这种规划路径的视觉近似,有助于类似人类的推理过程,从而实现更直观的决策评估和修改,从而产生更可靠、更有效的高级规划。
基于车辆的 BEV 坐标系,BEV 提示清晰地描述自车辆与周围智体之间的空间关系和动态交互。
提出一个高级规划编码器,记为 E_A,它将 VLM 中的高级决策转换为元动作特征 A_t。由于高级规划可以分解为结构化的元动作集,编码器 E_A 使用一组可学习的嵌入 e_A 将这些元-动作与它们对应的元-动作特征进行一对一映射,N_A 表示元动作的数量。
传统的 LLM 方法主要依赖于自回归学习。相比之下,该方法将自回归学习与最大似然估计 (MLE) 损失相结合以调整 VLM。为了提高复杂场景中的预测准确性,引入奖励引导的回归损失。与依赖人工反馈进行强化学习微调的 InstructGPT [37] 不同,系统利用自动生成的指导。目标是复制规划状态和高级规划,这些规划可在任务设置中直接访问。因此,将真值定义为 [Y_P_t , Y_A_t]。
由于基于 GPT 模型通常在 token 级应用监督,而整个序列对于回归来说都是有意义的,因此将近端策略优化 (PPO) [43] 与掩码结合起来,以更有效地应用监督。调整损失表示为 L_rvlm,在策略梯度框架内计算为奖励:
L_rvlm = Reward(s1:T_i ) · Φ(sT_i |s^1:T_i−1) (6)
其中 sT_i 表示时间步 T_i 处的预测 token,Reward(s^1:T_i ) 是 Fast Pathway 中航点预测的奖励函数。最终训练损失结合了标准语言损失和奖励引导损失:
L_slow = λ_MLE LMLE + λ_rvlm L_rvlm (7)
快慢融合自动驾驶
如图所示自适应反馈机制处理双重输入:轨迹-生成的图像,和从实例 tokens 派生的 BEV 提示,两者都输入到 VLM 中。
不确定性估计和决策机制
为了有效地驾驭动态和不可预测的环境,估计航点预测中的不确定性至关重要,因为它允许系统根据预测可靠性调整其决策。为了处理航点预测中的异常值和模型不确定性,采用拉普拉斯分布:
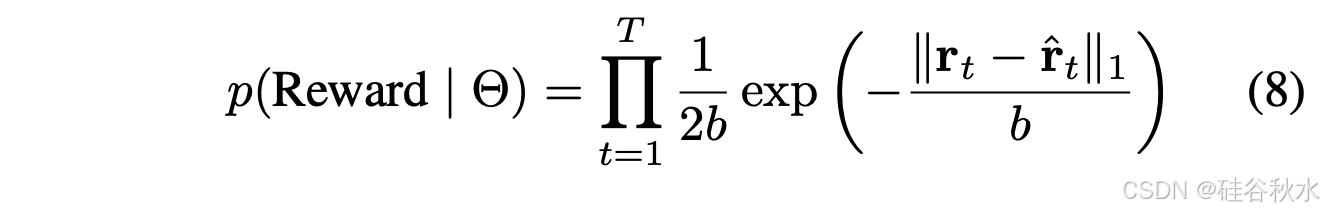
该分布的重尾使其对异常值具有鲁棒性,这在动态驾驶环境中非常有利。
拉普拉斯分布的重尾和尖峰使其对异常值具有鲁棒性,并且可有效估计动态驾驶环境中的不确定性。根据奖励(R)和估计的不确定性,系统选择用于瞬时导航的快速路径(当奖励超过阈值且不确定性较低时),或用于详细分析的慢速路径。
信息瓶颈反馈
驾驶环境通常包含大量无关或嘈杂的信息,这些信息对规划没有帮助。为了解决这个问题,应用信息瓶颈原理[18]来仅提取与决策相关的信息。这种方法可确保模型优先考虑导航的关键特征,从而有效地最大限度地减少无关数据的影响。
为了将实例-觉察特征 z 与 y_t 对齐,用 MLP f_MLP 将 z 映射到一维向量 y_i。知识蒸馏过程最小化以下目标:

其中 q_d(y_t|y_i) 是给定 y_i 的 VLM 派生向量 y_t 概率分布,q_e(y_i | z_current) 对当前状态的实例-觉察特征进行编码。这里,p(z) 是 z 上的先验分布,β 是正则化参数。
反馈融合机制
慢速路径由奖励信号和不确定性激活,可以选择性地深入分析基本 VLM 派生特征。集成通过可学习嵌入 e_A 和自我 token e_ego 之间的交叉注意进行,其中 e_ego 将 e_A 作为 K-V 对进行查询。这歌捕获上下文依赖关系,并将生成的融合状态输入到快速路径中进行轨迹规划,模仿人类在复杂驾驶场景中的决策。
实验设置如下。
对 FASIONAD 的评估涵盖开环和闭环性能指标。对于开环评估,用 nuScenes 数据集,该数据集提供来自城市驾驶场景的全面注释数据。此评估侧重于通过 L2 距离和碰撞率指标来衡量策略与专家演示的相似性。由于这些开环测量的计算效率和结果一致性,在消融研究中优先考虑它们。闭环评估采用 CARLA Closed-loop Town05 Short Benchmark,其特点是具有挑战性的场景,包括狭窄的街道、密集的交通和频繁的交叉路口。主要性能指标是驾驶分数 (DS),包括路线完成度 (RC)-违规分数的乘积和路线完成度本身。为了确保与现有方法的公平比较,围绕基于学习的策略实施基于规则的包裹器,遵循基准评估中的标准做法。其有助于最大限度地减少测试期间的违规行为。
训练过程分为三个阶段:(1)训练快速路径以生成合理的轨迹和强大的奖励函数,(2)微调视觉语言模型(VLM)以输出结构化向量表示,以及(3)联合训练快速和慢速路径以协调反馈并提高复杂场景下的性能。
第一阶段,重点学习稳健的轨迹生成,并设计评估安全性、效率和舒适度的奖励模型。
第二阶段,专注于微调视觉语言模型 (VLM) 以生成结构化矢量表示,增强慢速通路为决策提供高质量反馈的能力。
最后一个阶段,重点是将慢速路径的基于推理反馈整合到快速路径的实时轨迹生成中。此过程确保系统将快速路径的效率与慢速路径的上下文推理和适应性相结合,协调它们的输出以提高整体性能。
快速路径的实现细节如下。
采用 ResNet50[20] 作为主干网络来提取图像特征。将分辨率为 640 × 360 的图像作为输入,并使用 200 × 200 的 BEV 表示来感知周围场景。为了公平比较,基本上使用与 VAD-tiny[24] 相同的超参。将 BEV token、地图 token 和智体 token 的数量分别固定为 100 × 100,100 和 300。每个地图 token 是包含 20 个点的 tokens,以表示 BEV 空间中的地图点。将每个 BEV、点、智体、自我和实例 tokens 的隐藏维度设置为 256。在奖励函数中设置 α_safety = 2、α_comfort = α_efficiency = α_economic = 1。
对于训练,将损失平衡因子设置为 1,并使用 AdamW[35] 优化器和余弦学习率调度器[34]。将初始学习率设置为 2 × 10-4,权重衰减为 0.01。默认情况下,用 8 个 NVIDIA Tesla A100 GPU 对 FASIONAD 进行 30 个 epoch 的训练,总批次大小为 8。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









