










25年3月来自伯克利分校的论文“RoboCopilot: Human-in-the-loop Interactive Imitation Learning for Robot Manipulation”。
从人类示范中学习,是学习复杂操作技能的有效方法。然而,现有的方法主要侧重于从被动的人类示范数据中学习,因为其数据收集简单。交互式人类教学具有吸引人的理论和实践特性,但现有的人机界面并没有很好地支持。本文提出了一种系统,可以在双手操作任务中实现人机控制和自主策略之间的无缝切换,从而更有效地学习新任务。这是通过一个兼容的、双边遥操作系统实现的。通过模拟和硬件实验,该系统在交互式人类教学中展示了学习复杂双手操作技能的价值。
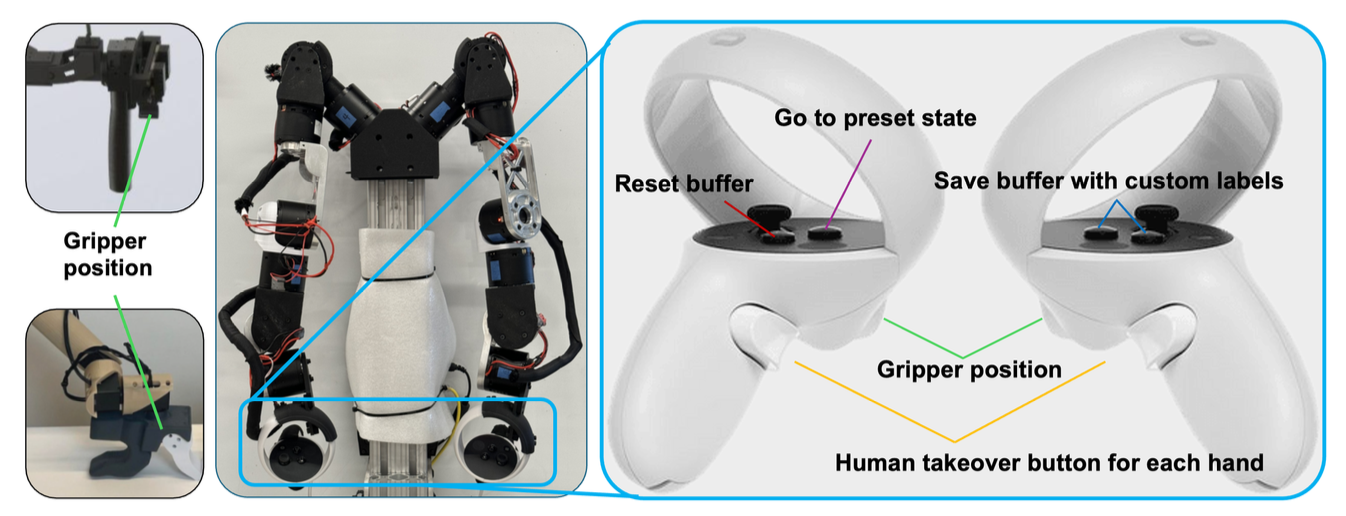
如图所示:RoboCopilot 系统由一个 20 自由度移动双手机器人和一个双边遥操作装置组成。该系统支持轻松的遥操作,并可随时由人机接管,从而构建一个高效的“人-在-环”遥操作系统,实现交互式学习。

在机器人操作的技能教学中,人类扮演着至关重要的角色。数据驱动方法的最新发展,已在从人类示范中学习复杂机器人操作技能方面,展现出良好的成果 [1, 2, 3, 4, 5, 6]。从示范中学习方法的优势,部分源于其简单性:人类提供示范轨迹数据集,然后基于收集的数据集训练策略以模仿人类动作。有了足够多的人类示范数据,策略最终将学会像人类示范者一样执行相同的任务。
然而,这种被动模仿学习范式存在各种效率低下的问题,而交互式学习方法可以克服这些问题。在交互式学习环境中,当机器人出现故障时,人类会接管机器人,并提供纠正行为的示范。数据集聚合 (DAgger) 领域的先前研究,已从理论和实证两个角度表明,纠正性和交互式数据可以通过解决协变量漂移问题来提升策略学习的性能 [7, 8, 9]。然而,现有的人类遥操作系统并非为人工干预而设计的。