







需求:
我要训练的模型是无人机拍摄下的车,但由于标注工作量太大,所以先在网上找有没有现成的标注好的数据集试试看能不能训练出我想要的模型
步骤:
访问官方文档:Home - Ultralytics YOLOv8 Docs
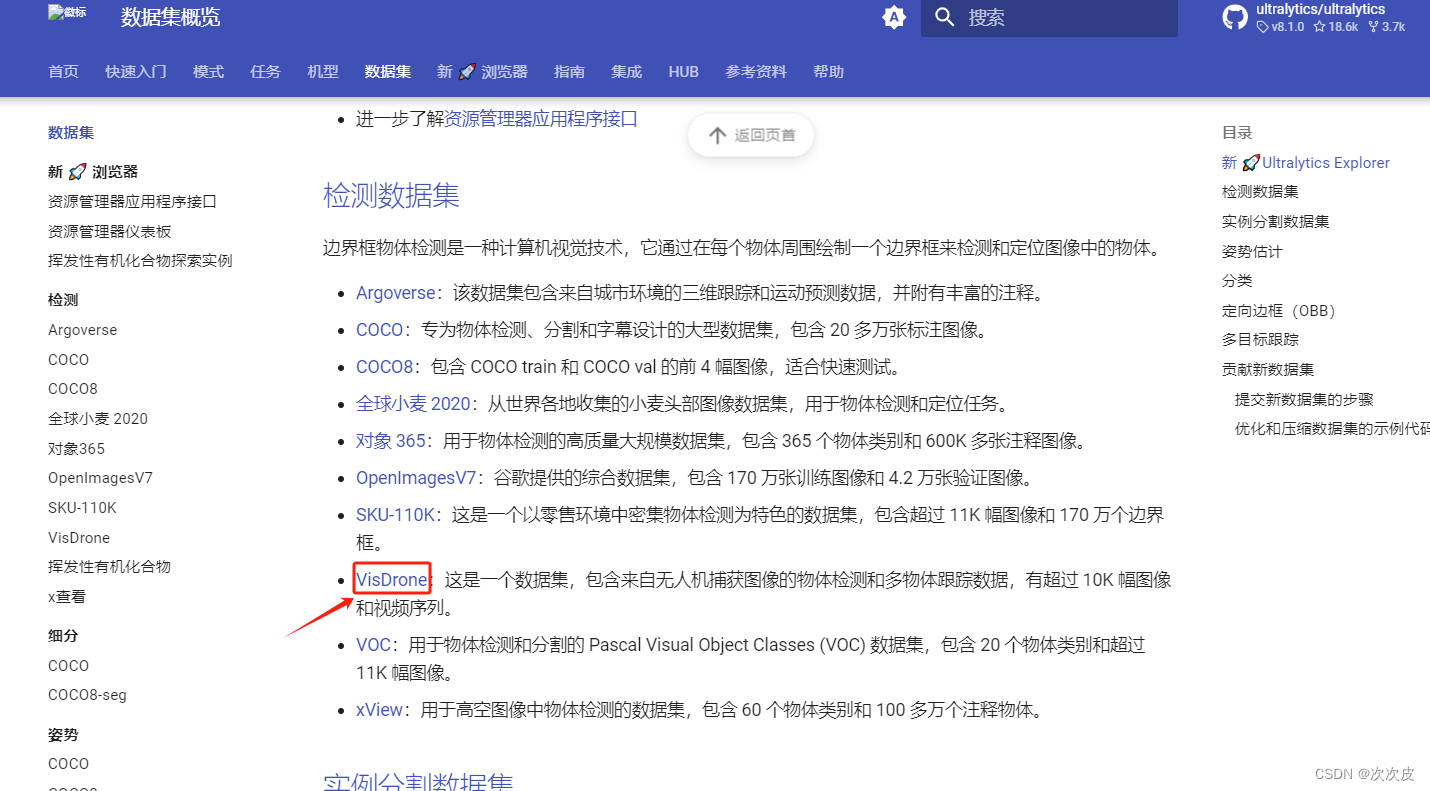
找到数据集的下载地址:
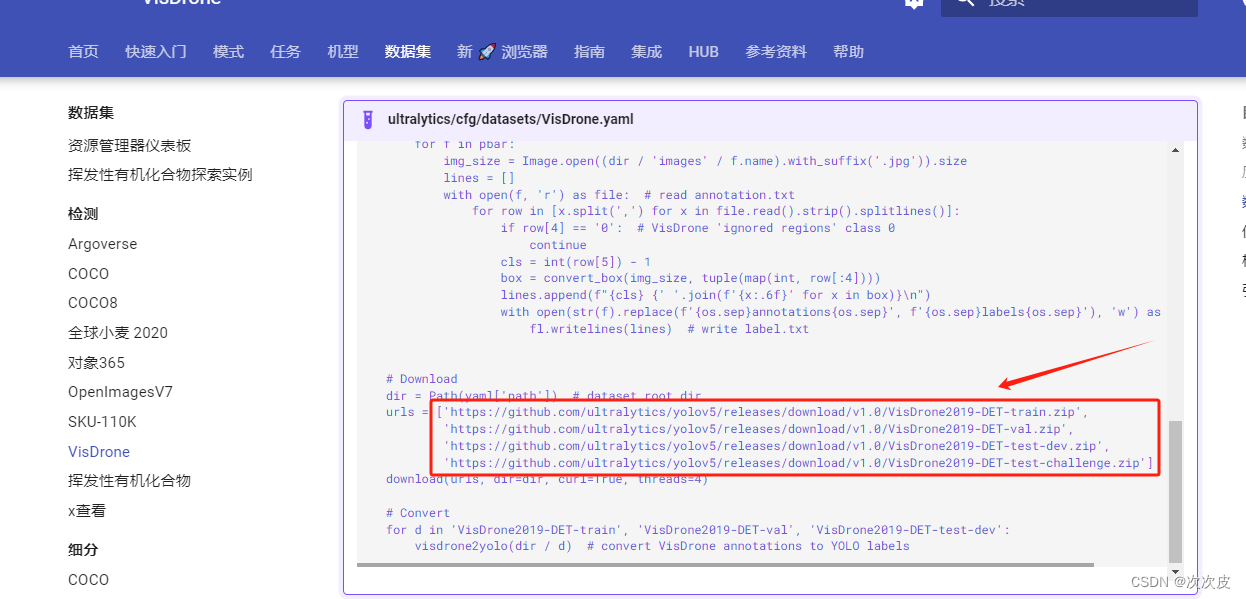
这边只下载其中一个,下载后解压:
![]()
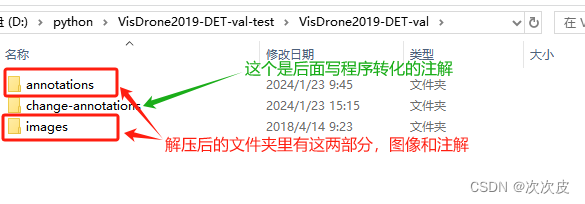
观察注解文件,发现类别文件里面缺失数据(具体有什么类别下面介绍注解每列含义的时候有写),补上:

类别不能少写了,因为标注文件里的类别列是有所有类别的,写少的话训练模型的时候会出现数组越界的报错
随便打开一个注解文件,发现里面的数据是八列,跟我们训练需要的yolo五列数据的格式不一样

找到githua中无人机下载里的readme里面有八列数据详细的解释:
GitHub - VisDrone/VisDrone2018-DET-toolkit: Object Detection in Images toolkit for VisDrone2019
<bbox_left>,<bbox_top>,<bbox_width>,<bbox_height>,<score>,<object_category>,<truncation>,<occlusion>
Name Description
-------------------------------------------------------------------------------------------------------------------------------
<bbox_left> The x coordinate of the top-left corner of the predicted bounding box
<bbox_top> The y coordinate of the top-left corner of the predicted object bounding box
<bbox_width> The width in pixels of the predicted object bounding box
<bbox_height> The height in pixels of the predicted object bounding box
<score> The score in the DETECTION file indicates the confidence of the predicted bounding box enclosing
an object instance.
The score in GROUNDTRUTH file is set to 1 or 0. 1 indicates the bounding box is considered in evaluation,
while 0 indicates the bounding box will be ignored.
<object_category> The object category indicates the type of annotated object, (i.e., ignored regions(0), pedestrian(1),
people(2), bicycle(3), car(4), van(5), truck(6), tricycle(7), awning-tricycle(8), bus(9), motor(10),
others(11))
<truncation> The score in the DETECTION result file should be set to the constant -1.
The score in the GROUNDTRUTH file indicates the degree of object parts appears outside a frame
(i.e., no truncation = 0 (truncation ratio 0%), and partial truncation = 1 (truncation ratio 1% ~ 50%)).
<occlusion> The score in the DETECTION file should be set to the constant -1.
The score in the GROUNDTRUTH file indicates the fraction of objects being occluded (i.e., no occlusion = 0
(occlusion ratio 0%), partial occlusion = 1 (occlusion ratio 1% ~ 50%), and heavy occlusion = 2
(occlusion ratio 50% ~ 100%)).以左上是0,0,第一列是框的左上角的x坐标,第二列是框的左上角的y坐标,第三列框的长度,第四列框的高度,第六列是类别,我们需要的就是这五个数据
再看下yolo格式的txt:

