







Abstract
- 文本分类作为一个经典的自然语言处理任务,已经有很多利用卷积神经网络进行文本分类的研究,但是利用图卷积神经网络进行研究的仍然较少。
- 本文基于单词共现和文档单词间的关系构建一个text graph,然后为语料库学习Text GCN,最后用于文本分类。
Introduction
- 背景叙述
- 文本分类的一个重要中间步骤是文本表示。传统的方法用手工制作的特征来表示文本,比如稀疏的词汇特征(词袋)。
- 随着深度学习模型被广泛用于学习文本表示,如:卷积神经网络(CNN)和循环神经网络(RNN)、长短期记忆(LSTM)等。CNN和RNN优先考虑局部性和顺序性,这些深度学习模型可以很好地捕捉局部连续词序列中的语义和句法信息,但可能会忽略带有非连续和长距离语义的语料库中的全局词共出现。近年来,神经网络或图嵌入引起了人们的广泛关注。图神经网络由于具有丰富的关系结构,能够在图嵌入中保存全局的结构信息,因此在处理任务时非常有效。
- 文章工作
- 在本文中,作者提出一种新的基于图神经网络的文本分类方法。作者利用整个语料库,以单词和文档作为节点、利用词的共现信息构建两个词节点之间的边、利用词频和词的文档频率构建词节点与文档节点之间的边,构造一个单独的大型图。然后,使用GCN对图进行建模,将文本分类问题转化为节点分类问题。
- 该方法可以在标注文档比例较小的情况下实现较强的分类性能。
- 代码地址:Text GCN
- 文章贡献
- 提出了一种新的图神经网络文本分类方法,是第一个将整个语料库建模为异构图,并利用图神经网络联合学习单词和文档嵌入的研究。
- 在几个基准数据集上的结果表明,本文的方法在不使用预先训练的单词嵌入或外部知识的情况下,优于最先进的文本分类方法。该方法还可以自动学习预测词和文档的嵌入。
Related Work
-
Traditional Text Classification
传统的文本分类研究主要集中在特征工程和分类算法上。对于特征工程来说,最常用的功能是bag of words功能。此外,还设计了一些更复杂的功能,如n-grams和本体中的实体。目前也有将文本转换为图形以及对图和子图进行特征工程的研究。与这些方法不同,本文的方法可以将文本表示作为节点嵌入自动学习。
-
Deep Learning for Text Classification
- 深度学习文本分类研究可以分为两类:
- 第一类研究侧重于基于单词嵌入的模型。最近的几项研究表明,文本分类深度学习的成功在很大程度上取决于单词嵌入的有效性。一些作者将无监督的单词嵌入聚合为文档嵌入,然后将这些文档嵌入输入分类器。我们的工作与这些方法有关,主要区别在于这些方法在学习单词嵌入后构建文本表示,而本文的方法同时学习单词和文档嵌入进行文本分类。
- 第二类研究采用深度学习的方法。两个具有代表性的深度网络是CNN和RNN。尽管这些方法有效且应用广泛,但它们主要关注局部连续词序列,而没有明确使用语料库中的全局词共现信息。
-
Graph Neural Networks
Kipf和Welling在2017年提出了一种简化的图形神经网络模型,称为图形卷积网络(GCN),该模型在许多基准图形数据集上获得了最先进的分类结果。GCN也在几个NLP任务中进行了探索,如语义角色标记、关系分类和机器翻译,其中GCN用于对句子的句法结构进行编码。最近的一些研究探索了用于文本分类的图形神经网络。然而,他们要么将文档或句子视为图的节点,要么依赖不常用的文档引用关系构建图表。作者在构建语料库图时,将文档和单词视为节点(因此是异构图),不需要文档间的关系。
