









欢迎关注[【AGI 论文精读】](https://blog.csdn.net/youcans/category_12321605.html)原创作品
【DeepSeek论文精读】1. 从 DeepSeek LLM 到 DeepSeek R1
【DeepSeek论文精读】7. DeepSeek 的发展历程与关键技术
本系列前文已经逐篇介绍了从 DeepSeek LLM、DeepSeek MoE、DeepSeek V2、DeepSeek V3 到 DeepSeek R1 的内容。本文围绕 DeepSeek 系列论文和模型的发展历程,从基础架构探索、混合专家(MoE)优化、高效推理突破、强化学习驱动 四个阶段 进行总结和分析,
1. DeepSeek 的发展历程
1.1 DeepSeek 发展历程
DeepSeek 系列在技术创新的道路上不断发展,从最初的DeepSeek LLM、DeepSeekMoE、DeepSeekMath,再到DeepSeek V2、DeepSeek V3 以及最新的 DeepSeek R1,在模型架构、训练方法、数据集开发等方面持续创新。
-
DeepSeek LLM :
2024 年 1 月发布。使用 GQA 优化推理成本;采用多步学习速率调度器替代余弦调度器;运用 HAI-LLM 训练框架优化训练基础设施;提出新的缩放分配策略。使用 2 万亿字符双语数据集预训练,67B 模型性能超越 LLaMA-2 70B,Chat 版本优于 GPT-3.5。 -
DeepSeekMoE :
发布于 2024 年 1 月。创新提出细粒度专家分割和共享专家隔离;采用专家级和设备级平衡损失缓解负载不均衡问题。通过监督微调构建了聊天模型,性能优于传统 MoE 和部分密集模型,16B 版本可在单 40GB 内存 GPU 上部署。 -
DeepSeekMath :
2024 年 2 月 5 日发布。通过数学预训练、监督微调、强化学习三阶段训练,构建 120B 数学语料库,提出 GRPO (Group Relative Policy Optimization)算法,在数学推理能力上直逼 GPT-4,超越众多 30B-70B 开源模型。 -
DeepSeek V2 :
2024 年 5 月 7 日发布。创新提出多头潜在注意力( MLA);改进 MoE;基于 YaRN 扩展长上下文;发布了 Lite 版本;训练中设计三种辅助损失并引入 Token-Dropping 策略,通过多阶段训练流程提升性能。 -
DeepSeek V3 :
2024 年 12 月 26 日发布。创新提出无辅助损失的负载均衡策略、多 Token 预测,有 FP8 混合精度训练框架和高效通信框架。通过知识蒸馏提升推理性能,在低训练成本下性能强大,基础模型超越其他开源模型,聊天版本与领先闭源模型性能相当。 -
DeepSeek R1 :
2025 年 1 月发布。DeepSeek-R1-Zero 无需 SFT 就有卓越推理能力,与 OpenAI-o1-0912 在 AIME 上性能相当;DeepSeek-R1 采用多阶段训练和冷启动数据,推理性能与 OpenAI-o1-1217 相当;还提炼出6 个蒸馏模型,显著提升小模型推理能力。
1.2 DeepSeek LLM
