







DeepReID: Deep Filter Pairing Neural Network for Person Re-Identification
(香港中文大学Wei Li Rui Zhao Tong Xiao XiaogangWang∗)
三个贡献
1.提出了一个filter paring neural network(FPNN)
2.采用了dropout,data augmentation,data balancing,bootstrapping策略训练网络
3.建立了一个大型行人数据库CUHK03,1360个行人,13164张图片 ,同时提供手工裁剪和自动检测的图片
1.网络结构
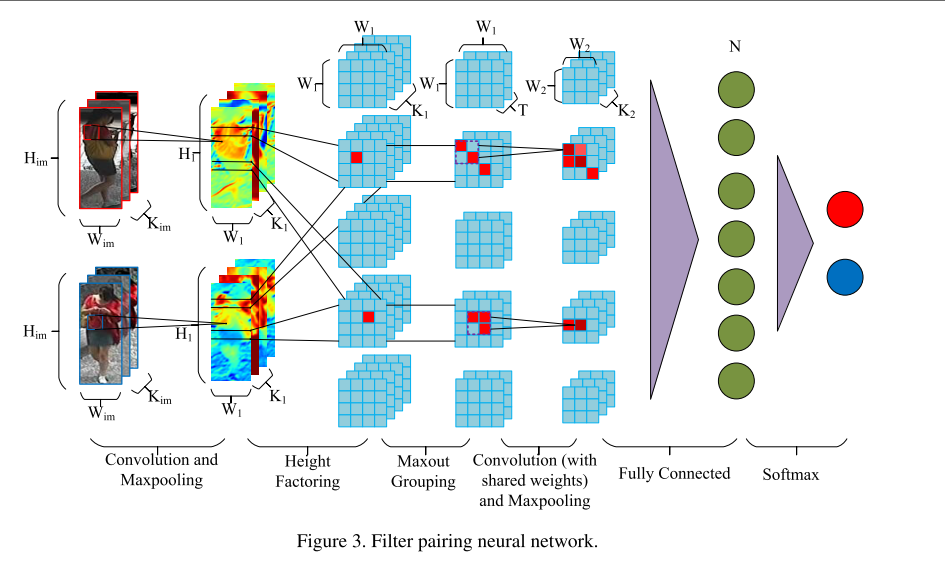
该结构用6层去处理Pre中的misalignment,cross-view photometric and geometric transform,occlusion and background clutter.
特征抽取
用一个卷积层和maxpooling完成特征提取。卷积核对个数K1:64,大小5*5,stride:1,
Him=64
Wim=32
K1=64
m1=5
经过卷积后:H0:60 W0:28
再经过3x3的max pooling H1:20 W1:9
经过卷积层,局部块的响应被抽取成局部特征,每个局部块被表示成K1 channel特征。一对过滤器表示相同的特征。
论文中没有说明,我猜想这一对卷积层应当是共享参数的。
最大池化层作用:使得特征对局部misalignment有鲁棒性。
块匹配层
这部分是论文创新最大的地方。他们团队原来在salience论文中用块匹配进行person reid.这次又把这个思想用到DL中实现,真是膜拜啊。
把一张行人图片水平分割成M(=20)个水平条纹,每个水平条纹有W1(=9)个块。(就是卷积池化后的feature map大小20*9)
块匹配在相同的条纹里面进行 。块匹配层的输出:K1MW1xW1块错位矩阵。
Sk(i,j)(i’,j’)=fkijgki’j’
也就是得到矩阵的值是匹配的两个patch值的乘积。
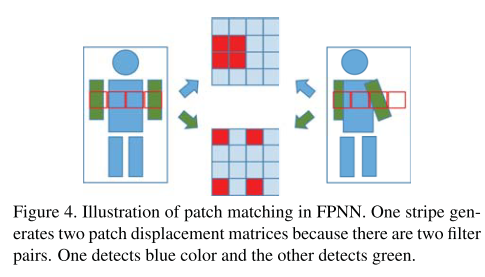
不知道patch match layer是怎样实现的
photometric transform
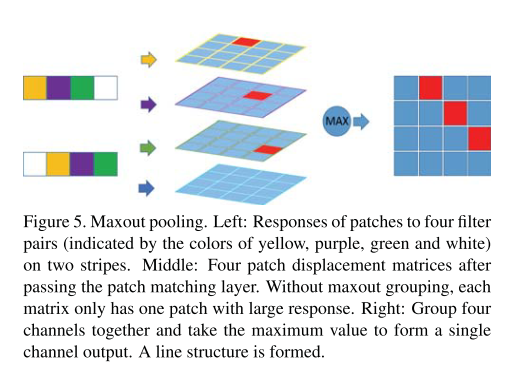
用maxout grouping把K1 个group分成T层。输出是TMW1xW大小的错位矩阵。
Modeling part displacement
卷积和最大池化层:以TMW1xW块错位矩阵为输入,把它看成是T个通道的MW1xW1图像。K2个m2xm2xT过滤器,产生了MW2xW2xK2个feature map.
T:16 m2:3 W2:3 K2:16
Modeling pose and viewpoint transform
卷积和最大池化层的输出被看成是用一个特殊事件特征检测到的部分错位表示。这一层用N个通道的全连接层实现,可以看成是各种局部错位表示的组合。其中,N=128。
Identity Recognition
Softmax layer
总结
根据论文描述,总结网络结构如下表:
| layer | input size | output size | kernel size | output_num | stride | pad |
