










25年3月来自哥伦比亚大学的论文“Train Robots in a JIF: Joint Inverse and Forward Dynamics with Human and Robot Demonstrations”。
在大型机器人演示数据集上进行预训练是学习各种操作技能的强大技术,但通常受到收集以机器人为中心数据的高成本和复杂性限制,特别是对于需要触觉反馈的任务。这项工作引入一种使用多模态人类演示进行预训练的新方法来应对这些挑战。该方法联合学习逆动力学和正向动力学来提取潜状态表征,学习特定操作的表征。这使得仅使用少量机器人演示即可进行有效的微调,从而显着提高数据效率。此外,该方法允许使用多模态数据,例如将视觉和触觉结合起来进行操作。通过利用潜动力学建模和触觉感知,这种方法为基于人类演示的可扩展机器人操作学习铺平了道路。
使用模仿学习(IL) [3–5] 或离线强化学习(RL) [6, 7] 对大型机器人演示数据集 [1, 2] 进行预训练,正迅速成为学习各种机器人操作技能的标准技术,甚至推动了基础模型 [8–14] 的开发。然而,这些方法依赖于大量的机器人演示样本,这些样本通常通过遥操作收集,即演示者遥操作正在执行任务的机器人硬件。这一过程的扩展成本很高;如果需要复杂的硬件,例如灵巧操作等需要遥操作员实时触觉反馈的任务,这种方法也不切实际。
相比之下,演示者直接执行相关任务真人演示的获取成本要低得多。此外,柔性触觉传感器正在不断取得进展 [15],在人体指尖安装此类传感器可以保留演示者的触觉,同时在整个演示过程中记录触觉反馈以及常用的视觉观察。这表明,利用此类多模态人体演示进行预训练,有望突破以机器人为中心的数据收集的局限性。