每一行有五列,分别表示:类别代号、标注框横向的相对中心坐标x_center、标注框纵向的相对中心坐标y_center、标注框相对宽度w、标注框相对高度h。注意x_center、y_center、w、h为真实像素值除以图片的高和宽之后的值。
我们需要把上面的八列数据转化为需要的五列数据:
转化为yolo格式txt完整代码(三种):
1、以下程序可以直接执行:
changtxt.py
import cv2
import os
basePath = "D:/python/VisDrone2019-DET-val-test/VisDrone2019-DET-val/"
imagePath = basePath + "images/"
annoPath = basePath + "annotations/"
changePath = basePath + "change-annotations/"
files = os.listdir(annoPath)
for file in files:
file_name, file_extension = os.path.splitext(file)
# 读取图片文件
img = cv2.imread(imagePath + file_name + '.jpg')
# 获取图片分辨率
width, height = img.shape[1], img.shape[0]
# 输出图片分辨率
print('图片分辨率为:{}*{}'.format(width, height))
annoFile = annoPath + file
# 打开文本文件
with open(annoFile, 'r') as file:
# 读取文件内容
lines = file.readlines() # list类型
savefile = open(changePath + file_name + '.txt', "w")
for line in lines:
#print(line)
line = line.rstrip('/n') # 去除换行符
items = line.split(',')
label = items[5]
x_center = round((int(items[0]) + int(items[2]) * 0.5) / width, 6)
y_center = round((int(items[1]) + int(items[3]) * 0.5) / height, 6)
w = round(int(items[2]) / width, 6)
h = round(int(items[3]) / height, 6)
savefile.write(label + ' ' + str(x_center) + ' ' + str(y_center) + ' ' + str(w) + ' ' + str(h)+'\n')
#print(label + ' ' + str(x_center) + ' ' + str(y_center) + ' ' + str(w) + '' + str(h))
savefile.close()
#print(lines)
2、以下的写法有同样的功能:
import cv2
import os
from ultralytics import YOLO
model = YOLO("../yolov8n.pt")
basePath = "D:/python/VisDrone2019-DET-val/VisDrone2019-DET-val/"
imagePath = basePath + "images/"
annoPath = basePath + "annotations/"
yoloPath = basePath + "change-annotations1/"
files = os.listdir(imagePath)
images = []
for img_file in files:
if img_file.endswith(".jpg") or img_file.endswith(".png"):
images.append(img_file)
def remark():
for idx, item in enumerate(images):
img = cv2.imread(imagePath + item)
height = img.shape[0]
width = img.shape[1]
file_name, file_extension = os.path.splitext(images[idx])
anno_file = annoPath + file_name + ".txt"
print(item)
yolo_anno_list = []
with open(anno_file, "r") as file:
for line in file:
line = line.strip()
rect_list = line.split(",")
x0 = int(rect_list[0])
y0 = int(rect_list[1])
x1 = int(rect_list[0]) + int(rect_list[2])
y1 = int(rect_list[1]) + int(rect_list[3])
iw = int(rect_list[2])
ih = int(rect_list[3])
yolo_anno_list.append(
rect_list[5] + " "
+ str(round((x0 + x1) / (2 * width), 6)) + " "
+ str(round((y0 + y1) / (2 * height), 6)) + " "
+ str(round(iw / width, 6)) + " "
+ str(round(ih / height, 6)))
with open(yoloPath + file_name + ".txt", 'w') as file:
for yolo_item in yolo_anno_list:
file.write(yolo_item + '\n')
remark()3、也可以看官网的写法,都是可以将下载的八列格式的注解转化为五列的yolo格式注解:

转化好之后就是正常的训练模型的步骤,我之前的博文里有写:
参照这篇:yolo训练自己的模型(附完整代码)















 3443
3443

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