Method
Graph Convolutional Networks (GCN)
GCN是一种多层神经网络,它直接在图上操作,并根据其邻域的属性导出其节点的嵌入向量。
- 形式定义:图 G = ( V , E ) G=(V,E) G=(V,E),则 V V V 是顶点集合, E E E 是边集合。每个节点都存在到自身的边,即对 ∀ v ∈ V , ∃ ( v , v ) ∈ E \forall v\in V,\exist(v,v)\in E ∀v∈V,∃(v,v)∈E。设 X ∈ R n × m X \in \mathbb{R}^{n \times m} X∈Rn×m 是包含所有顶点及其特征的矩阵,其中 m m m 是特征向量的维数,每行的 x v ∈ R m x_{v} \in \mathbb{R}^{m} xv∈Rm 是 v v v 的特征向量。由此引出图 G G G 的邻接矩阵 A A A 和度矩阵 D D D,其中 D i i = ∑ j A i j D_{i i}=\sum_{j} A_{i j} Dii=∑jAij。
- 对于单层GCN,新的 k k k 维节点特征矩阵 L ( 1 ) ∈ R n × k L^{(1)} \in \mathbb{R}^{n \times k} L(1)∈Rn×k,可由 L ( 1 ) = ρ ( A ~ X W 0 ) L^{(1)}=\rho\left(\tilde{A} X W_{0}\right) L(1)=ρ(A~XW0) 计算得到,其中 A ~ = D − 1 2 A D − 1 2 \tilde{A}=D^{-\frac{1}{2}} A D^{-\frac{1}{2}} A~=D−21AD−21是归一化对称邻接矩阵 , W 0 ∈ R m × k W_{0} \in \mathbb{R}^{m \times k} W0∈Rm×k是一个权重矩阵, ρ ( x ) = max ( 0 , x ) \rho(x)=\max (0, x) ρ(x)=max(0,x)是一个ReLU激活函数。
- 单层GCN只能捕获具有一层卷积的近邻信息。当多个GCN层堆叠时,更高阶的邻域信息将被整合。可以通过叠加多个GCN层来整合高阶邻域信息: L ( j + 1 ) = ρ ( A ~ L ( j ) W j ) L^{(j+1)}=\rho\left(\tilde{A} L^{(j)} W_{j}\right) L(j+1)=ρ(A~L(j)Wj),其中 j j j代表GCN的层数, L ( 0 ) = X L^{(0)}=X L(0)=X。
Text Graph Convolutional Networks (Text GCN)
- 作者依托语料库构建了一个大型的异构文本图,其中包含单词节点和文档节点,以便可以显式地对全局单词共现进行建模,并且可以很容易地调整图形卷积。Word Document Graph中结点数=语料库中文档的数量+语料库中唯一单词数的数量。文本GCN的示意图如下所示:
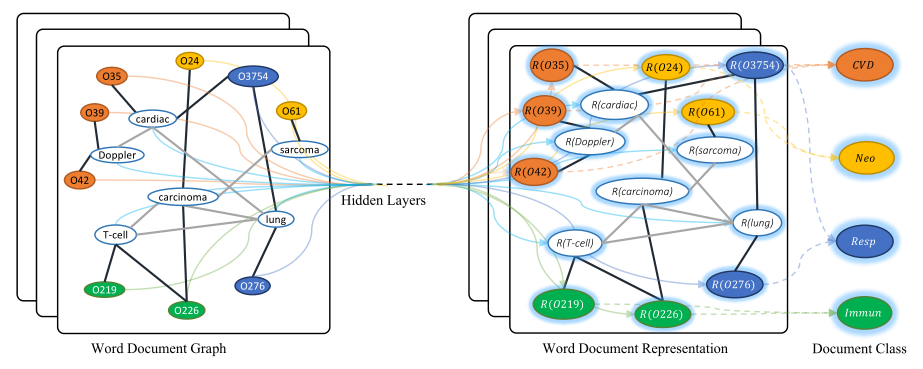
示例取自Ohsumed语料库。
- 以“O”开头的节点是文档节点,其他节点是word节点。
- 黑色粗体边缘是document-word边,灰色细边是word-word 边缘。
- R ( x ) R(x) R(x)代表 x x x的嵌入表示。
- 不同的颜色表示不同的文档类。这里为了避免混乱,只显示了四个示例类,CVD:心血管疾病,Neo:肿瘤,Resp:呼吸道疾病,Immun:免疫性疾病。
