










25年2月来自广东人工智能和数字经济实验室、深圳大学、巴黎理工学院和巴黎高等师范学院、中山大学的论文“Exploring Embodied Multimodal Large Models: Development, Datasets, and Future Directions”。
近年来,具身多模态大模型 (EMLM) 因其在复杂的现实环境中弥合感知、认知和行动之间差距的潜力而备受关注。这篇全面的评论探讨此类模型的发展,包括大语言模型 (LLM)、大型视觉模型 (LVM) 和其他模型,同时也研究其他新兴架构。讨论 EMLM 的发展,重点关注体现感知、导航、交互和模拟。此外,该评论还对用于训练和评估这些模型的数据集进行详细分析,强调多样化、高质量数据对于有效学习的重要性。本文还确定 EMLM 面临的关键挑战,包括可扩展性、泛化和实时决策问题。最后,概述未来的方向,强调整合多模态感知、推理和动作以推动日益自主的系统发展。
具身智能,即认知源自与环境的物理交互的观点,是对传统认知理论的批判。罗德尼·布鲁克斯(Rodney Brooks)于 1991 年发表的论文 [1]《无表征的智能》指出,智能行为可以在不依赖内部表征的情况下出现,而是专注于环境交互。瓦雷拉(Varela)、汤普森(Thompson)和罗施(Rosch)在《具身心智》(1991 年)[2]中进一步发展了这一观点,强调了身体体验在塑造认知方面的作用。