










25年3月来自费城宾大的论文“ZeroMimic: Distilling Robotic Manipulation Skills from Web Videos”。
机器人操作领域的许多最新进展都来自模仿学习,但这些进展很大程度上依赖于模仿一种特别难以获得的演示形式:在同一房间内用同一机器人收集的演示,这些演示与训练策略在测试时必须处理的物体相同。相比之下,已经存在大量预先录制的人类视频数据集,展示了野外的操作技能,其中包含对机器人有价值的信息。是否有可能从这些数据中提取出有用的机器人技能策略库,而无需对机器人特定的演示或探索进行任何额外要求?
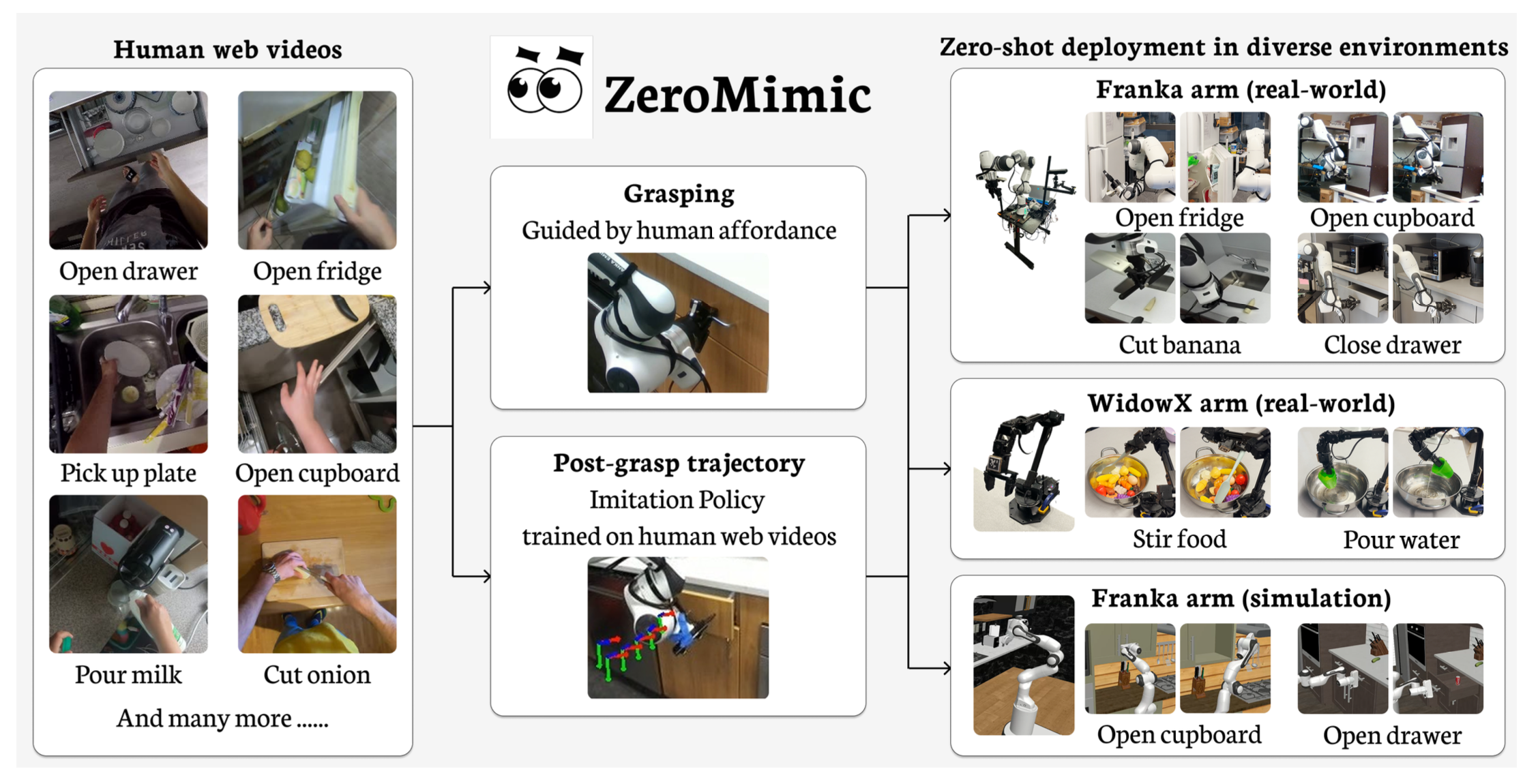
本文提出一个这样的系统 ZeroMimic,它可以为几种常见的操作任务类别(打开、关闭、倾倒、拾取和放置、切割和搅拌)生成可立即部署的图像目标条件技能策略,每种策略都能够作用于不同的物体和不同的未见过任务设置。ZeroMimic 经过精心设计,利用人类视频的语义和几何视觉理解方面的最新进展,以及现代抓握 affordance 检测器和模仿策略类。在流行的 EpicKitchens 以自我为中心的人类视频数据集上训练 ZeroMimic 后,使用两种不同的机器人实例评估它在各种现实世界和模拟厨房环境中的开箱即用性能,展示它处理这些不同任务的出色能力。为了在其他任务设置和机器人上实现 ZeroMimic 策略的即插即用重用,其发布技能策略的软件和策略检查点。
ZeroMimic 如图所示:
显然,动物和人类能够通过观察第三人称体验来获得功能性感觉运动技能,通常是“零样本”的,不需要或只需要很少的额外练习。例如,人们可以通过观看网络上的演示视频来学习烹饪意大利面、使用木工车床、种植花园或打领带,并掌握相当熟练的技能。虽然“模仿学习”在机器人操控方面也发挥了重要作用[1-4],但这些机器人在很大程度上依赖于一种更强大的演示——通过在同一组场景(场景、视点、物体、灯光、背景纹理和干扰物)中手动操作同一个机器人来执行感兴趣的任务。这是开发通用机器人道路上的直接绊脚石:收集机器人和场景特定的演示很难扩展。