DeepSeek LLM 属于密集的LLM模型,沿用了 LLaMA 的部分设计,如采用Pre-Norm结构、RMSNorm函数、SwiGLU激活函数和Rotary Embedding位置编码。
关键技术 :
- 基于 Transformer 架构,采用分组查询注意力(GQA)优化推理成本。
- 支持多步学习率调度器,提升训练效率。
- 在预训练和对齐(监督微调与 DPO)方面进行了创新。
- 缩放定律研究 :提出了新的最优模型/数据扩展-缩放分配策略。
1.3 DeepSeek MoE
DeepSeekMoE 是一种创新的MoE架构,专门设计用于实现终极专家专业化(expert specialization)。
关键技术 :
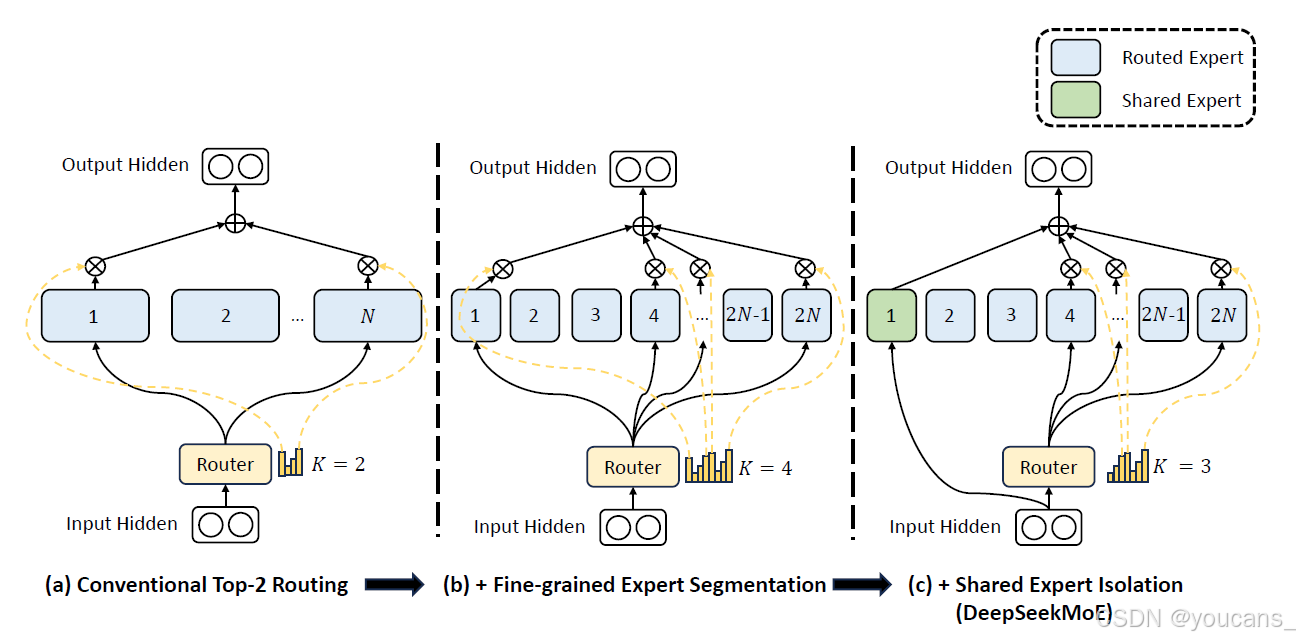
- 细粒度专家分割 (Fine-Grained Expert Segmentation):将专家细分为更细的粒度,以实现更高的专家专业化和更准确的知识获取。
- 共享专家隔离 (Shared Expert Isolation):隔离一些共享专家以减轻路由专家之间的知识冗余。
- 负载均衡的辅助损失 (Auxiliary Loss for Load Balance):通过专家级平衡损失和设备级平衡损失,缓解模型训练时可能出现负载不均衡问题。
1.4 DeepSeek Math
DeepSeekMath 是数学推理模型。
关键技术 :
- 数学预训练:代码训练可提升数学推理能力。
- 监督微调:构建多格式数学指令微调数据集。
- 强化学习:提出 GRPO(Group Relative Policy Optimization)算法,通过组分数估计基线,减少训练资源消耗。
1.5 DeepSeek V2
DeepSeek V2 是一款 经济高效的大规模MoE模型,优化推理与训练成本。
关键技术:
- DeepseekMoE :把 FFN 的结构改成 DeepseekMoE,是对传统 MoE 结构的改进。
- 多头潜在注意力(MLA):利用低秩键值联合压缩,来降低推理时的KV缓存开销。
- 多Token预测(MTP):预测多步依赖,加速推理生成。
- 无辅助损失的负载均衡策略 :引入专家级均衡损失,设备级平衡损失,通信平衡损失,避免负载均衡带来的辅助损失。
1.6 DeepSeek V3
整体思路: 基于DeepSeek-V2,引入新的架构和训练策略,进一步提升模型的性能,同时降低训练成本。在模型架构、训练方法、知识蒸馏与能力提升、模型性能与成本等方面进行创新。
关键技术:
- 无辅助损失的负载均衡策略 (ALFLB): 通过引入偏置项动态调整专家负载。
- Token预测 训练目标(MTP): 在每个位置预测多个未来的 token,提高模型的数据效率。
- 高效的训练框架:FP8 混合精度训练框架,通过 DualPipe 算法和优化的通信内核,实现了近乎零开销的跨节点通信。
- 知识蒸馏 :从 DeepSeek - R1 系列模型中蒸馏推理能力,将其融入 DeepSeek - V3,提升了模型的推理性能。
1.7 DeepSeek R1
定位:强化学习驱动的推理模型,颠覆传统训练流程。
关键技术:
- 零监督微调(Zero-SFT):完全依赖强化学习(RL),成本降至OpenAI O1的3%-5%18。
- 组相对策略优化(GRPO):替代PPO算法,无需价值模型,降低计算开销89。
- 双重奖励系统:结合准确性奖励与格式奖励,提升结构化输出能力8。
2. DeepSeek 的技术基础
2.1 专家混合架构(Mixture of Experts, MoE)
-
任务分解与专家分工:MoE将复杂问题分解为多个子任务,由不同的“专家”网络负责处理。每个专家网络是针对特定领域或任务训练的小型神经网络,例如语法理解、事实知识推理或创造性文本生成等。
-
稀疏激活:与传统的神经网络需要对每个输入激活所有参数不同,MoE架构仅激活与当前任务相关的专家。这种选择性激活大幅降低了计算成本,同时提升了模型的效率。例如,尽管DeepSeek-V3拥有6710亿个参数,但在任何给定任务中仅激活约370亿个参数,这显著提高了计算效率。
-
动态路由与负载均衡:通过“专家选择”(Expert Choice)路由算法,DeepSeek确保了任务在各个专家之间的负载均衡,避免了某些专家的过载或闲置。这一机制提高了模型的可扩展性和资源利用率。
这种架构使得DeepSeek能够在资源有限的条件下实现大规模模型的高效运行,同时保持极高的性能和灵活性。
2.2 强化学习与奖励工程
-
强化学习:通过试错机制和环境反馈,DeepSeek的模型能够不断优化其决策能力,特别是在推理和复杂问题解决方面。强化学习的引入使得DeepSeek能够提升模型的推理能力,尤其是在处理需要深度思考和逻辑推理的任务时。
-
规则驱动的奖励系统:与传统神经奖励模型不同,DeepSeek开发了一种基于规则的奖励系统,用于引导模型的学习。这种方法通过明确的规则对模型进行优化,从而提升了训练效率,特别是在逻辑推理任务中的表现。
通过强化学习和规则驱动的奖励系统,DeepSeek能够在多样化的任务中持续提升模型的智能化水平。
2.3 知识蒸馏与模型压缩
-
知识蒸馏:DeepSeek利用知识蒸馏技术,将大型模型(通常参数庞大、计算需求高)中的能力提取并转移到小规模的模型中。尽管这些压缩后的模型参数远小于原模型,但它们依然能够执行复杂任务。例如,DeepSeek的一些模型仅包含15亿参数,但能够执行与大规模模型相同的任务。
-
模型压缩:通过模型压缩,DeepSeek能够减少计算需求和内存占用,从而使得模型在硬件资源有限的环境下也能够高效运行。尤其是在移动设备或边缘计算场景中,模型压缩能够保证高效的性能和较低的硬件依赖。
通过知识蒸馏和模型压缩,DeepSeek在保证模型性能的同时,显著降低了计算成本和硬件需求。
3. DeepSeek 的创新技术
3.1 架构创新
3.1.1 GQA
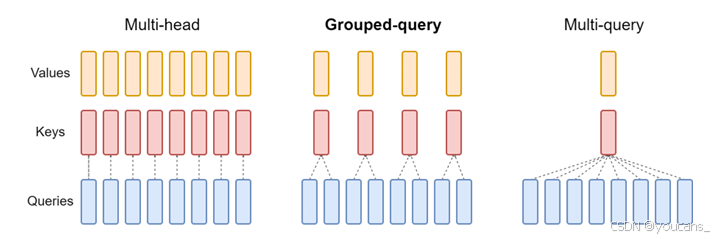
标准多头注意层(MHA)由H个查询头、键头和值头组成。对于每个查询头,都有一个对应的键。而GQA将查询头分成G组,每组共享一个键和值。
GQA是最佳性能(MQA)和最佳模型质量(MHA)之间的一个很好的权衡。使用GQA,可以获得与MHA几乎相同的模型质量,同时将处理时间提高3倍,达到MQA的性能。