同样,拉科夫(Lakeoff)和约翰逊(Johnson)的《肉体哲学》(1999 年)强调认知以感觉运动体验为基础 [3]。这一概念也在机器人技术中找到实际应用,例如 Cog 项目 [4],该项目探索机器人如何通过与世界的身体交互来发展认知。因此,具身智能连接认知科学、哲学和机器人技术,提供一种更为综合的身心观(view of mind and body)。
随着大模型技术的快速发展,具身智能越来越多地与这些模型相结合。这是一个相对较新的概念,研究人员试图将具身认知的原理应用于大规模预训练模型。其目的是探索人工智能 (AI) 如何通过与环境的交互来开发更灵活、适应性更强的能力。术语“具身多模态大模型”(EMLM) 是指一类将多种数据模态(例如视觉、语言和动作)与具身能力(例如物理环境中的感知和交互)相结合的模型。这些模型也有其他各种名称,例如“大型具身多模态模型”、“具身大模型”和“大型具身模型”。虽然这些术语经常互换使用,但它们都强调多模态理解与以物理具身方式感知和与世界交互能力的结合。
EMLM 是人工智能和机器人领域中一个令人兴奋且发展迅速的领域。与传统的人工智能系统不同,EMLM 将视觉、语言和音频等多种感官模态集成到能够感知和与物理环境交互的智体中。EMLM 旨在弥合人工智能抽象推理能力与现实世界复杂性之间的差距,使智能系统能够以更接近人类认知的方式感知、行动和学习。这些模型可以同时处理多模态输入并生成影响物理世界的输出,这使得它们对于机器人操作、自主导航、人机交互和沉浸式虚拟环境等应用至关重要。