- 作者基于文档中的词出现情况(document-word edges)和整个语料库中的词的共现(word-word edges)在节点之间建立边。
- 文档节点和单词节点之间边的权重是文档中单词的术语频率逆文档频率(TF-IDF),其中术语频率是单词在文档中出现的次数,逆文档频率是包含该单词的文档数的对数反比分数。
- 为了利用全局词共现信息,作者对语料库中的所有文档使用固定大小的滑动窗口来收集共现统计信息,并使用点态互信息(PMI)来计算两个词节点之间的权重,PMI是一种常用的词关联度量。一对单词间的PMI值可以通过 PMI ( i , j ) = log p ( i , j ) p ( i ) p ( j ) \operatorname{PMI}(i, j)=\log \frac{p(i, j)}{p(i) p(j)} PMI(i,j)=logp(i)p(j)p(i,j)计算,其中 p ( i , j ) = # W ( i , j ) # W p(i, j)=\frac{\# W(i, j)}{\# W} p(i,j)=#W#W(i,j), p ( i ) = # W ( i ) # W p(i)=\frac{\# W(i)}{\# W} p(i)=#W#W(i), # W ( i ) \# W(i) #W(i)是包含单词 i i i的语料库中滑动窗口的数量, # W ( i , j ) \# W(i,j) #W(i,j)是同时包含单词 i i i和 j j j的滑动窗口的数量。 # W \# W #W是语料库中滑动窗口的总数。正的PMI值意味着语料库中单词的高度语义相关性,而负的PMI值意味着语料库中几乎没有语义相关性。因此,我们只在PMI值为正的词对之间添加边。
- 因此,节点 i , j i,j i,j之间的权重可以定义为: A i j = { PMI ( i , j ) i , j are words, PMI ( i , j ) > 0 TF-IDF i j i is document, j is word 1 i = j 0 otherwise A_{i j}= \begin{cases}\operatorname{PMI}(i, j) & i, j \text { are words, } \operatorname{PMI}(i, j)>0 \\ \operatorname{TF-I D F}_{i j} & i \text { is document, } j \text { is word } \\ 1 & i=j \\ 0 & \text { otherwise }\end{cases} Aij=⎩⎪⎪⎪⎨⎪⎪⎪⎧PMI(i,j)TF-IDFij10i,j are words, PMI(i,j)>0i is document, j is word i=j otherwise 。
- 将构建好的Text Graph输入到一个简单的两层GCN中。
- E 1 = A ~ X W 0 E_1=\tilde{A} X W_{0} E1=A~XW0包含第一层 document和Word嵌入。
- E 2 = ( A ~ ReLU ( A ~ X W 0 ) W 1 ) E_2=\left(\tilde{A} \operatorname{ReLU}\left(\tilde{A} X W_{0}\right) W_{1}\right) E2=(A~ReLU(A~XW0)W1)包含第二层 document和Word嵌入。