从野外人类视频中学习机器人技能提供了诱人的前景,即数据不再是瓶颈:人类在不同场景中演示各种操作任务的视频已经在网上提供,如果需要,很容易收集更多视频,而且相同的视频可以重复用于许多机器人。然而,也存在着严重的挑战。机器人在实施、动作空间和硬件能力方面与人类不同。单个网络视频通常不能方便地呈现如何执行任务的所有细节(例如遮挡、画外的物体和动作,或摇晃的移动摄像机)。最后,野外视频的分布范围非常大,可能难以处理。
近期流行的实现机器人操作的方法 [1–3] 通常依赖于昂贵的高质量领域内机器人演示。因此,机器人学习领域的最新研究越来越多地关注利用非结构化或领域外的数据。一些研究展示了在大型机器人数据集上训练的模型的零样本能力 [6– 14],但此类数据集的管理需要付出巨大成本。一些研究利用 VLM 的最新进展,在与机器人没有任何联系的情况下使用“网络”数据进行训练,并直接引出零样本机器人动作 [15–21]。这些策略受到 VLM 缺乏物理理解和推理速度慢的限制。人类网络视频 [5, 22–26] 由于其丰富性、多样性和丰富的交互信息,成为机器人技能获取的有希望的数据来源。
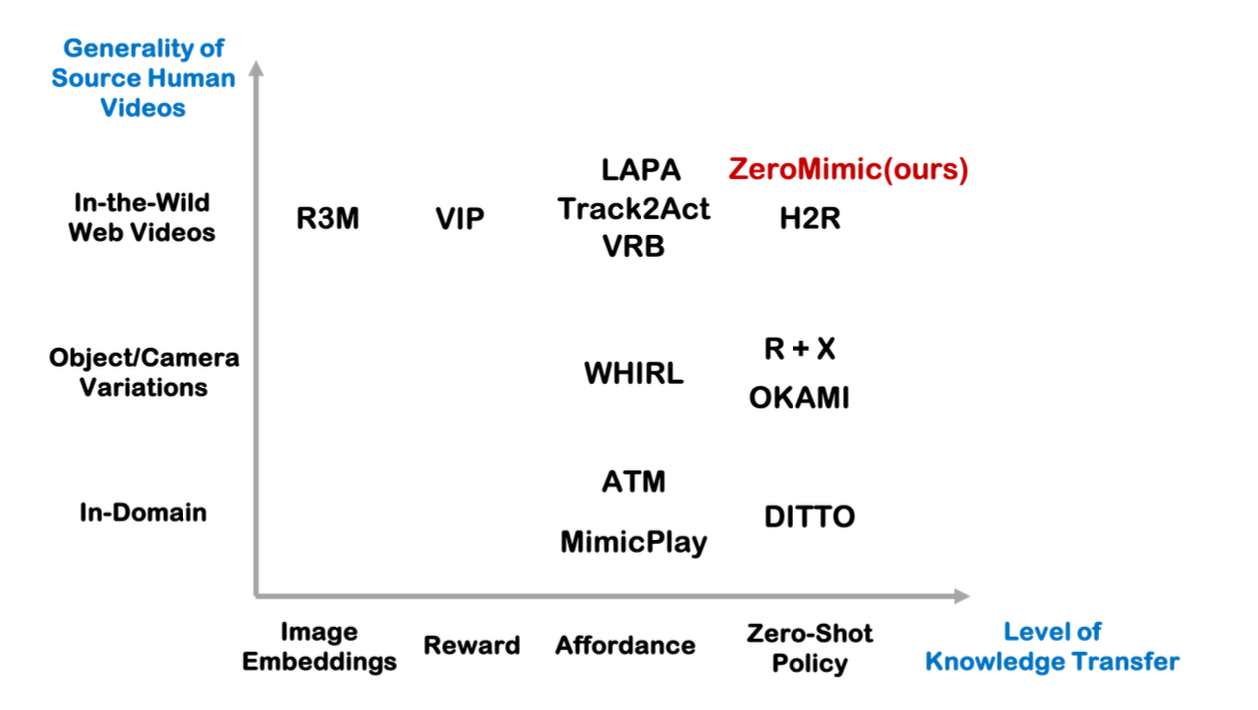
由于直接从领域外的人类视频生成机器人策略很困难,因此许多研究转而训练表示 [27–29](例如 R3M [27])、奖励 [30–33](例如 VIP [31])或 affordance [34–60]。一些研究 [34–45](例如 MimicPlay [34]、WHIRL [36] 和 ATM [39])探索从领域内人类视频中学习 affordance。最近的研究 [46–60](例如 VRB [53]、Track2Act [57]、LAPA [60])将这些方法扩展到从野外人类视频中学习。由于这些视觉表示、奖励函数和 affordance 对于机器人来说不是明确可行的,因此它们仍然依赖于领域内机器人数据来学习操纵策略。
之前的研究 [61–66](例如 DITTO [61]、R+X [64] 和 OKAMI [65])非常有限,旨在直接从人类视频生成策略,而无需任何域内数据。这些方法通常要求人类演示的分布与测试时机器人环境足够相似,并假设了解真值相机和深度信息,这使得它们不适合从多样化和非结构化的网络数据中学习。一些方法还依赖于数据收集过程中从人类手部姿势到机器人夹持器动作的启发式映射 [64] 或手动定义约束公式 [66],限制了这些方法可以处理的演示和任务的范围。