先前的视觉表征学习研究[16–23],例如掩码视觉预训练 (MVP) [20, 24–26],探索利用视频等视觉人体演示进行状态表征学习。然而,这些方法本质上与动力学无关,通常依赖于基于重建的目标函数,而这些目标函数无法捕捉对操作任务至关重要的底层系统动力学。此外,由于依赖于重建高维感官输入,这些方法计算成本高昂,且难以扩展。相比之下,动力学驱动的表征学习通过编码任务相关信息,提供了一种更有前景的替代方案。
动力学驱动的表征学习,涉及学习前向动力学模型,在应用于多模态人体演示时面临挑战。获取动作标签(例如手部关节运动)需要昂贵的传感系统,而现有方法通常依赖于重建高维观测值,这导致计算成本高昂。LAPO [27] 等方法通过联合学习逆向和正向动力学来捕捉特定操作的信息(无需动作标签),从而缓解这些问题。在此基础上,DynaMo [28] 通过老师-学生蒸馏提高效率,同时保留动力学驱动学习的优势。然而,这些方法仅关注机器人演示。
本文将这类方法扩展到使用多模态人类演示进行预训练,从而实现无需动作标签或昂贵重建的表征学习。通过调整联合逆向-正向动力学范式并结合师-生蒸馏,其方法显著提高计算效率。这使得表征学习在现实世界的机器人应用中具有可扩展性和实用性。
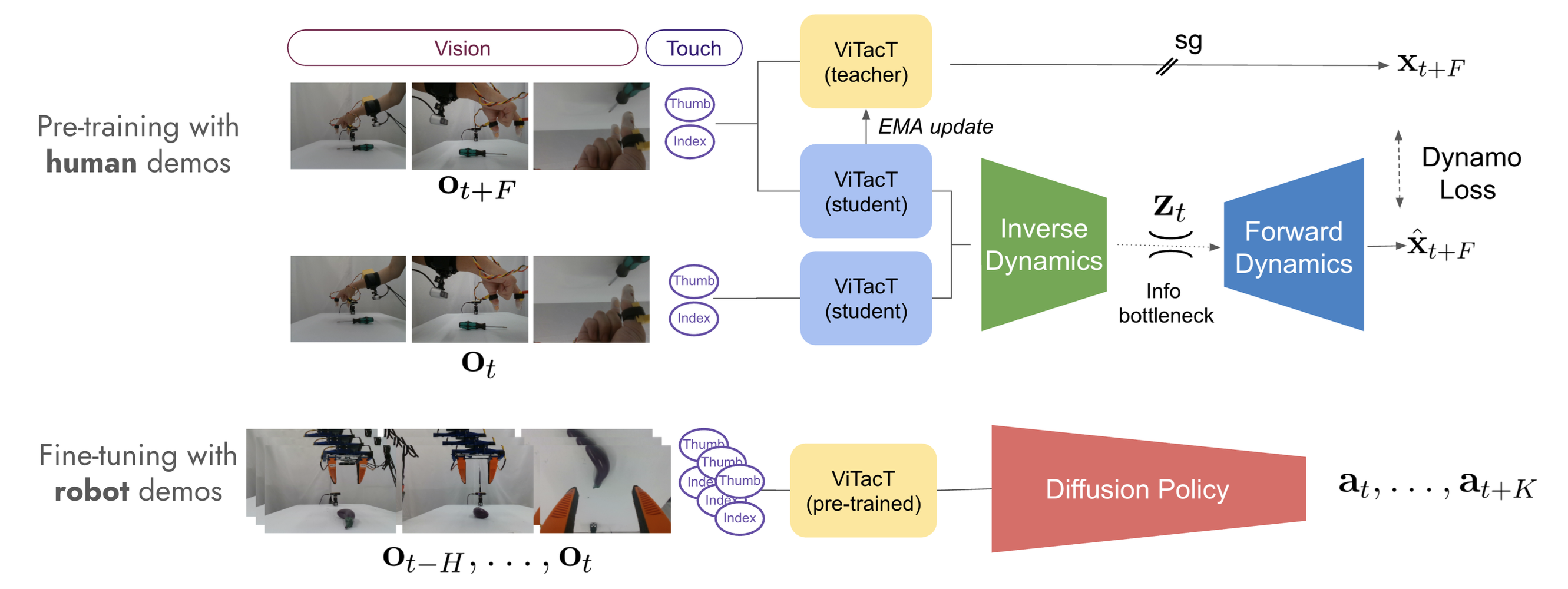
其模仿学习框架,利用多模态人类演示进行预训练,提高在有限的机器人演示样本量下策略学习的效率和效果。本文方法旨在通过一个两阶段过程来解决学习复杂操作技能所面临的挑战:(1)预训练,训练多模态编码器从提供多模态感知数据但不提供动作标签的人类演示中学习潜状态表征;(2)微调,使用较小的机器人演示样本集训练基于扩散的策略。
在预训练过程中,通过联合学习潜空间中的正向和逆向动力学模型来提取结构化的潜状态空间。这样能够从多模态人类演示中捕获与任务相关的特征,而无需显式的动作标签,从而使该过程更具可扩展性和数据效率。为了提升学习表征的质量和鲁棒性,采用知识自蒸馏和师生模式,并利用 DynaMo 损失函数来确保潜表征的有效性。
在微调阶段,训练一个扩散策略,该策略以学习的潜状态表征历史记录为条件,并结合目标或任务标签等条件变量来生成动作。通过利用预训练的编码器,该方法实现高效的模仿学习,减少实现高任务成功率所需的机器人演示次数。
