







https://www.cnblogs.com/jiyou/p/11272650.html
在原论文中,残差路径可以大致分成2种,一种有bottleneck结构,即下图右所示,其中两个1×1 卷积层,用于先降维再升维,主要出于降低计算复杂度的现实考虑,称之为“bottleneck block”,另一种没有bottleneck结构,如下图左所示,称之为“basic block”。basic block由2个3×3卷积层构成
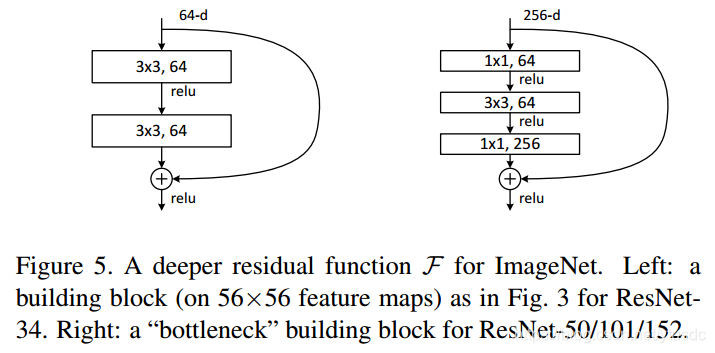
shortcut路径大致也可以分成2种,取决于残差路径是否改变了feature map数量和尺寸,一种是将输入 x 原封不动地输出,另一种则需要经过 1×1 卷积来升维或者降采样,主要作用是将输出与𝐹(𝑥)路径的输出保持shape一致,对网络性能的提升并不明显。
ResNet V1 实现代码:
说明:shortcut 的判断条件
if stride != 1 or in_channel != self.expansion * out_channel首先,shortcut 判断的是 恒等映射分支的featuremap 是否与另一分支输出的featuremap维度是否相同(尺寸和深度)。如果不同,改变恒等映射的分支featuremap维度,使之相同。
in_channel != self.expansion * out_channel 深度上通道不一样,很明显使用1x1 的卷积改变通道。
stride != 1,代码中使用的默认 pad = 1, stripe = 1, 通过卷积公式,
(W + 2*P - k)/s +1 可知,输入输出尺寸不变。当stripe != 1 时,两个分支featuremap尺寸不同,不能直接相加。这里使用1*1 的卷积,相当于在featturemap 上采样了,舍弃了大量信息。一般这种情况很少,最多是通道上的不同。
nn.BatchNorm2d(out_channel) # out_channel为做 BatchNorm2d 卷积的通道数
代码主要分为两个函数:
BasicBlock :这个是基础模块,由两个叠加的3*3卷积组成。 BasicBlock 一般不用做改变通道数,所以一般 expansion = 1,最后的输出通道数就是 out_channel。
Bottleneck:瓶颈模块,有三个卷积层分别是1x1,3x3,1x1,分别用来降低维度,卷积处理,升高维度, Bottleneck 一般用来升高通道维度,所以 out_channel 是分支中进行 1x1 降维(降低计算量)和 3x3卷积的通道数,最后的输出通道数是 expansion x out_channel。
import torch
import torch.nn as nn
# 用于ResNet18和34的残差块,用的是2个3x3的卷积
# 注:最后的输出通道数是 expansion * out_channel
class BasicBlock_V1(nn.Module):
# 通道放大倍数
expansion = 1
def __init__(self, in_channel, out_channel, stride=1):
super(BasicBlock_V1, self).__init__()
# 第一个 3x3 卷积正常传入 stride
self.conv1 = nn.Conv2d(in_channel, out_channel, kernel_size=3,
stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)
self.relu = nn.ReLU(inplace=True)
#第二个3x3卷积的 stride=1, 不改变上一步的featuremap尺寸
self.conv2 = nn.Conv2d(out_channel, self.expansion * out_channel, kernel_size=3,
stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(self.expansion * out_channel)
self.shortcut = None
# 经过处理后的x要与x的维度相同(尺寸和深度)
# 如果不相同,需要添加卷积+BN来变换为同一维度
if stride != 1 or in_channel != self.expansion * out_channel:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channel, self.expansion * out_channel,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion * out_channel)
)
def forward(self, x):
identity = x
# 3x3 cov + BN + relu
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
# 3x3 cov + BN
out = self.conv2(out)
out = self.bn2(out)
# 遇到降尺寸或者升维的时候要保证能够相加
# 需要变换的是恒等映射分支的featuremap
if self.shortcut is not None:
identity = self.shortcut(x)
# add + relu
out += identity
out = self.relu(out)
return out
# 用于ResNet50,101和152的残差块,用的是1x1+3x3+1x1的卷积
class Bottleneck_V1(nn.Module):
# 通道放大倍数
# 前面1x1和3x3卷积的filter个数相等,最后1x1卷积是其expansion倍
expansion = 4
def __init__(self, in_channel, out_channel, stride=1):
super(Bottleneck_V1, self).__init__()
self.conv1 = nn.Conv2d(in_channel, out_channel, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)
self.relu = nn.ReLU(inplace=True) # relu 共用
self.conv2 = nn.Conv2d(out_channel, out_channel, kernel_size=3,
stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
self.conv3 = nn.Conv2d(out_channel, self.expansion * out_channel,
kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(self.expansion * out_channel)