本文提出一种方法 ZeroMimic,它系统地克服这些挑战,并将 EpicKitchens [5] 中的野外自我中心视频蒸馏成一个现成的可部署图像目标条件机器人操作技能策略库,这些策略可在场景之间迁移。
如图所示,之前唯一尝试从真实自然视频中实施零样本策略的研究是 H2R [67],它从以自我为中心的自然 EpicKitchens [5] 视频中学习合理的 3D 手部轨迹,并将其重新定位到机器人末端执行器,以便在真实环境中进行零样本部署。本文也在 EpicKitchens 数据上训练策略,但采用关键的预处理步骤,将数据置于 3D 中并生成更高质量的策略。此外,设计一个强大的系统,将学习到的接触前交互 affordance 和学习的接触后动作策略结合起来。正如实验所示,这些方法的改进转化为在现实世界中为操作技能生成功能性“开箱即用”性能的显著提升。
工作专注于可以分解为两个阶段的操作技能:抓取阶段,包括接近和抓取适合目标任务的感兴趣物体;抓取后阶段,包括在稳定地夹住物体的同时进行刚性操作。这包括拾取和放置、滑轨打开和关闭、铰链打开和关闭、倾倒、切割和搅拌等多种技能。ZeroMimic 对这两个阶段特有的组件进行预训练,然后将它们组合在一起,如图所示。专注于将 EpicKitchens [5] 中的人类视频提炼为机器人技能。对现成的人类数据进行预训练自然会限制方法不依赖于任何特定的机器人系统设计:以带有两指夹持器的静态机械臂为目标,使用 RGB-D 摄像机从机器人工作空间的任何以自我为中心的有利位置观察场景。
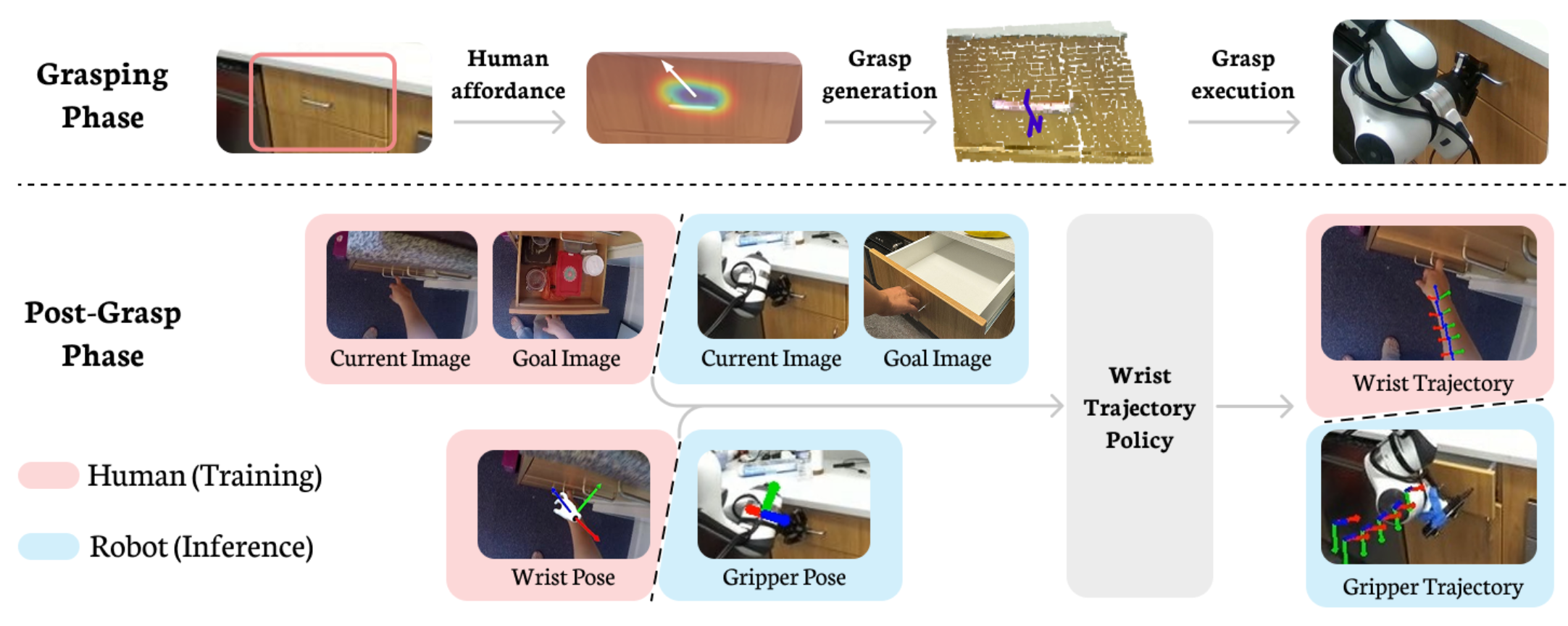
基于人类 affordance 的抓取
在此阶段,用人类视频来学习识别场景中适合执行抓取的区域,即 affordance 预测。在此之后,鉴于人类视频在选择抓取本身方面用处有限,因为机器人的抓取器和人手的体现方式截然不同,使用一种在机器人数据上训练的方法来识别该区域内适合两指抓取器的抓取,即抓取选择。
对于 affordance 预测,使用 VRB [53] 来生成 3D 预期接触点。VRB 在 EpicKitchens [5] 上进行预训练。它根据 RGB 图像和自然语言中的任务描述(例如“打开抽屉”)生成像素空间抓取位置。接下来,为了选择靠近此选定位置的抓取,使用 AnyGrasp [68],这是一种广泛使用的抓取生成模型,已在机器人数据上针对两指机器人抓取器进行预训练。一旦选择抓取,就会规划通过自由空间的线性末端执行器运动来执行该动作。上图 3 显示了上述每个处理阶段后的中间输出示例以及由此产生的抓取执行。