近年来,大模型与多模态感知系统(如具身智体)的集成带来突破性模型的开发,这些模型能够处理日益复杂的任务。然而,具有大模型的具身智能领域仍处于早期阶段,仍存在一些挑战。这些包括增强模型的可扩展性和泛化能力,提高处理复杂任务的能力,以及提高具身智体与其环境更有效交互的能力。
尽管该领域已经取得了重大进展,但目前关于 EMLM 的评论论文中仍然存在几个关键问题。首先,大多数现有评论主要关注自然语言处理中的传统大模型,如 LLM [5] [6] [7]、大型视觉模型和语言视觉模型 [8],而不是解释具身智体与大模型的集成。其次,即使有些评论确实关注这种集成,范围往往过于广泛。例如,论文 [9] [10] [11] [12] 专注于具身智能的整个发展过程,包括软件和硬件,而没有深入探讨多模态大模型在具身智能演化中的作用。此外,一些先前的论文 [13] [14] [15] 是在该领域最近的快速发展之前发表的,这限制它们捕捉最新发展的能力。一些论文只关注具身智能全栈中的特定大模型技术,而不是解决栈每个环节上的大模型技术。例如,论文 [16] 主要研究智体操作部分中的大模型,但没有考虑导航组件中的大模型。
如图所示具身智能感知、导航和交互的历史:
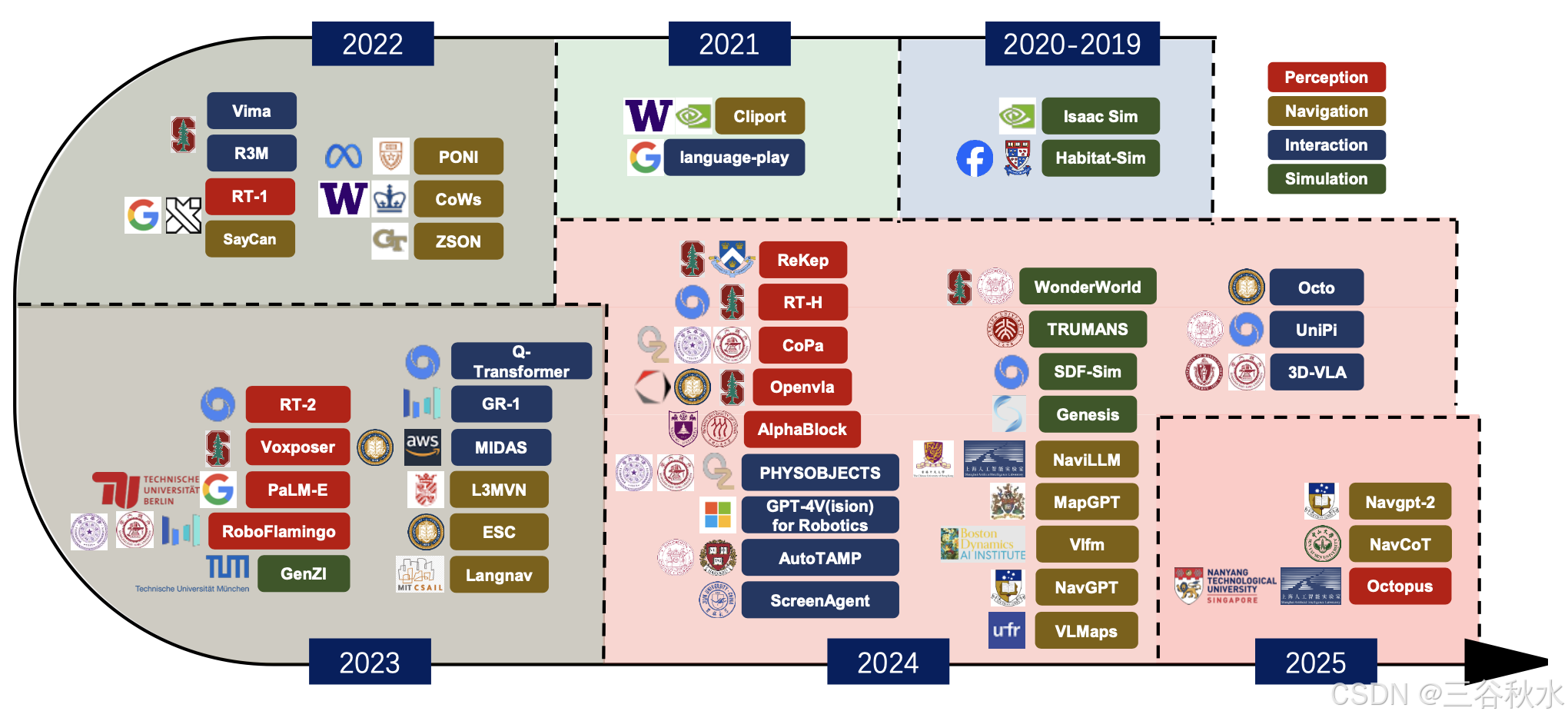