self.shortcut = None
# 经过处理后的x要与x的维度相同(尺寸和深度)
# 如果不相同,需要添加卷积+BN来变换为同一维度
if stride != 1 or in_channel != self.expansion * out_channel:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channel, self.expansion * out_channel,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion * out_channel)
)
# 同basicblock
def forward(self, x):
# 恒等映射分支
identity = x
# 1x1 cov + BN + relu
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
# 3x3 cov + BN + relu
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
# 1x1 cov + BN
out = self.conv3(out)
out = self.bn3(out)
# 遇到降尺寸或者升维的时候要保证能够相加
# 需要变换的是恒等映射分支的featuremap
if self.shortcut is not None:
identity = self.shortcut(x)
# add + relu
out += identity
out = self.relu(out)
return outResNet V2 实现代码:
上面的resnetV1 的代码实现, resnetV2 结构与V1不同,如下图所示
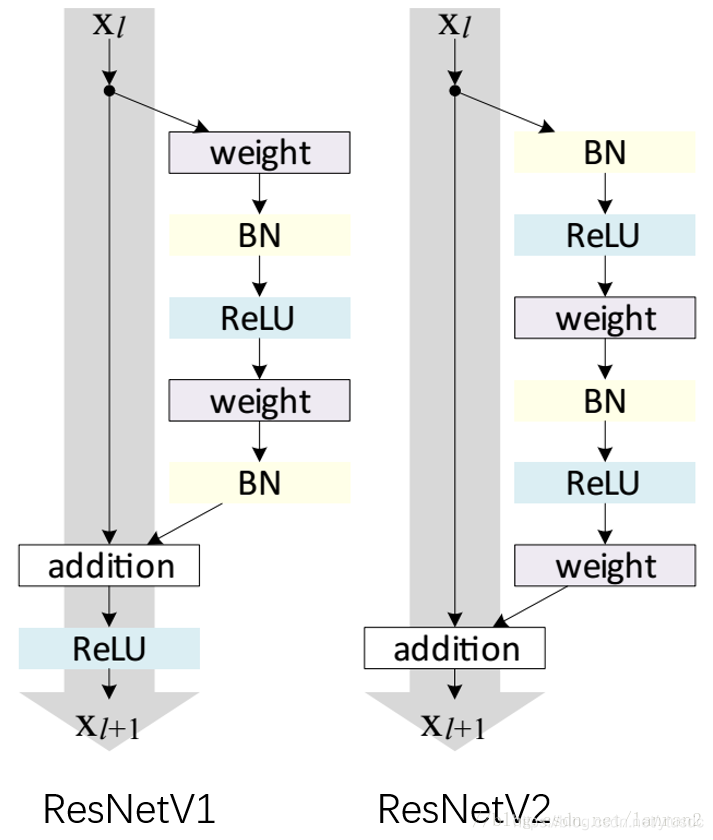
Resnet V2 shotcut 和 Resnet V1 的不太一样,Resnet V2 的shotcut 没有BatchNorm
import torch
import torch.nn as nn
class BasicBlock_V2(nn.Module):
# 通道放大倍数,用不到
expansion = 1
def __init__(self, in_channel, out_channel, stride=1):
super(BasicBlock_V2, self).__init__()
self.bn1 = nn.BatchNorm2d(in_channel)
self.conv1 = nn.Conv2d(in_channel, out_channel, kernel_size=3,
stride=stride, padding=1, bias=False)
self.relu = nn.ReLU(inplace=True)
self.bn2 = nn.BatchNorm2d(out_channel)
self.conv2 = nn.Conv2d(out_channel, out_channel, kernel_size=3,
stride=1, padding=1, bias=False)
self.shortcut = None
if stride != 1 or in_channel != out_channel:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channel, out_channel,
kernel_size=1, stride=stride, bias=False)
)
def forward(self, x):
# 恒等映射分支
identity = x
# BN + relu
out = self.bn1(x)
out = self.relu(out)
# 3x3 conv + BN + relu
out = self.conv1(out)
out = self.bn2(out)
out = self.relu(out)
# 3x3 conv
out = self.conv2(out)
# 判断 恒等
if self.shortcut is not None:
identity = self.shortcut(out)
# add
out += identity
return out
class Bottleneck_V2(nn.Module):
# 通道放大倍数
# 前面1x1和3x3卷积的filter个数相等,最后1x1卷积是其expansion倍
expansion = 4
def __init__(self, in_channel, out_channel, stride=1):
super(Bottleneck_V2, self).__init__()
self.bn0 = nn.BatchNorm2d(in_channel)
self.relu = nn.ReLU(inplace=True)
self.conv1 = nn.Conv2d(in_channel, out_channel, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)
self.conv2 = nn.Conv2d(out_channel, out_channel, kernel_size=3,
stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
# 卷积分支最后的输出通道为 self.expansion*out_channel
self.conv3 = nn.Conv2d(out_channel, self.expansion * out_channel,
kernel_size=1, bias=False)
self.shortcut = None
if stride != 1 or in_channel != self.expansion * out_channel:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channel, self.expansion * out_channel,
kernel_size=1, stride=stride, bias=False)
)
def forward(self, x):
# 恒等映射分支
identity = x
# BN + relu
out = self.bn0(x)
out = self.relu(out)
# 1x1 conv + BN + relu
out = self.conv1(out)
out = self.bn1(out)
out = self.relu(out)
# 3x3 conv + BN + relu
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
# 1x1 conv
out = self.conv3(out)
# 经过处理后的x要与x的维度相同(尺寸和深度)
# 如果不相同,需要添加卷积+BN来变换为同一维度
if self.shortcut is not None:
identity = self.shortcut(out)
# add
out += identity
return out源码:
源码中比较简洁, 其中主要有两个不容
1、是源码中 relu 使用的是F.relu()
# 第一种
import torch.functional as F
out = F.ReLU(input)
# 第二种
import torch.nn as nn
nn.ReLU(inplace=True)
nn.RuLU(input)这两种方法都是使用relu激活,只是使用的场景不一样,F.ReLU()是函数调用,一般使用在foreward函数里。而nn.ReLU()是模块调用,一般在定义网络层的时候使用。
当用print(net)输出时,会有nn.ReLU()层,而F.ReLU()是没有输出的。
nn.ReLU(inplace=True)中inplace的作用: https://www.cnblogs.com/wanghui-garcia/p/10642665.html
2、shortcut()分支的判断处理,比较好,可以学习
resnet V1源码:
import torch
import torch.nn as nn
import torch.nn.functional as F
# 用于ResNet18和34的残差块,用的是2个3x3的卷积
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_planes, planes, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=3,
stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3,
stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.shortcut = nn.Sequential()
# 经过处理后的x要与x的维度相同(尺寸和深度)
# 如果不相同,需要添加卷积+BN来变换为同一维度
if stride != 1 or in_planes != self.expansion*planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion*planes,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion*planes)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x)
out = F.relu(out)
return out
# 用于ResNet50,101和152的残差块,用的是1x1+3x3+1x1的卷积
class Bottleneck(nn.Module):
# 前面1x1和3x3卷积的filter个数相等,最后1x1卷积是其expansion倍
expansion = 4
def __init__(self, in_planes, planes, stride=1):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3,
stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, self.expansion*planes,
kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(self.expansion*planes)
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != self.expansion*planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion*planes,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion*planes)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
out += self.shortcut(x)
out = F.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, num_blocks, num_classes=10):
super(ResNet, self).__init__()
self.in_planes = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=3,
stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1)
self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)
self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)
self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2)
self.linear = nn.Linear(512*block.expansion, num_classes)
def _make_layer(self, block, planes, num_blocks, stride):
strides = [stride] + [1]*(num_blocks-1)
layers = []
for stride in strides:
layers.append(block(self.in_planes, planes, stride))
self.in_planes = planes * block.expansion
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = F.avg_pool2d(out, 4)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
def ResNet18():
return ResNet(BasicBlock, [2,2,2,2])
def ResNet34():
return ResNet(BasicBlock, [3,4,6,3])
def ResNet50():
return ResNet(Bottleneck, [3,4,6,3])
def ResNet101():
return ResNet(Bottleneck, [3,4,23,3])
def ResNet152():
return ResNet(Bottleneck, [3,8,36,3])
def test():
net = ResNet18()
y = net(torch.randn(1,3,32,32))
print(y.size())
# test()
resnet V2 源码
'''Pre-activation ResNet in PyTorch.