|---|---|---|---|---|---|---|
| conv1 | 64x32x3 | 60x28x64 | 5x5x3 | 64 | 1 | 0 |
| pool1(max) | 60x28x64 | 20x9x64 | 3x3(pool size) | 3 | ||
| match layer | 20x9x64 | 180x9x64 | ||||
| maxout1 | 180x9x64 | 180x9x16 | ||||
| conv2 | 180x9x16 | 180x9x16 | 3x3x16 | 16 | 1 | 1 |
| pool2(max) | 180x9x16 | 60x3x16 | 3x3(pool size) | 3 | ||
| FC1 | 60x3x16 | 1x1x128 | ||||
| FC2 | 1x1x128 | 1x1x2 | ||||
| softmaxloss |
2.训练策略
Dropout
在第一个卷积池化层后,用dropout,使得训练模型更稳定。
数据增广
在[-0.05Him,0.05Him]x[-0.05Wim,0.05Wim]采样5张相同大小的图片。
数据平衡
开始训练的时候选取所有的正样本和相同数目的负样本,在初始训练后将会得到一个好的配置。随着训练过程不断继续,逐渐增大每个mini-batch中的负样本,直到达到5:1.
Booststrapping
所谓的Bootstrapping法就是利用有限的样本资料经由多次重复抽样,重新建立起足以代表母体样本分布之新样本。
网络稳定后,我们继续选择困难的负样本进行训练。困难负样本指被当前网络以高概率预测成匹配对的负样本。在每一个epoch后对所有的负样本都进行一次再预测是很费时的,我们只再预测在前一个epoch后的hard samples。因为这些样本能被用于更新网络,所有这些样本的预测值在网络更新后期待更大的改变。
每个负样本x有一个分数sk(第k个epoch后的分数),拥有最小分数的样本被选中用于网络的再训练。
初始:
s0=1−P(x is a matched pair|ϕ0)
如果这个样本被选中,分数更新:
sk=1−p(x is a matched pair|ϕk)+sk−12
如没有选中,分数更新:
sk=λsk−1
CUHK3数据库
1.除了提供手工裁剪的行人图像,也提供了检测算法自动检测到的图像。这提供了更现实的场景,能发现现存数据库中很难发现的问题。错位排列、遮挡和身体的部分缺失在数据库中很常见。不精确的检测使得几何转换更复杂。另外,还提供了图像的原始帧。
2.取自多个交叉视角对。并且摄像机是在一个开放环境,行人可以在任意方向走动。
3.图像取自几个月的视频序列。因此,即使一个摄像机,由季节、太阳方向、影子分布也会引起光照变化。而且摄像机设置都不相同,也会引起光学转换。
实验
在CUHK03上进行实验,取得了较好的效果。在较小的数据库CUHK01上实验,该数据库一共971人,每人两张图片。100个人被用于测试,其他871人被用于训练和验证,实验效果并不优于KISSME 。
这个方法适合大数据库,对小数据集并不十分有效















 718
718

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