大型模型的发展,尤其是在自然语言处理、计算机视觉和深度学习领域的发展,为 EMLM 的出现铺平道路。这些先进的系统利用视觉、语言、音频和触觉等多种模态的集成,实现与物理世界的更自然、更直观的交互。大规模预训练和神经网络扩展方面的进步促进能够处理多模态数据的模型创建,同时体现对上下文、动作和交互的更深入理解,为人工智能的下一个前沿奠定基础。
具身智体
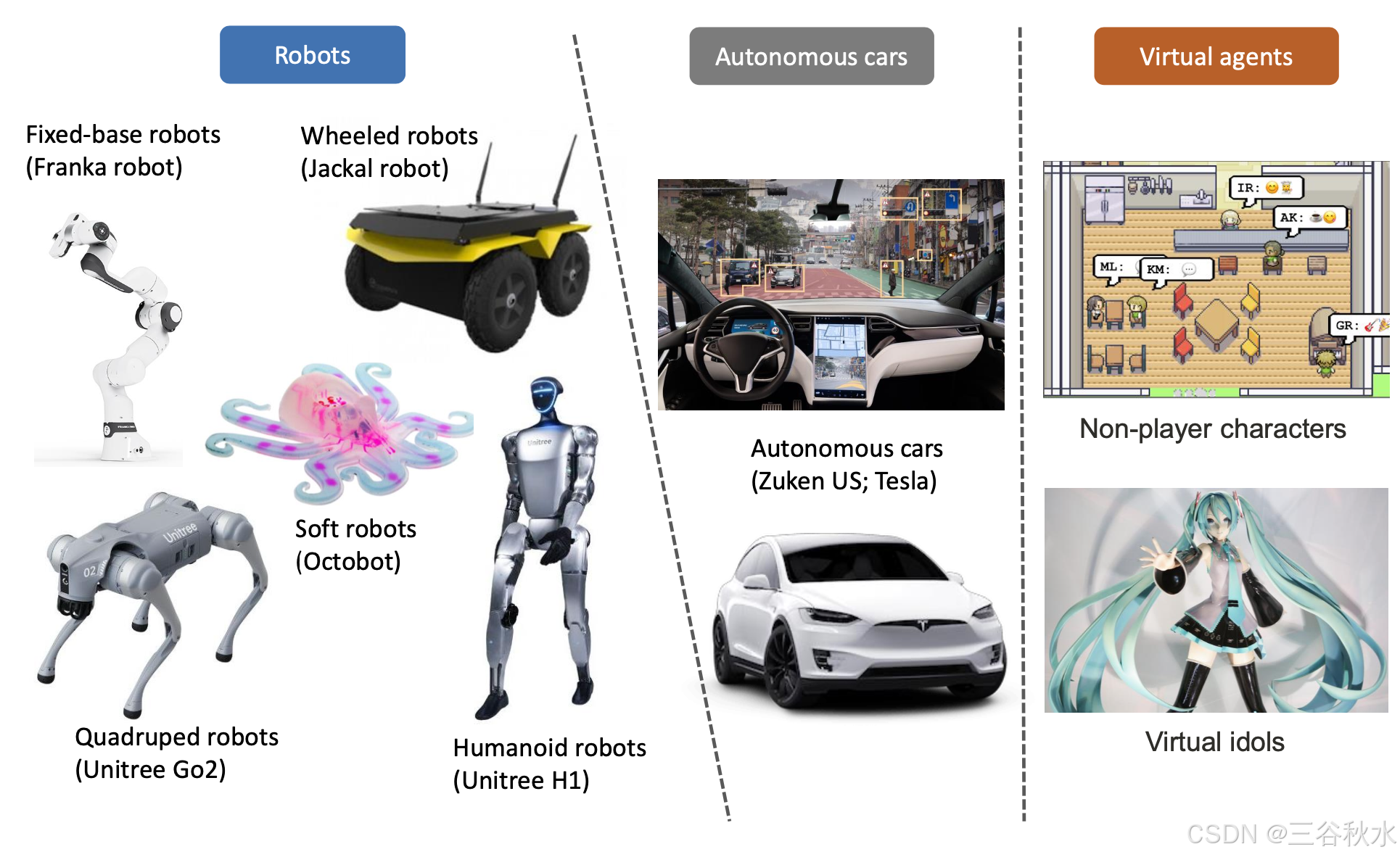
具身智体是具有物理或虚拟身体的自主实体,能够感知、动作并与环境交互。它们有各种类型,例如机器人、自动驾驶汽车、虚拟智体等。 如图所示,机器人是现有具身 AI 算法中最流行的智体。根据应用的不同,机器人有各种形式,包括固定底座机器人、轮式机器人、四轮机器人、人形机器人、软机器人等。它们独特的形状和设计使它们专门用于特定任务。例如,固定底座机器人(如 Franka 机器人 [17])通常用于工业环境中的自动拾取和放置任务。相比之下,人形机器人具有类似人类的外观和适应性,用途广泛,可部署在广泛的领域。 自动驾驶汽车也可以被视为具身智体。它们感知环境,做出实时决策,并与驾驶员和周围环境互动。除了驾驶安全之外,这些系统越来越能够解释人类的指令并与乘客进行对话 [18]。另一方面,虚拟智体在游戏 [19]、社会实验 [20]、虚拟偶像 [21] 等应用中非常突出。这些智体通过多种方式与用户交互,包括语言、视觉和音频,从而实现丰富而身临其境的体验。