参考文献:GQA:Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints (https://arxiv.org/pdf/2305.13245)
3.1.2 MoE 细粒度分割
在典型的MoE架构的基础上,将每个专家 FFN 分割成 m m m 个更小的专家,通过将 FFN 的中间隐藏维度减少到其原始大小的 1 m \frac{1}{m} m1 。由于每个专家变小,因此我们也相应地将激活专家的数量增加 m m m 倍,以保持相同的计算成本,
细粒度的专家分割使得激活专家的组合更具灵活性和适应性,提升了获得更精确和有针对性知识获取的潜力。
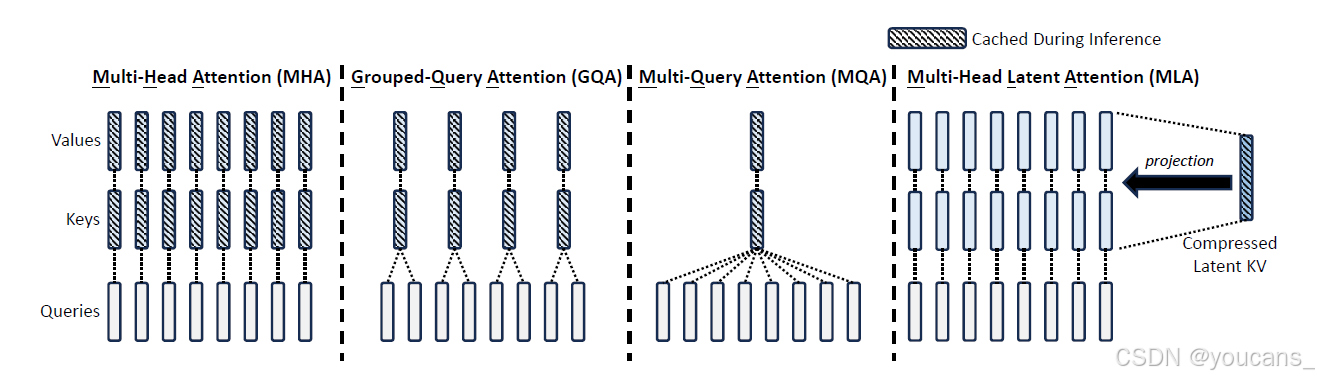
3.1.3 MLA注意力
多头注意力(MHA)在生成过程中,繁重的键值(KV)缓存将成为限制推理效率的瓶颈。多查询注意力(MQA)和分组查询注意力(GQA)所需的 KV 缓存较小,但性能也较差。
多头潜在注意力(MLA)的核心是对键和值进行低秩联合压缩,其性能优于MHA,但需要的KV缓存量要少得多。
3.2 训练优化
3.2.1 多步学习率调度
采用多步学习率调度器代替典型的余弦调度器,提升训练效率。
与传统的单一学习率策略相比,多步学习率调度器能够根据训练的不同阶段动态调整学习率。在训练初期,较高的学习率有助于模型快速收敛;而在训练后期,逐渐降低学习率可以使模型更精细地调整参数,避免过拟合,从而提升模型的最终性能。
这种灵活的学习率调整策略使得 DeepSeek LLM 在大规模数据训练中能够更高效地利用计算资源,缩短训练时间,同时保证模型的稳定性和准确性。
3.2.2 GRPO算法
传统的强化学习方法通常依赖于一个额外的评论模型,不仅增加了计算的开销,也降低了训练效率。
群体相对策略优化(Group Relative Policy Optimization, GRPO)采用分组内相互比较的方式来估计相对奖励,显著提升了强化学习的效率。
GRPO 不依赖于评论模型,而是通过群体样本来估算奖励,并根据这些样本来优化策略。GRPO 的关键创新在于,利用从旧策略生成的输出样本来进行奖励估算,并通过这些样本对策略进行优化,避免了评论模型带来的计算开销。
3.2.3 无辅助损失的负载均衡策略
对于MoE模型,不平衡的专家负载将导致路由崩溃,降低计算效率。传统的解决方案依赖于辅助损耗来避免不平衡负载,损害了模型性能。
为了在负载平衡和模型性能之间实现更好的权衡,提出一种无辅助损耗的负载平衡策略(ALFLB)。通过引入偏置项动态调整专家负载,模型在训练过程中保持了良好的负载均衡,同时提升了整体性能。
3.3 成本控制
KV缓存压缩
RL跳过SFT
算力优化策略
版权声明:
本文写作中得到 DeepSeek-R1 的帮助。
youcans@xidian 作品,转载必须标注原文链接:
【DeepSeek论文精读】7. DeepSeek 的发展历程与关键技术
Copyright 2024 youcans, XIDIAN
Crated:2025-02



















 7071
7071

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