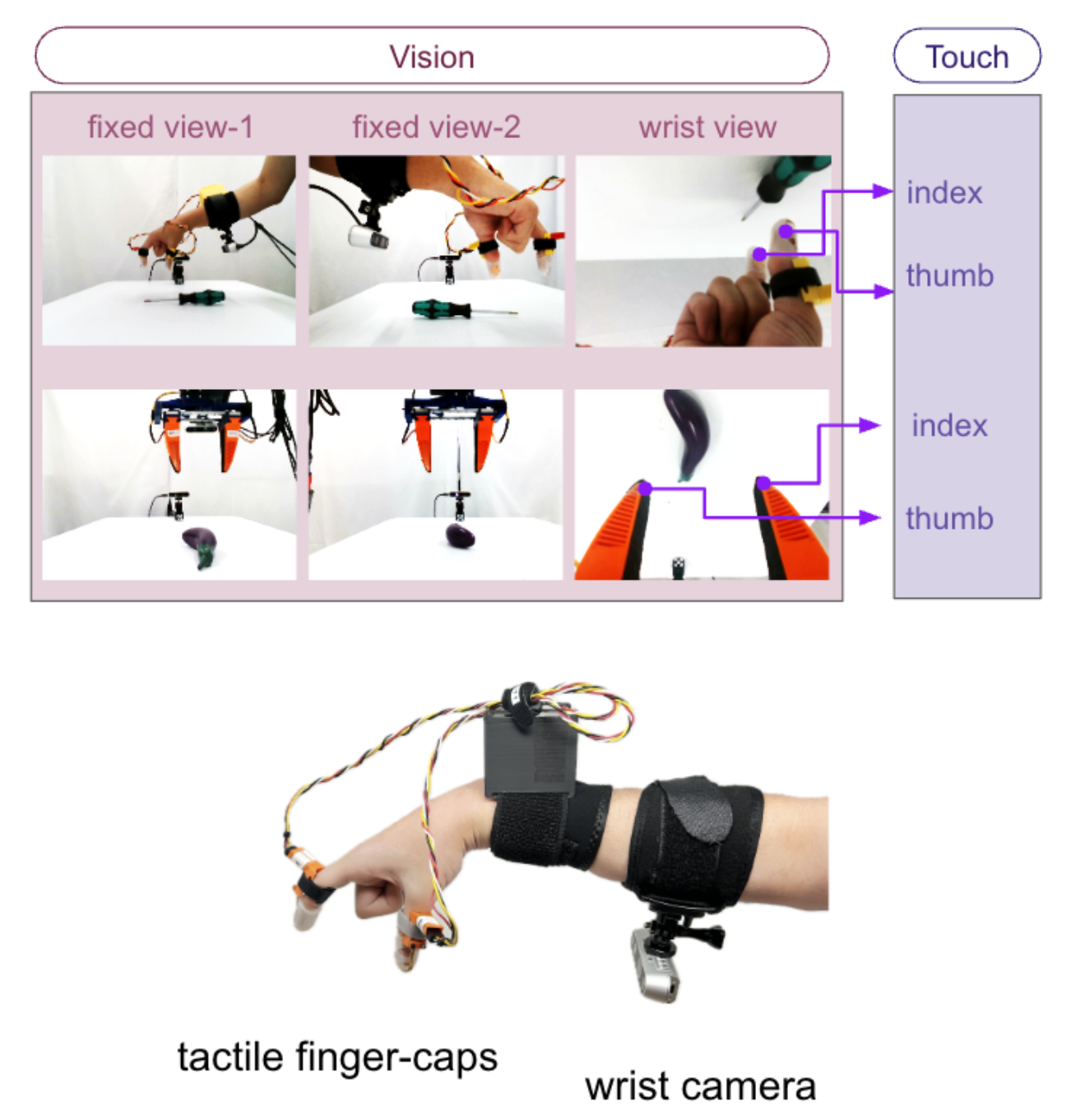
其框架通过 ViTacT 多模态编码器有效地结合视觉和触觉模态,该编码器处理多个摄像头视图和触觉数据,从而生成丰富的潜表征。本研究使用卷积架构,因为它们在小规模数据集上效率更高,但预计基于 Transformer 的方法将提升未来在更大数据集上应用的可扩展性。
如图所示:引入一个使用多模态人类演示进行预训练的框架。通过联合学习逆向和前向动力学(JIF)来提取潜状态表征。动力学驱动的状态表征最大化人类演示中以操作为中心的信息,从而可以通过少量机器人演示进行微调,实现高效且可泛化的模仿学习。
问题定义
设 D_h 为仅包含观测数据的多模态人类演示数据集,包含观测值 (oh_0, …, oh_N);D_r 为通过遥操作获取的带有动作标记的演示数据集 (or_0, ar_0, …, ar_N −1, o^h_N)。注意,人类演示不包含动作。鉴于获取人类演示的容易程度和机器人演示的难度,假设 D_h >> D_r。
目标是利用 D_h 中人类演示的预训练数据,高效地学习针对 D_r 中展示的技能策略。将策略定义为 π(a_t,…,a_t+K | o_t,…,o_t−H, u),其中 o_t,…,o_t−H 表示观察历史,u 是条件变量,例如目标、任务标签或语言指令嵌入。为简单起见,在整个讨论中省略具身上标 h 和 r。
在预训练阶段,试图通过学习潜空间中的动态来预训练多模态编码器 φ。具体而言,构建一个潜在的逆动态模型 h(z_t |x_t , x_t+F) 和一个正向动态模型 f (x_t |x_t , z_t),其中 x_t 是观察 o_t 的潜状态,z_t 是观察对 x_t 和 x_t+F 之间的潜动作。在模仿学习阶段的后期,寻求学习一种扩散策略 ψ(a_t, …, a_t+K|x_t,…, x_t−H, u),该策略根据观察历史生成动作。