太空鼠和 VR 设备等遥控器,会将相对姿态变化映射到机器人末端执行器上,这对用户来说并不直观,尤其是在人类可能需要随时接管的交互环境中 [6, 3]。另一方面,虽然基于外骨骼的设备,在收集被动人体数据方面非常有效 [1, 3, 10],但在 DAgger 环境中,将策略部署同步到外骨骼,对人类操作员来说可能存在安全隐患 [11]。尽管最近在多关节机器人系统方面出现了一些易于使用的遥操作工具 [3, 1],但如何利用这些工具实现直观的交互式学习仍是一个难题。
RoboCopilot,是一个旨在通过交互式人类演示来学习双手机器人操作技能的机器人系统。
目标是让机器人能够通过交互式演示不断学习,当自主策略失效时,人类可以接管机器人的控制权,如图所示。由于人类演示、机器人执行和技能学习形成一个紧的学习环,这使得人类操作员能够了解自主策略失效的位置和时间,从而针对模型失效的情况提供更有针对性的演示。
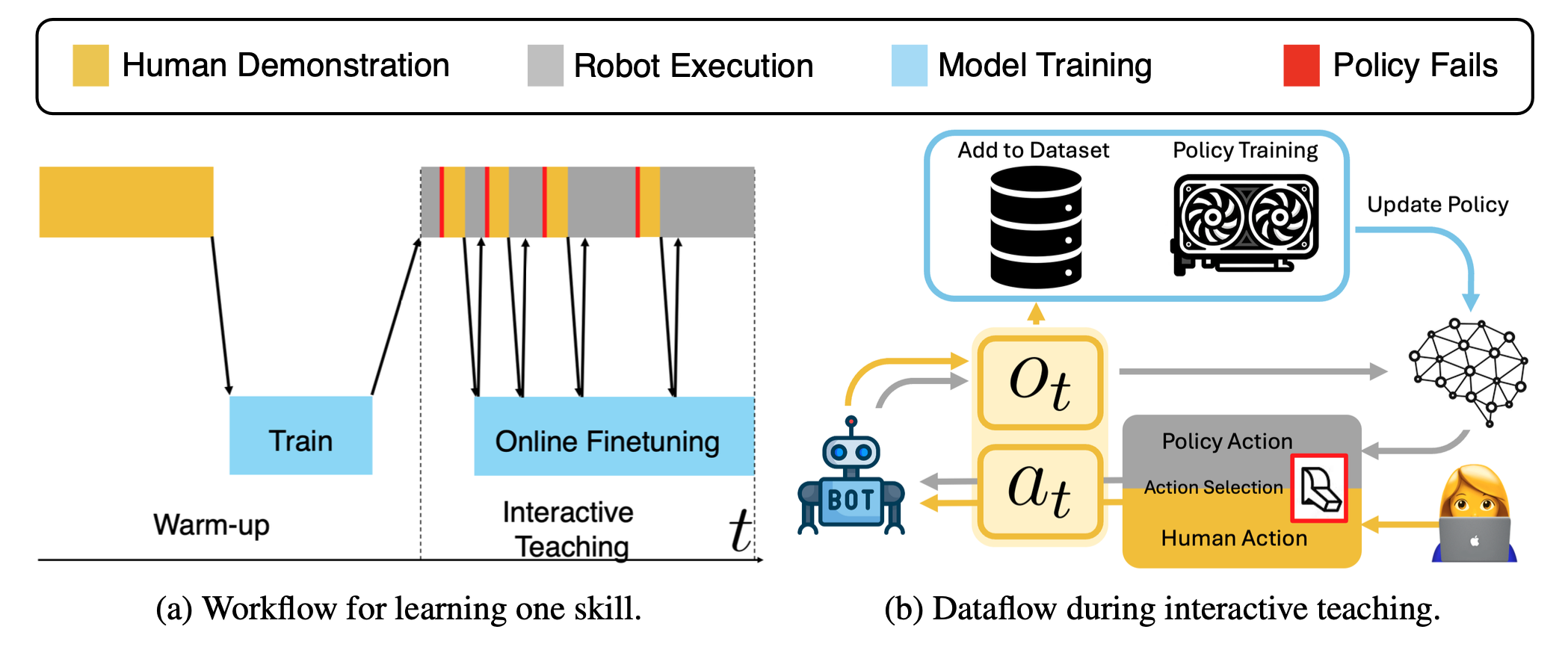
如下算法所示,首先收集 K 条人类演示轨迹来预热策略。遵循 HG-DAgger [22] 算法,允许人类专家决定何时进行干预并控制机器人的执行。来自人类专家的干预数据会被添加到数据集中。在每一轮数据收集之后,会使用所有收集的数据,通过对策略网络进行多次基于梯度的更新来微调策略。策略网络由扩散网络 [2] 参数化。随着策略的改进,所需的干预次数显著减少。

先前的研究表明,持续使用非平稳分布的数据微调神经网络会导致灾难性遗忘 [46, 47]。尽管如此,在交互式教学过程中采用微调,与在数据收集完成后从头开始训练策略相比,它具有多重优势:首先,从当前策略中收集在线样本可以减轻协变量漂移,因为人类可以在必要时进行干预以教学纠正技能。其次,随着策略不断微调和执行,人类操作员可以快速观察当前的故障模式并收集更有针对性的演示。最后,在线学习减少总体训练时间。实际上,一旦交互式教学结束,就可以利用在线交互式数据并从头开始重新训练策略。这样做可以避免训练分布的非平稳性,但仍然利用交互式数据。在实践中,这种方法可以提供可用于部署的最佳策略。这相当于使用数据集 D 重启该算法。
