







 本文介绍了一种创新方法,通过RGB图像处理消除衣物特征影响,提出CCVID换衣视频数据集,并设计Clothes-Agnostic模型。模型包含身份和衣物分类器,使用衣物标签减少标注复杂性。文章重点讲解了衣物无关特征学习和针对换衣/不换衣场景的优化策略,以及Curriculum Learning的训练策略。
本文介绍了一种创新方法,通过RGB图像处理消除衣物特征影响,提出CCVID换衣视频数据集,并设计Clothes-Agnostic模型。模型包含身份和衣物分类器,使用衣物标签减少标注复杂性。文章重点讲解了衣物无关特征学习和针对换衣/不换衣场景的优化策略,以及Curriculum Learning的训练策略。
论文阅读: Clothes-Changing Person Re-identification with RGB Modality Only
-
这篇文章提出了很巧妙的思想从RGB图像中去除衣服特征的影响,同时兼顾了换衣和不换衣的情况;同时提出从一个步态数据集中通过检测获得一个视频换衣数据集 CCVID。
-
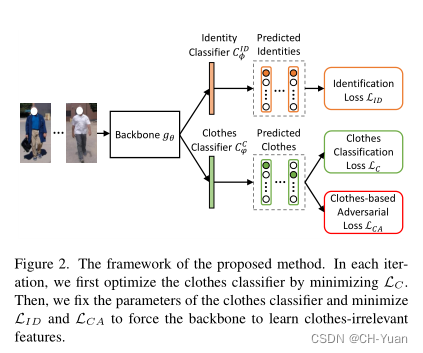
整体框架图
-
模型包括身份分类器和衣服分类器:身份分类器就是传统的利用身份标签进行分类,衣服分类是根据衣服标签进行分类。
-
衣服类别的标注是采用了一种简单的策略,通过人工进行标注的。对同一身份的图像穿不同衣服的分成不同类别,这样不同身份的行人即便穿相同衣服也会被分为不同类,但是减少了标注的困难。
-
衣服分类器训练
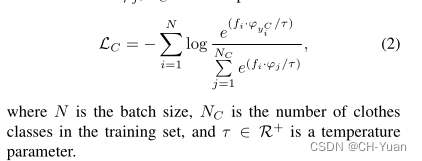
-
训练好衣服分类器后,固定参数,让 L I D L_{ID} LID和 L C A L_{CA} LCA( Clothes-based Adversarial Loss)联合训练学习衣服无关特征。
-
L I D L_{ID} LID没啥说的,来看下 L C A L_{CA} LCA

这其实就是一个细粒度多类别的身份分类器(文中称为multi-positive-class classification loss),若图像属于同一身份的衣服类,则概率为1/K,K为该身份行人的衣服类别数。而不属于该身份的衣服类,在概率为0。——这样就使得模型不去区分一个人穿什么衣服,而只关注身份本身。 -
但是,这样带来的问题是:会对换衣情况下的身份识别有帮助,但是对不换衣情况下会降低效率。为此,对该公式进行调整,增大同一身份相同衣服的概率,这样就使得模型在关注身份的同时,会去关注部分衣服特征。
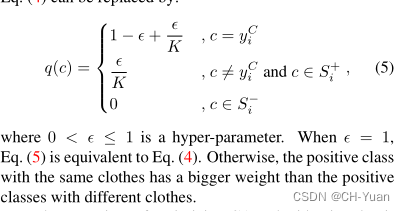
-
最后,就是联合优化。训练时,直接让两个函数同时优化,会使模型难以收敛,于是采用Curriculum Learning(课程式学习,由易到难)的优化方式。先用身份损失 L I D L_{ID} LID去训练模型, 这样模型就具有基本的识别能力;在第一次学习率下降时,增加 L C A L_{CA} LCA参与训练。
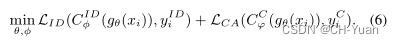

















 237
237

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