使用多模态人体演示进行预训练
在预训练阶段,目标是在潜空间中建模动态,以避免计算成本高昂的重建。令 x_t 和 x_t+F 分别表示通过多模态编码器 φ 获得的观测值 o_t 和 o_t+F 的潜表征。
具体来说,学习一个正向动态模型 f(xˆ_t + F | x_t, z_t),同时训练一个逆向动态模型 h(z_t |x_t, x_t+F)。训练目标是最小化潜空间中的预测误差。
逆动力学模型引入的低维潜动作 z_t 充当信息瓶颈,这对于高效的表征学习至关重要 [27]。然而,单纯地最小化潜状态预测损失,可能会导致潜在崩溃。
为了解决这个问题,采用知识自蒸馏技术,学习两个相同的编码器:一个教师网络 φ_teacher 和一个学生网络 φ_student。这种方法已被证明能够提升表征质量,同时降低内存需求和训练时间,尤其是在高维观测数据的情况下。潜状态 x_t+F 是使用教师网络计算的。
预测的潜状态 xˆ_t+F 的计算方法如下:
- 计算学生嵌入:φ_student(o_t)。
- 预测正向动态 f(xˆ_t + F | x_t, z_t):其中 z_t 从逆向动态模型 h(z_t |x_t, x_t+F) 中采样。
为了确保稳定性和学习效率,最小化潜状态预测损失,其中加入一个正则化项。
最后,将教师编码器 φ_teacher 更新为学生编码器 φ_student 的指数移动平均 (EMA)。这使得知识自蒸馏能够用于学习状态表征。
虽然可以使用各种相似性损失,但使用 Dynamo 损失,因为它已成功用于动态驱动的表征学习。
Dynamo 损失包含两个部分:余弦相似度和协方差正则化项。第一个损失在两个向量彼此偏离时进行惩罚。第二个损失部分是协方差正则化损失,它最小化协方差矩阵的非对角元素,从而促进特征去相关并减少学习特征之间的冗余。因此,总 DynaMo 损失是两个部分的加权和。