- 将 E 2 E_2 E2输入到Softmax分类器中: Z = softmax ( A ~ ReLU ( A ~ X W 0 ) W 1 ) Z=\operatorname{softmax}\left(\tilde{A} \operatorname{ReLU}\left(\tilde{A} X W_{0}\right) W_{1}\right) Z=softmax(A~ReLU(A~XW0)W1),其中 A ~ = D − 1 2 A D − 1 2 \tilde{A}=D^{-\frac{1}{2}} A D^{-\frac{1}{2}} A~=D−21AD−21, softmax ( x i ) = 1 Z exp ( x i ) \operatorname{softmax}\left(x_{i}\right)=\frac{1}{\mathcal{Z}} \exp \left(x_{i}\right) softmax(xi)=Z1exp(xi), Z = ∑ i exp ( x i ) \mathcal{Z}=\sum_{i} \exp \left(x_{i}\right) Z=∑iexp(xi)。权重参数 W 0 W_0 W0 和 W 1 W_1 W1 可以通过梯度下降来训练。
- 损失函数被定义为所有标记文档上的交叉熵误差: L = − ∑ d ∈ Y D ∑ f = 1 F Y d f ln Z d f \mathcal{L}=-\sum_{d \in \mathcal{Y}_{D}} \sum_{f=1}^{F} Y_{d f} \ln Z_{d f} L=−∑d∈YD∑f=1FYdflnZdf,其中 Y D \mathcal{Y}_{D} YD是具有标签的文档索引集, F F F是输出特征的维度等于类的数量, Y Y Y是标签指示器矩阵。
Experiment
Datasets
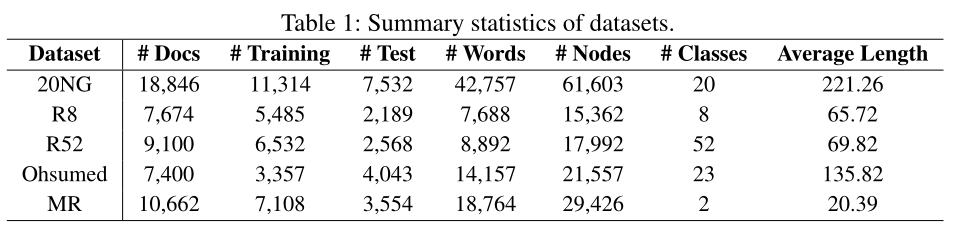
- 20-Newsgroups (20NG):20NG数据集包含18846个文档,平均分为20个不同类别。训练集中总共有11314份文档,测试集中有7532份文档。
- Ohsumed:Ohsumed 语料来自MEDLINE数据库,该数据库是国家医学图书馆维护的重要医学文献书目数据库。作者在1991年的前20000篇摘要中使用了13929篇独特的心血管疾病摘要。集合中的每个文档都有23个疾病类别中的一个或多个关联类别。当我们关注单标签文本分类时,属于多个类别的文档被排除在外,因此只剩下7400个属于一个类别的文档。训练集中有3357份文档,测试集中有4043份文档。
- R5和R8:R52和R8是路透社21578数据集的两个子集。R8有8个类别,分为5485个训练文档和2189个测试文档。R52有52个类别,分为6532个训练文档和2568个测试文档。
- MR:MR是一个用于二元情感分类的电影评论数据集,每个评论只包含一句话。语料库中有5331篇正面评论和5331篇负面评论。
- 预处理数据集后的统计信息如下表所示:
Settings
- 对于Text GCN,我们将第一个卷积层的嵌入大小设置为200,并将窗口大小设置为20。
- learning rate:0.02
- dropout rate:0.5
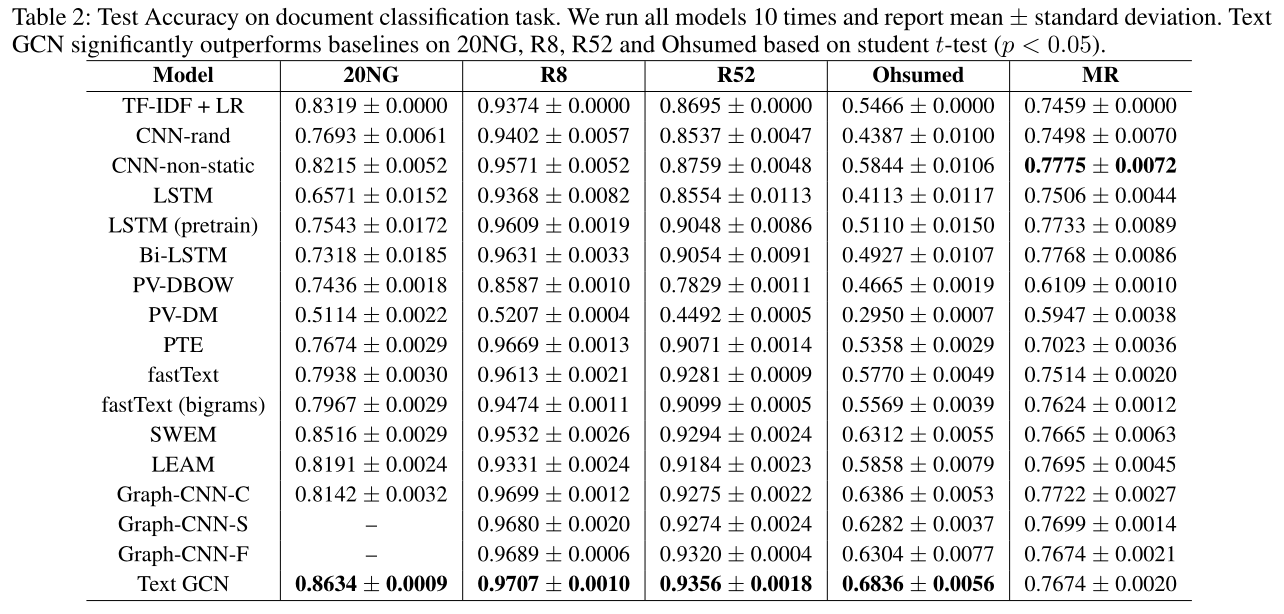
Test Performance














 668
668











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