大语言模型
LLM,例如 GPT-4 [22]、BERT [23] 和 T5 [24],已成为现代 AI 的基础组件,尤其是在 NLP 中。这些模型旨在通过对大量文本数据进行无监督学习来捕获复杂的语言模式和结构。在具身多模态系统的背景下,LLM 作为理解和生成自然语言的主要机制发挥着关键作用。它们处理和生成连贯文本的能力使它们能够弥合不同模态(包括视觉、语音和动作)之间的差距。通过将 LLM 与视觉或听觉数据相结合,具身系统可以解释多模态输入并生成与上下文相关的响应,从而实现更具交互性和智能的行为。本质上,LLM 充当这些系统的“语言大脑”,使它们能够理解和执行基于语言的命令、描述视觉场景或促进跨模态的复杂推理。
LLM 的发展历程从简单的统计模型,到基于深度学习的突破,再到超大规模的 Transformer 模型。随着算力的不断提升和算法的不断优化,LLM 有望实现更高的智能化水平,在各个领域发挥越来越重要的作用。在具身智能领域,这些模型将进一步增强智体与人的交互能力,让具身智体更加聪明、更加强大。
大型视觉模型
与 LLM 不同,大型视觉模型(LVM) 处理图像或视频信息。这些模型在图像识别、对象检测、图像生成和跨模态学习等任务中表现出色。在具身智能领域,LVM 也发挥着至关重要的作用,使机器人能够在复杂和动态的环境中感知和理解视觉世界,比如 ViT,SAM,DINO v1/v2。