在本方法中,φ 是一个 ViTacT 多模态编码器,它处理多个摄像机视图和触觉模态以生成潜表征。每个摄像机视图使用基于 ResNet 的嵌入编码成一个 token,而触觉信号则通过一维卷积处理生成触觉嵌入。这些嵌入随后被用作 Transformer 解码器的输入,从而实现多模态信息的融合,用于下游策略学习。然而,在具有更广泛训练数据的大规模应用中,预计基于块的编码(例如在 Vision Transformer (ViT) 中实现的)将提供更优异的性能,因为 Transformer 架构相比卷积网络具有更佳的扩展特性。在本方法中,利用基于 CNN 的特征提取,因为其工作重点是相对较小的数据规模,而卷积架构在这种规模下仍然有效且计算高效。
基于机器人演示的模仿学习
在第二个模仿学习阶段,训练一个以预训练多模态编码器 φ 提取的潜状态表征为条件的扩散策略,从而促进从有限数量的演示中进行高效学习。具体来说,扩散策略 ψ(a_t,…,a_t+K | x_t,…,x_t−H,u) 基于潜状态的历史记录和条件变量 u(例如目标、任务标签或语言指令)生成动作。在实验中使用历史记录 H = 16 和动作块长度 K = 16。
通过利用预训练编码器 φ,其方法有效地利用人类演示数据来提供信息丰富的潜在表征,从而提高模仿学习的效率。结果显示,这可以在更少的机器人演示次数下实现更快的收敛速度和更好的泛化效果。
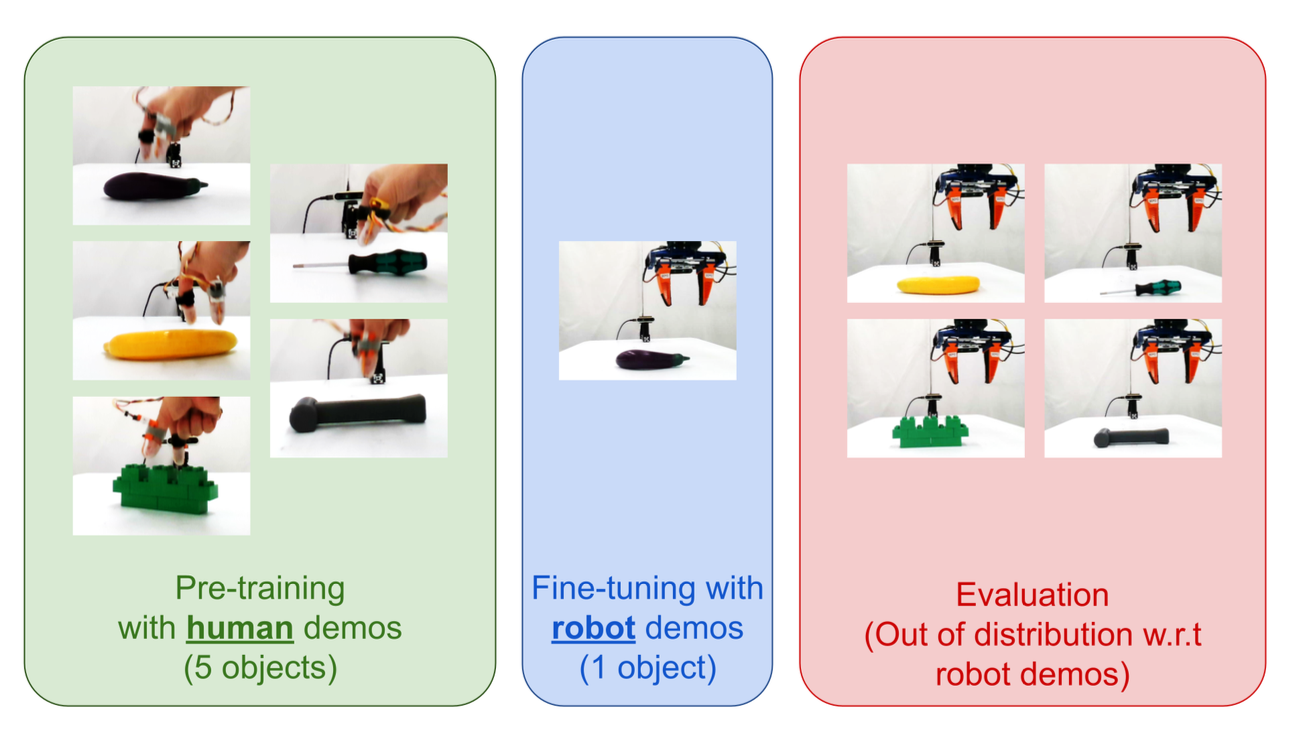
考虑使用配备触觉传感的夹持器抓取桌面上任意方向物体的任务。为此,收集人类和机器人的演示数据,如图所示。人类数据集包含五个物体,每个物体有 1,000 个人类演示。
由于机器人演示需要遥操作,这更具挑战性且耗时,因此仅针对单个物体收集 100 个演示。用于使用人类演示进行预训练、微调和泛化的目标均如图所示。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