本文开发一款多功能移动双手机器人,它配备强大的遥操作系统,能够在各种现实世界任务中实现人机交互教学。RoboCopilot 遥操作系统由实体机器人、遥操作设备和遥操作工作流程组成。
遥操作系统是实现人机交互模仿学习的有效途径。功能更强大、更人性化的设备使用户能够更精确地控制机器人,从而为后续学习提供更高的数据质量。而对于像无人机或汽车这样动作空间维度较低的动态系统,人们可以更轻松地应用 DAgger 算法,只需让人用操纵杆或方向盘重新标记数据即可[48, 11]。通常,没有明显的方法来重新标记操作轨迹数据的轨迹。这部分原因是由于高维动作空间和复杂的环境动态。
遥操作装置
遥操作领导者装置的核心原则,是最大限度地提高数据采集质量,并方便操作人员在操作和接管过程中使用。木偶操控遥操作装置,是目标臂的低成本近似运动学复制,遵循GELLO [3]。在遥操作引导臂的末端连接一个 Meta Quest 2 控制器 [49],它既可用作符合人体工程学的抓握手柄,又可用作多输入控制装置。先前的研究主要集中于控制手臂的主动部分,但本文方法也考虑到全面且用户友好界面的重要性。如图显示不同遥操作设备的比较。虽然像这样的教学设备并不新鲜,但其主要关注点在于模仿学习。目标是展示如何在交互式学习环境中有效地扩展这些设备的实用性。
主动控制
主动控制引导臂的电机,以减少用户疲劳,并实现更顺畅的人机交互。遥操作设备的重量和惯性,需要用户输入额外的能量来驱动设备。使用操纵器方程的主动重力补偿,减轻了这种负担,使操作员无需过度用力即可操纵系统,从而降低了操作员的疲劳度 [50, 51]。
主动控制还可以实现双边系统,其中引导臂可以将跟随臂感受的力反馈给用户。这使得用户能够理解和感受机器人感受的力,从而更有效地操作机器人。修改 Katz [36] 控制律中使用的 PD 控制律,使用户感受到的是 [36] 中力的一个缩小版本。