大型视觉-语言模型
在 EMLM 中,大型视觉语言模型 (LVLM) 通过整合视觉和语言信息来增强智体对环境的理解、推理和任务执行。LVLM 使智体能够融合和协调多模态数据,从而使它们能够通过视觉输入识别目标并根据语言指令执行操作。此外,LVLM 促进动态环境中跨模态推理和自适应决策,从而显著提高机器人的交互和导航能力。
例子包括CLIP、DALL-E、BLIP、PaLM-E等。
其他模态方法
视觉-音频模型
除了视觉和语言之外,音频在日常任务中也发挥着至关重要的作用,帮助识别场景并定位发声目标。虽然大多数研究都侧重于视觉-音频或音频-语言数据,但很少有研究探索音频在具体任务中的作用。
视觉-触觉模型
在操作任务中,视觉信息通常是调整机器人动作的主要来源,但视觉传感器可能会受到遮挡和无法测量接触力的限制,而接触力对于成功执行操作至关重要。为了解决这个问题,一些研究探索将视觉和触觉数据结合。
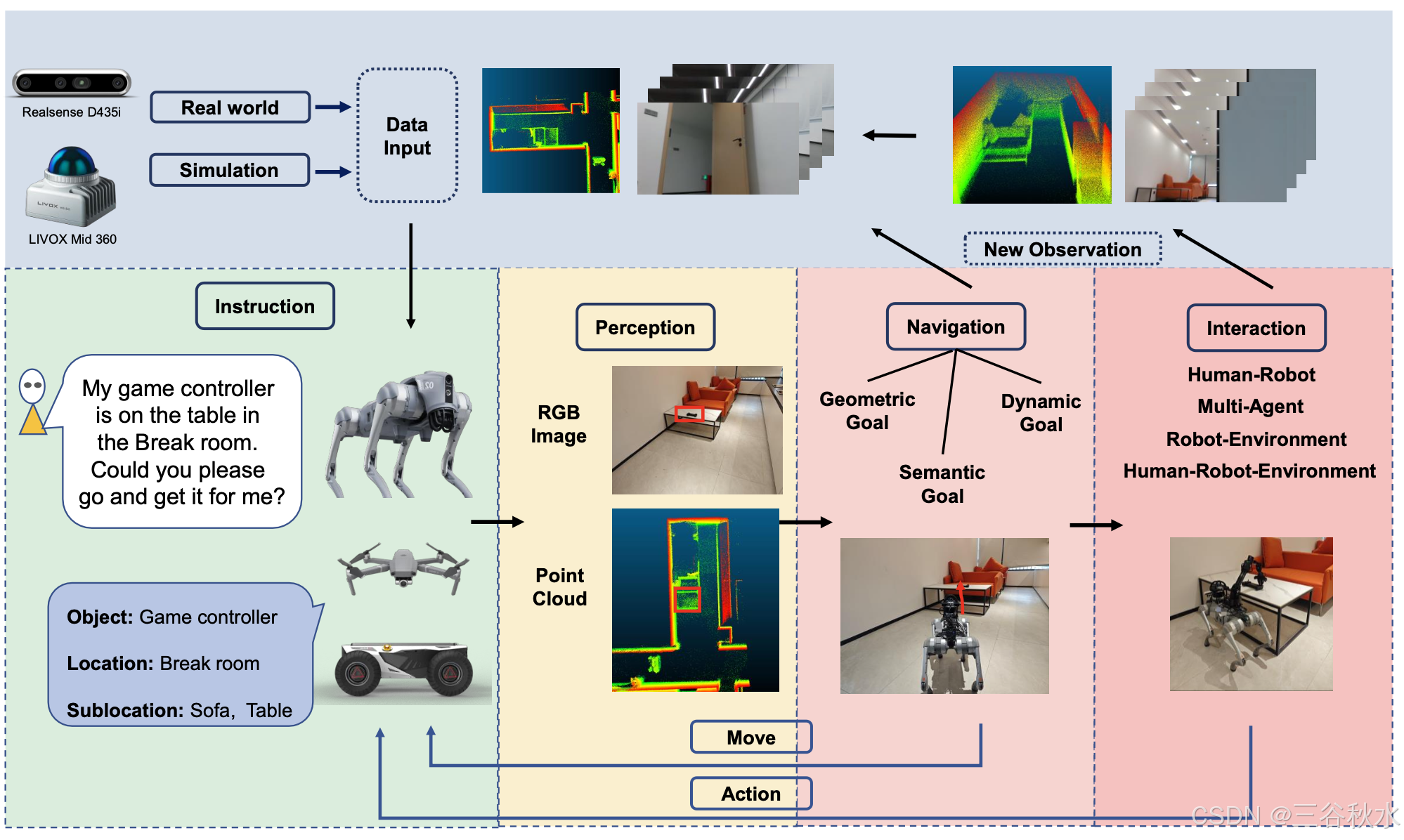
EMLM 是一种结合语言、视觉和听觉等多种模态信息的 AI 模型。它们可以理解和处理来自现实世界的不同类型的数据。如图所示,这些模型通常被设计用于执行各种任务,例如感知、导航和交互等。
具身感知
