






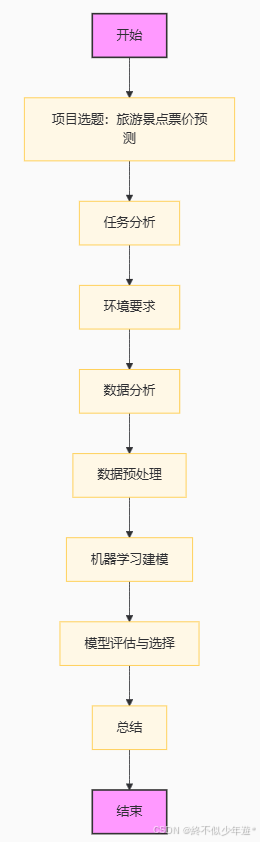
1.项目选题:旅游景点票价预测(回归任务)
数据来源:美国开源数据集汇总网站
2.任务分析
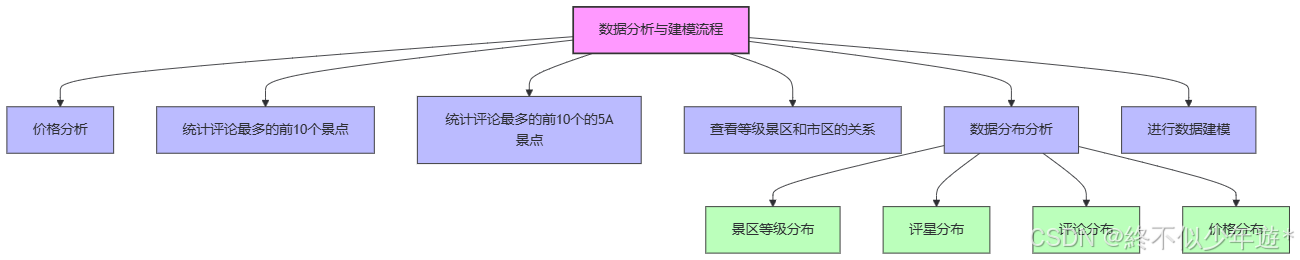
价格分析
统计评论最多的前10个景点
统计评论最多的前10个的5A景点
查看等级景区和市区的关系
数据分布分析
景区等级分布
评星分布
评论分布
价格分布
进行数据建模
3.环境要求
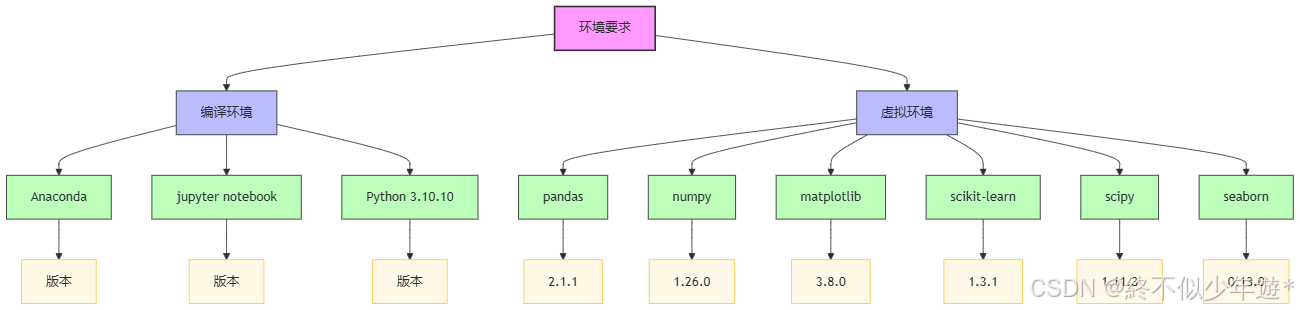
3.1编译环境
Anaconda + jupyter notebook
python3.10.10
3.2虚拟环境
pandas == 2.1.1
numpy == 1.26.0
matplotlib == 3.8.0
scikit-learn == 1.3.1
scipy == 1.11.3
seaborn == 0.13.0
4.数据分析及信息挖掘

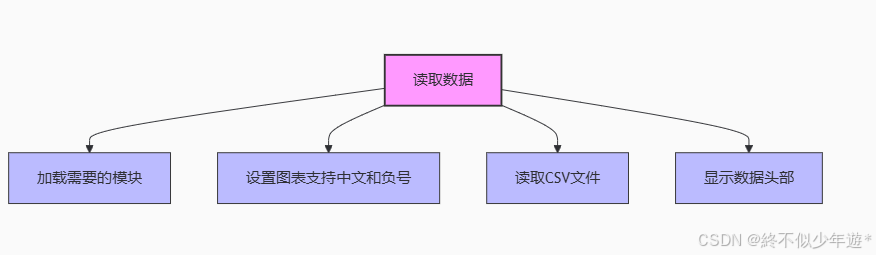
4.1数据分析-读取数据
在读取数据阶段,我们确认了数据的完整性和准确性,为后续分析打下基础。
高价值信息提炼:确保数据质量是预测模型成功的关键。
# To support both python 2 and python 3
from __future__ import division, print_function, unicode_literals
# 加载需要的模块
import numpy as np
import pandas as pd
import os
# to make this notebook's output stable across runs
np.random.seed(42)
# To plot pretty figures
%matplotlib inline
#内嵌图片显示
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rc('axes', labelsize=14)
mpl.rc('xtick', labelsize=12)
mpl.rc('ytick', labelsize=12)
# 设置图表支持中文
plt.rcParams['font.sans-serif'] = 'SimHei'
# 设置图表支持负号
plt.rcParams['axes.unicode_minus'] = False
# Where to save the figures
PROJECT_ROOT_DIR = "."