Reference:
[1] Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun
Identity Mappings in Deep Residual Networks. arXiv:1603.05027
'''
import torch
import torch.nn as nn
import torch.nn.functional as F
class PreActBlock(nn.Module):
'''Pre-activation version of the BasicBlock.'''
expansion = 1
def __init__(self, in_planes, planes, stride=1):
super(PreActBlock, self).__init__()
self.bn1 = nn.BatchNorm2d(in_planes)
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=3,
stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3,
stride=1, padding=1, bias=False)
if stride != 1 or in_planes != self.expansion*planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion*planes,
kernel_size=1, stride=stride, bias=False)
)
def forward(self, x):
out = F.relu(self.bn1(x))
shortcut = self.shortcut(out) if hasattr(self, 'shortcut') else x
out = self.conv1(out)
out = self.conv2(F.relu(self.bn2(out)))
out += shortcut
return out
class PreActBottleneck(nn.Module):
'''Pre-activation version of the original Bottleneck module.'''
expansion = 4
def __init__(self, in_planes, planes, stride=1):
super(PreActBottleneck, self).__init__()
self.bn1 = nn.BatchNorm2d(in_planes)
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3,
stride=stride, padding=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, self.expansion*planes,
kernel_size=1, bias=False)
if stride != 1 or in_planes != self.expansion*planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion*planes,
kernel_size=1, stride=stride, bias=False)
)
def forward(self, x):
out = F.relu(self.bn1(x))
shortcut = self.shortcut(out) if hasattr(self, 'shortcut') else x
out = self.conv1(out)
out = self.conv2(F.relu(self.bn2(out)))
out = self.conv3(F.relu(self.bn3(out)))
out += shortcut
return out
class PreActResNet(nn.Module):
def __init__(self, block, num_blocks, num_classes=10):
super(PreActResNet, self).__init__()
self.in_planes = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1,
padding=1, bias=False)
self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1)
self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)
self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)
self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2)
self.linear = nn.Linear(512*block.expansion, num_classes)
def _make_layer(self, block, planes, num_blocks, stride):
strides = [stride] + [1]*(num_blocks-1)
layers = []
for stride in strides:
layers.append(block(self.in_planes, planes, stride))
self.in_planes = planes * block.expansion
return nn.Sequential(*layers)
def forward(self, x):
out = self.conv1(x)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = F.avg_pool2d(out, 4)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
def PreActResNet18():
return PreActResNet(PreActBlock, [2,2,2,2])
def PreActResNet34():
return PreActResNet(PreActBlock, [3,4,6,3])
def PreActResNet50():
return PreActResNet(PreActBottleneck, [3,4,6,3])
def PreActResNet101():
return PreActResNet(PreActBottleneck, [3,4,23,3])
def PreActResNet152():
return PreActResNet(PreActBottleneck, [3,8,36,3])
def test():
net = PreActResNet18()
y = net((torch.randn(1,3,32,32)))
print(y.size())
# test()
















 535
535

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