基于人类运动的抓取后机器人策略
一旦机器人抓住物体,它必须决定执行什么 6D 末端执行器轨迹来完成任务。ZeroMimic 的抓取后模块,是一种模仿策略,它从野外人类视频中提取这些信息。首先通过重建手部姿势和以自我中心相机来提取基于世界 3D 坐标的人类手腕轨迹,给定一项技能,获取相应的数据子集并训练技能模型来预测 6D 手腕轨迹。
a) 从网络视频中提取人体手腕轨迹:为了整理多样化和大规模的人类行为,使用 EpicKitchens [5],这是一个野外的自我中心视觉数据集。它包含 100 小时厨房日常活动中的 20M 帧。为了从 EpicKitchens 中提取手腕轨迹,运行 HaMeR [69],这是一种预训练手部跟踪模型,以获得 3D 手势重建。HaMeR 输出所有手部关节相对于标准手的位置和方向,以及与平移 t 相对应的相机参数。通过 COLMAP [70] 运动结构算法推断出相机参数(如 EPIC-Fields [71] 中提供),基于此将这些基于像素坐标的手势输出转换为世界 3-D 坐标。仅考虑腕关节,结果是 T 帧剪辑的 6-D 腕关节轨迹 {h_t = (x_t, y_t, z_t, α_t, β_t, γ_t)}^T,以世界坐标表示。
b) 策略训练、执行和实施细节:学习从网络视频预测轨迹的主要挑战,是人类演示的高度多模态性质——在给定相同图像观察的情况下,有多种方法可以操纵场景中的物体。为了对这种多模态性进行建模,使用最近流行的动作分块Transformer (ACT) [1] 策略类来学习动作序列的生成模型。模型的输入是当前图像 I_t、目标图像 I_g 和当前手腕姿势 h_t,模型输出未来手腕姿势 {h_i},n 是预测块大小。用与任务相关的剪辑中最后一帧作为目标图像。由于在测试时,用静态相机进行机器人实验,因此通过使用每帧的相机外参将所有当前和未来的手腕姿势转换为当前帧的相机坐标,减轻了模型预测相机参数的负担。参见下图,以定性可视化方式显示未见过的人类视频中生成的手腕轨迹。为每项技能训练一个模型,获得一组 9 项技能策略。模型以 n = 10 的块大小预测相对 6D 手腕姿势。对每项技能策略进行 1000 个 epoch 的训练,这在 NVIDIA RTX 3090 GPU 上大约需要 18 个小时。

