







 超级会员免费看
超级会员免费看
在《微调实操三:人类反馈对语言模型进行强化学习(RLHF)》中提到过第三阶段有2个方法,一种是是RLHF, 另外一种就是今天的DPO方法, DPO通过直接优化语言模型来实现对其行为的精确控制,而无需使用复杂的强化学习,也可以有效学习到人类偏好,DPO相较于RLHF更容易实现且易于训练,效果更好.
1、DPO VS RLHF
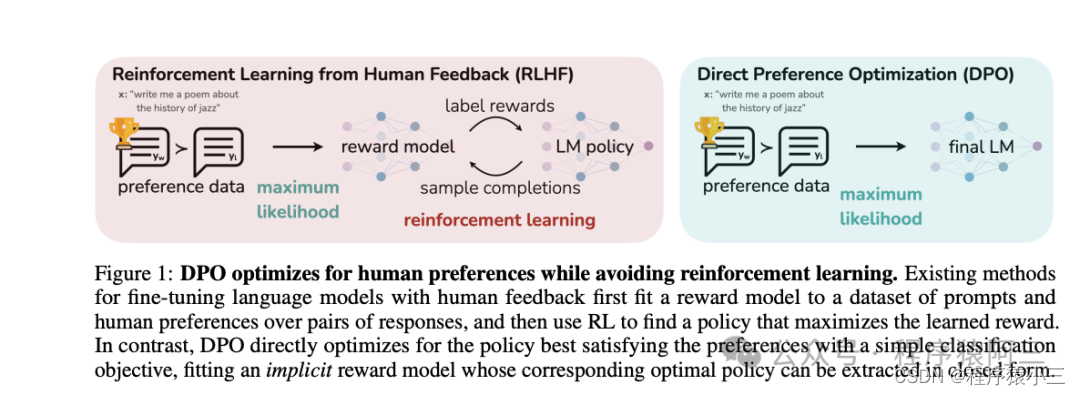
DPO 是一种自动微调方法,它通过最大化预训练模型在特定任务上的奖励来优化模型参数。与传统的微调方法相比,DPO 绕过了建模奖励函数这一步,而是通过直接在偏好数据上优化模型来提高性能。相对RLHF两阶段而言具有多项优越性:
(1)简单性:DPO更容易实施和培训,使其更易于使用。
(2)稳定性:不易陷入局部最优,保证训练过程更加可靠。
(3)效率:与RLHF 相比, DPO 需要更少的计算资源和数据,使其计算量轻。
(4)有效性:实验结果表明,DPO在情感控制、摘要和对话生成等任务中可以优于 RLHF 。
并不是说DPO没有奖励模型, 而是利用同个阶段训练建立模型和强化学习, 在 DPO 中,目标函数是优化模型参数以最大化奖励的函数。除了奖励最大化目标外,还需要添加一个相对于参考模型的 KL 惩罚项,以防止模型学习作弊或钻营奖励模型。

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 6773
6773

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