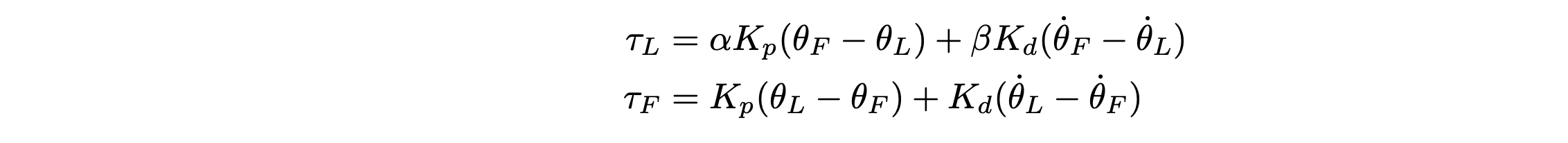
添加 α 和 β 常数,使遥操作设备不会感受手臂的全部惯性,同时仍然能够实现有效的控制。此外,在遥操作设备上使用主动电机,能够在不同情况下灵活地改变 α 和 β 双边系数。
人-机交互学习
RoboCopilot 系统设计人性化,功能齐全,既能促进机器人平稳运行完成任务,又能高效收集数据。遥控操作设备包含多个专用于数据收集的按钮,例如保存数据和重置机器人,从而简化了在操作过程中捕获宝贵数据的流程。这使得遥控操作员能够清晰地了解正在收集的数据,并轻松控制数据质量。
引导臂的控制直观易懂,双向控制使用户能够感受机械臂受到的力。当机器人与环境接触或搬运重物时,此功能尤为有用。当执行自主策略时,引导-跟随关系将反转,此时遥控操作设备将与真实机器人匹配。由于设备已同步,遥控操作设备可以随时通过与遥控操作设备交互来启动接管,而无需中断流程。在机器人策略执行期间,对领导者使用刚性增益来最小化状态差异,而在遥操作模式期间,使用较低的增益来减轻人类遥操作员的力。
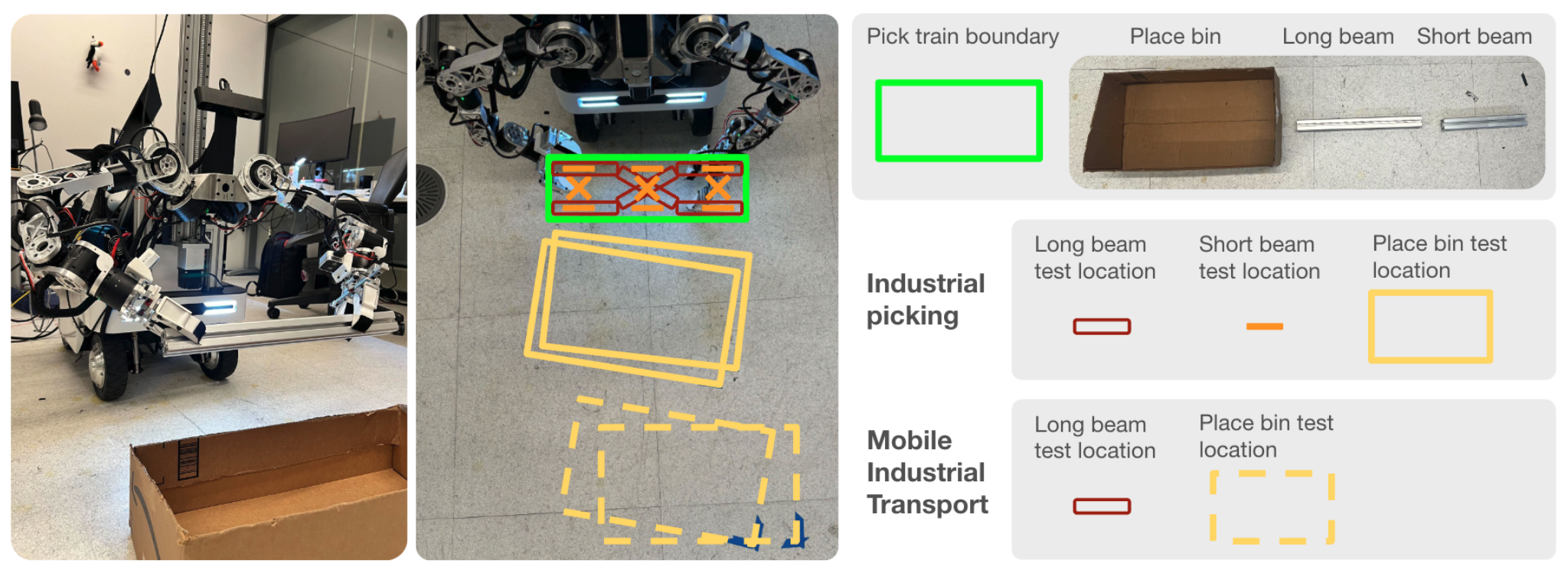
在标准 Robomimic 基准 [14] 上开展模仿学习实验。该基准为一系列机器人操作任务(包括双手操作)提供了人类演示轨迹和模拟环境,展示了该方法在一般操作中的优势。这些实验的目的是在受控的可复现环境中验证该算法的有效性。从基准中选择 Can、Square 和 Transport 任务,如图所示。由于人机交互的易变性,涉及人机交互的实验可能难以复现。

在真实世界中的实验(如图所示),得出与模拟实验类似的结论,即交互式数据收集比专家策略的被动数据收集提供的数据质量更高。随着交互式数据收集的增多,成功率不断提高,对人工干预的需求也相应减少。在实践中,人工干预的需求也是一个有用的信号,可以指示何时停止收集新数据。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