使用 EpicKitchens [5] 的文本注释来整理与每种操作技能相对应的人类视频数据。在对野外人类视频训练 9 种 ZeroMimic 技能策略后,在现实世界和模拟环境中对机器人进行评估。真实世界评估涵盖了 6 个厨房场景中 18 个目标类别的 30 个不同场景。在模拟中,评估了 4 种技能策略,并在试验中随机化厨房场景。实验中使用的目标实例或场景均未出现在训练数据中。
a) 真实世界实验设置:所有真实世界实验均在宾大校园的 3 个不同的真实厨房和两个不同的机器人(Franka Emika Panda 手臂和 Trossen Robotics WidowX 250 S 手臂)中进行。在评估之前,将摄像机和机器人的摄像机角度大致与以自我为中心视频中人手的相对摄像机角度相似:摄像机与人的高度相同,抓手在人臂可触及的范围内。进行 10 次试验,摄像机和机器人的位置各不相同,大致类似于人类以自我为中心的视角。所有实验的成功取决于它们与人类目标图像提供的目标的一致性。
如图所示Franka 硬件设置:包括一个 7-DOF Franka Emika Panda 手臂,带有一个 Robotiq 2 指夹持器和一个安装在底座上的 Zed 2 立体摄像头。

如图所示WidowX 硬件设置:包括一个 6-DOF Trossen Robotics WidowX 250 S 臂,该臂通过一个两指夹持器和一个 Intel RealSense 深度摄像头 D435 连接到一张桌子上。

b) 模拟实验设置:在 RoboCasa [72] 中进行模拟实验。评估 4 个 ZeroMimic 技能策略,每个策略都涉及 20 次随机厨房试验。对于每次试验,都会改变摄像机和机器人的位置、背景物体和厨房风格(例如,纹理、物体位置)。选择最类似于人类以自我为中心的视角的摄像机视图。
如图所示RoboCasa 模拟设置:包括一个带有 2 指夹持器的 7-DOF Franka Emika Panda 手臂。

如图所示RoboCasa 环境图像展示不同的设置和配置:每幅图像对应不同的厨房环境风格。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