不同于使用传统的神经网络方法或大型模型来识别物体,根据具身智能的定义,具身智体具有与物理世界交互和在物理世界中移动的能力。这要求EMLM对物理世界中的物体以及物体之间的运动和逻辑关系有更深层次的感知和理解。具身感知需要视觉感知和推理,理解场景中的3D关系,基于视觉信息预测和执行复杂任务。
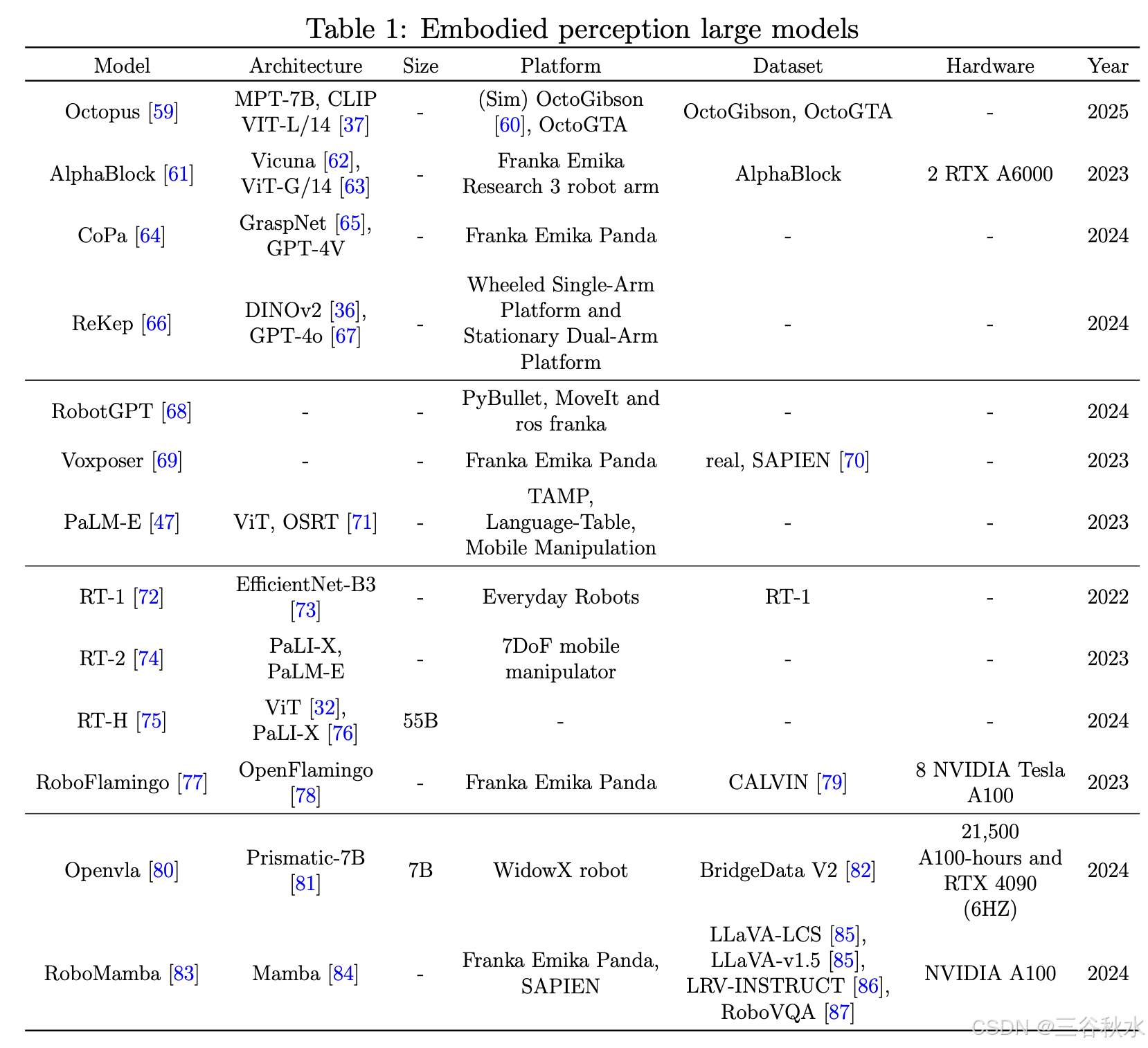
目前具身感知的大型模型主要有两类:一类是直接基于GPT,一类是基于其他大模型,这些模型的详细信息见表所示。
具身导航
相对于传统的 A 到 B 机器人导航(其中智体被指示从房间 A (x1, y1) 移动到房间 B (x2, y2),并且智体使用 A* [97] 或 Dijkstra 的 [98] 算法在预生成的 2D 地图上寻找可到达的最短路径),具身智能导航系统采用更动态和更具环境感知的方法。这些导航系统不仅仅依赖静态地图数据,而是通过传感器和模型实时感知和处理周围环境,将环境信息转换为智体可理解和可操作的语义。
在使用大规模具身智能模型的导航领域,有两种主要方法很流行:第一种方法是利用通用的大模型,而第二种方法是专门为具身智能任务量身定制专门的 EMLM,如表所示。
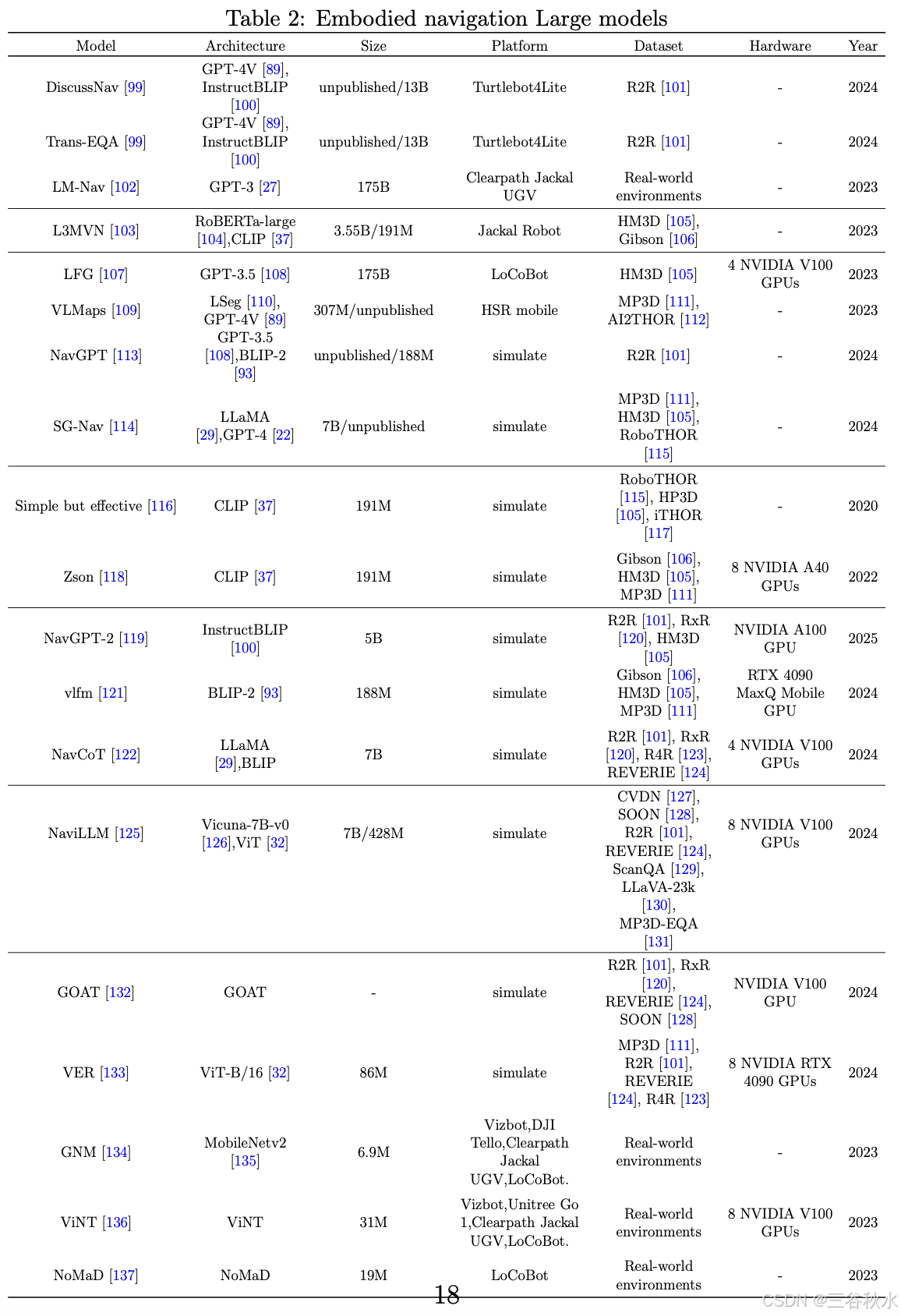
具身交互
传统的机器人交互方法通常需要将感知、决策、规划、控制等独立模块整合起来才能完成特定的任务。随着深度学习的进步,特别是语言和视觉模型的重大进展,具身智能交互已经成为可能。具身智能交互涉及使智能智体和大模型具备多模态处理能力,包括自然语言推理、视觉空间语义感知、视觉感知与语言系统的对接等关键技术。目前,具身智能交互的基础能力要求系统能够理解人类的自然语言指令并自主完成任务。因此,基于语言的具身智能交互成为研究的重点。大致可分为两类:基于语言的短期行动策略和基于语言的长期行动策略。一些交互模型如表所示。
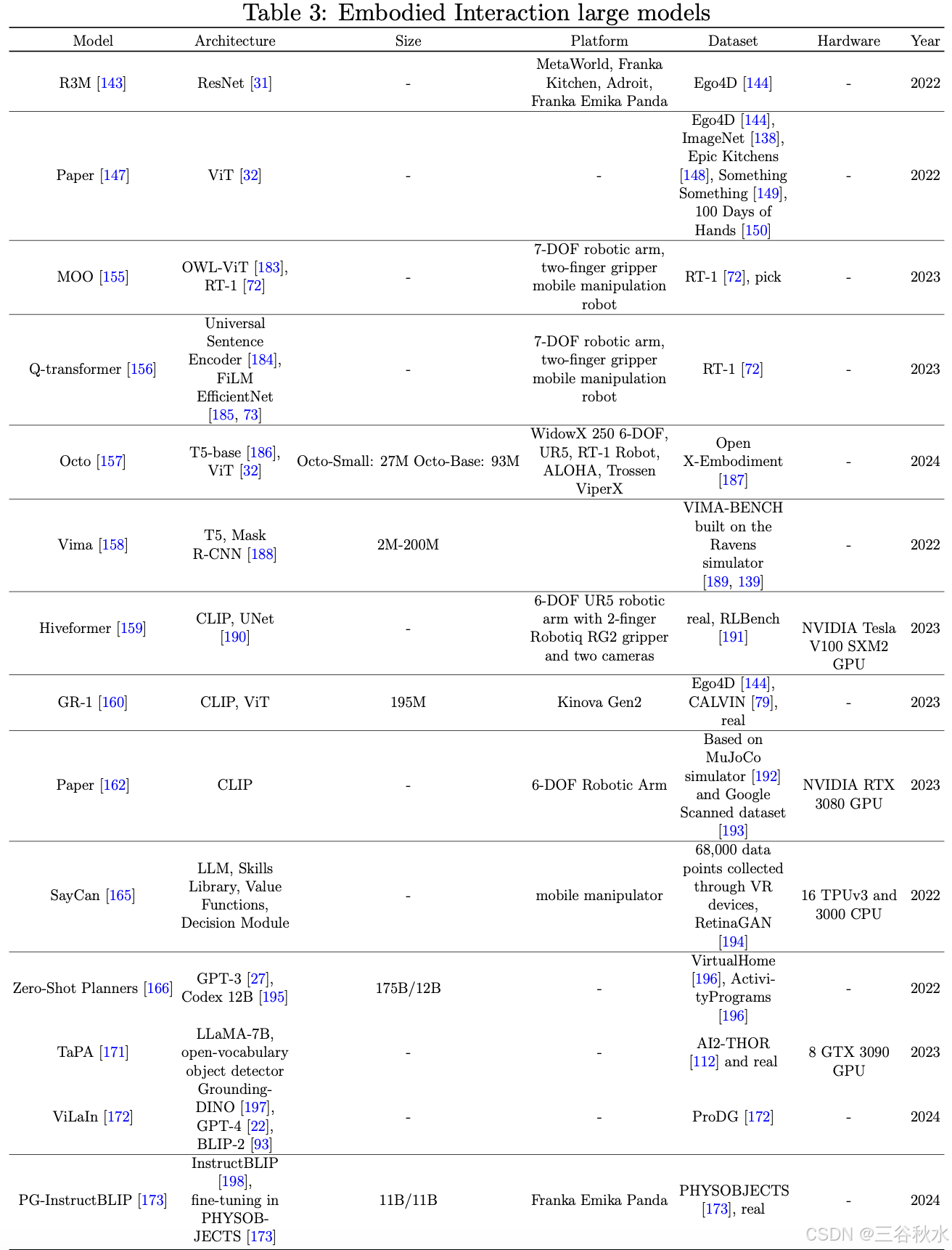
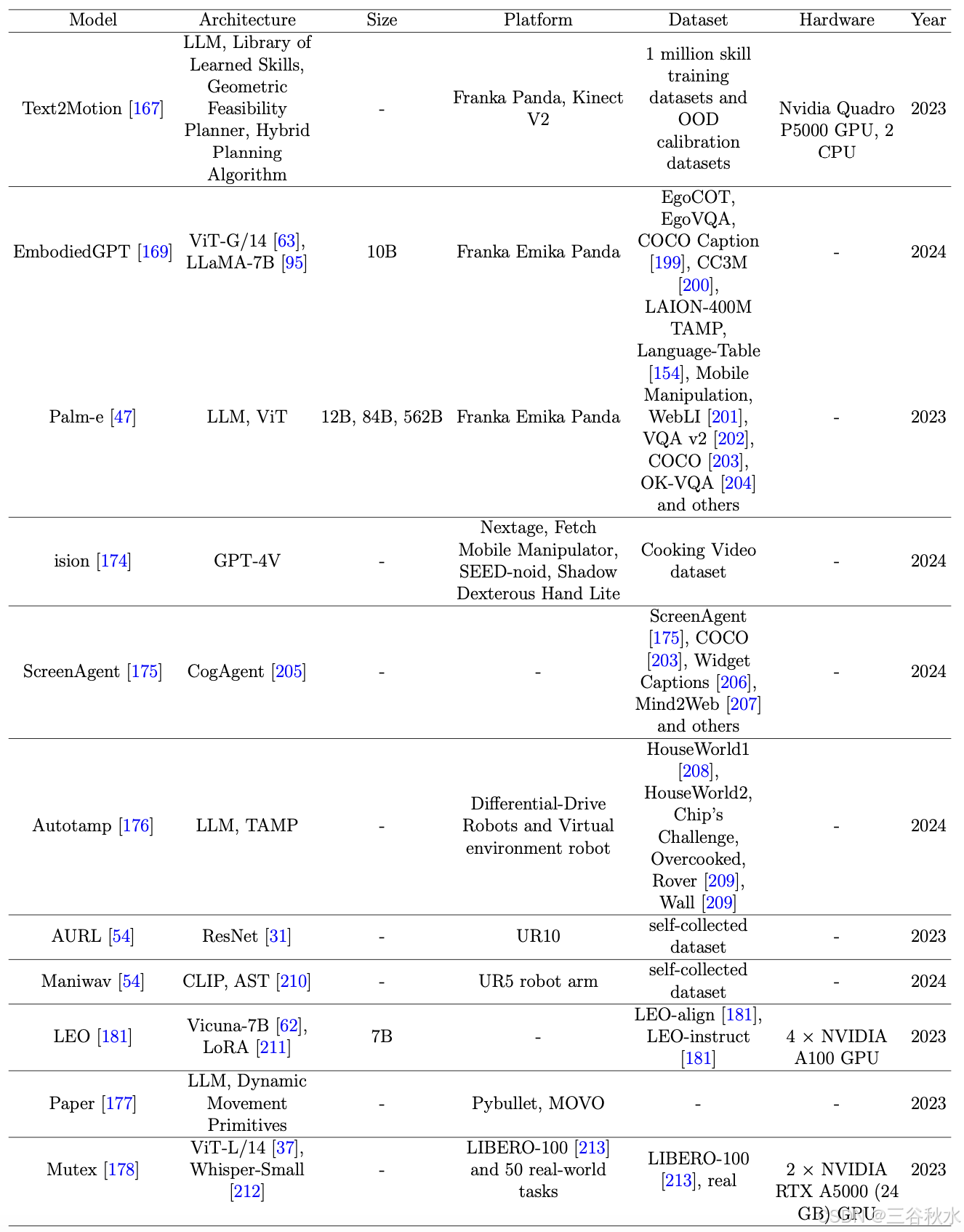
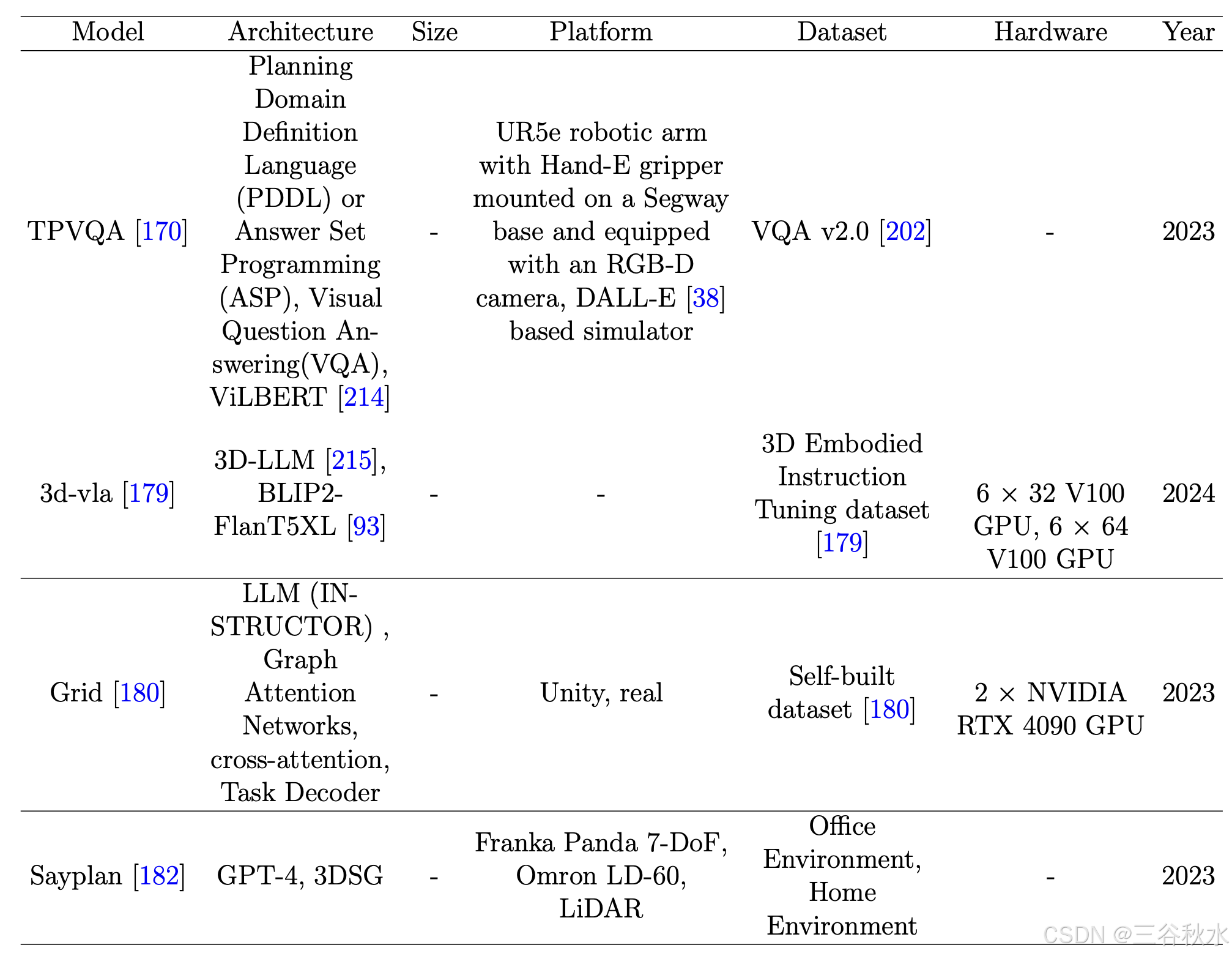
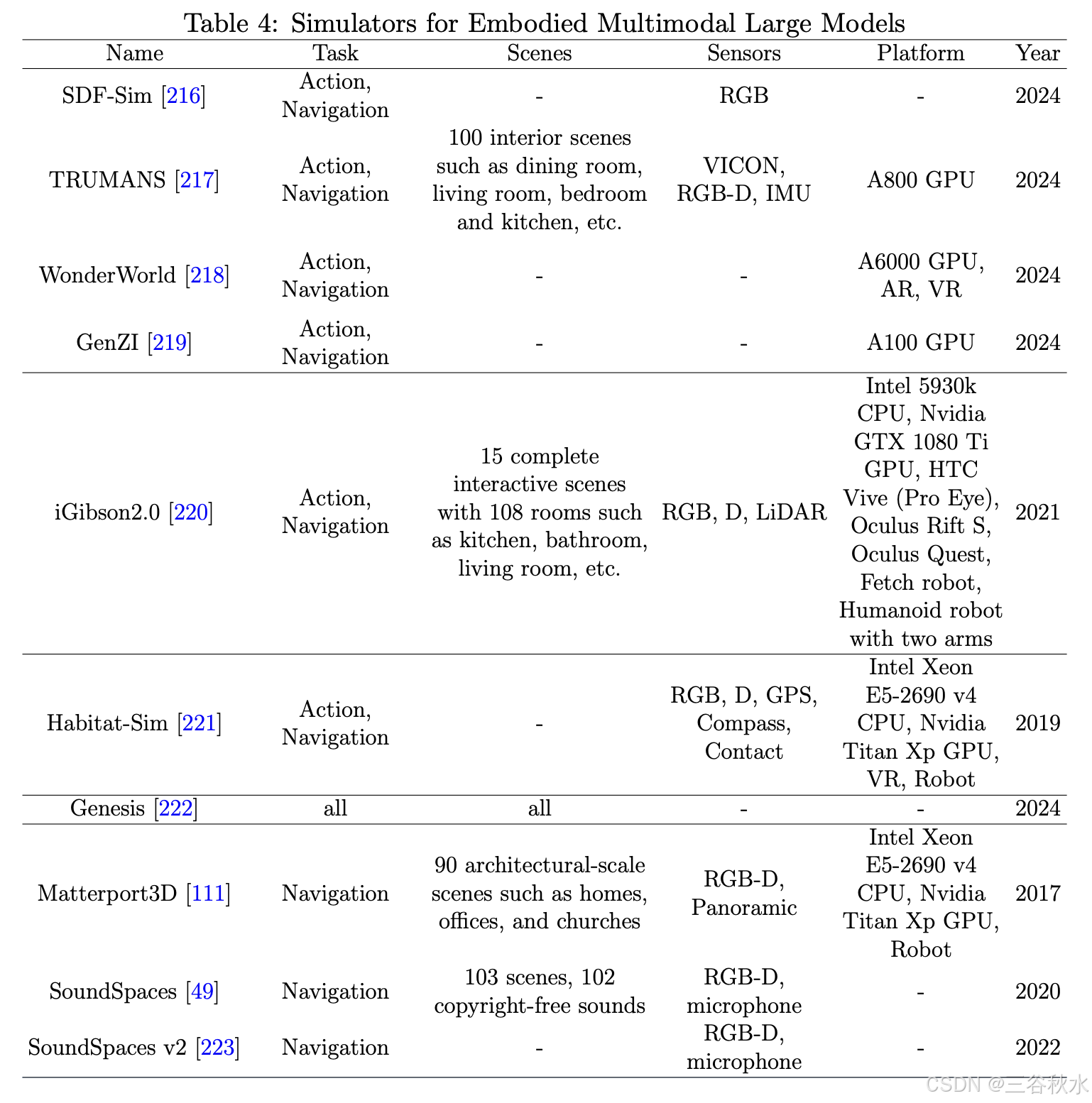
模拟
具身模拟对于具身智能至关重要,因为它允许设计精确控制的条件并优化训练过程。这使得智体能够在各种环境设置中进行测试,从而增强其理解和交互能力。此外,它促进了具身智体本身的跨模态学习,并促进生成数据的训练和评估。为了实现与环境有意义的交互,必须构建一个真实的模拟环境,同时考虑到周围环境的物理特性、物体的属性及其相互作用。模拟平台通常分为两类:基于基础模拟的通用模拟器和基于真实世界场景的模拟器 [11]。下表 显示一些最新和著名的模拟方法和平台。

















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