CHAPTER_ID = "fundamentals"
# 可能用到的图片保存函数
def save_fig(fig_id, tight_layout=True):
# path = os.path.join(PROJECT_ROOT_DIR, "plt_images", CHAPTER_ID, fig_id + ".png")
path = os.path.join(PROJECT_ROOT_DIR, "plt_images", fig_id + ".png")
print("Saving figure", fig_id)
if tight_layout:
plt.tight_layout()
plt.savefig(path, format='png', dpi=300)
# Ignore useless warnings (see SciPy issue #5998)
import warnings
warnings.filterwarnings(action="ignore", message="^internal gelsd")
# 读取数据
df = pd.read_csv('./data.csv')
df.head(5)
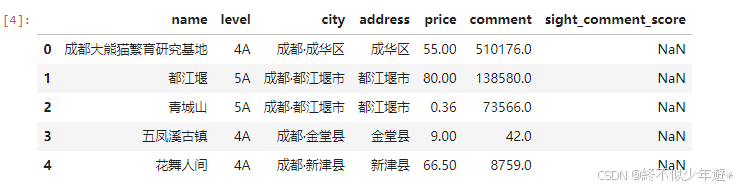
4.2数据分析-探索数据
通过探索性数据分析(EDA),我们了解了数据的分布特征,包括景区等级、评星、评论数和价格。
高价值信息提炼:发现景区等级与价格、评论数之间的潜在关系,为特征选择提供依据。
# 初步了解数据
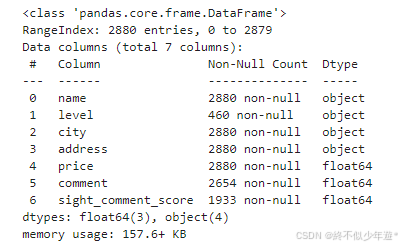
df.info()
df.info():Pandas库中的函数,显示DataFrame的概要信息,包括列名(Column)、非空值数量(Non-Null)、数据类型(Dtype)等。
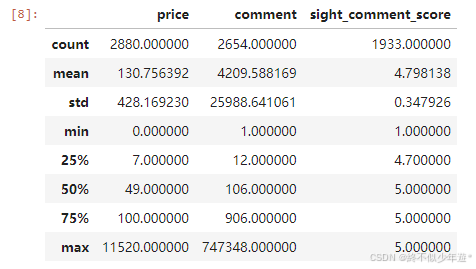
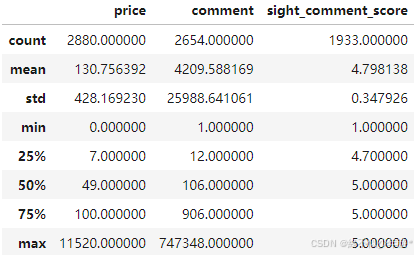
df.describe()
df.describe():Pandas库中的函数,提供DataFrame中数值型列的统计信息,包括计数、平均值、标准差、最小值、25%分位数、中位数、75%分位数和最大值。对于非数值型数据,这个函数不会显示任何信息。
4.2.1将一些字符型数据转换成整形
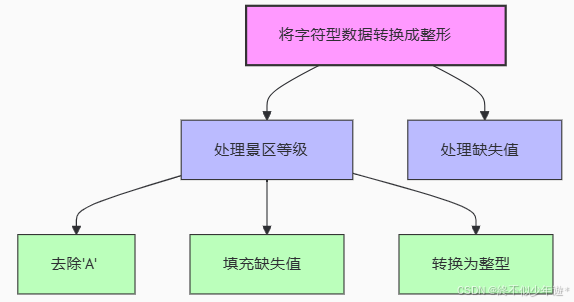
# 通过head和describe观察,发现level可以转换成数字
df.head(5)
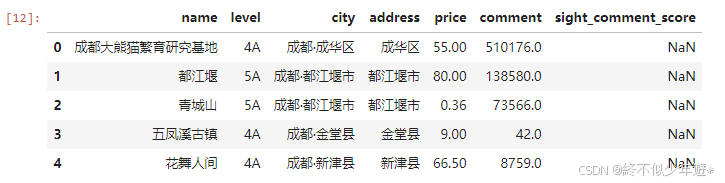
发现景区的‘level’特征可以转换成整形,方便应用与机器学习分析
# 查等级都有哪些,是否可以转换成数字
df['level'].value_counts()
df['列名'].value_counts():是Pandas库中的一个函数,用于统计DataFrame中某列(即Series)中每个唯一值出现的次数,并返回一个Series。这个Series的索引是唯一值,值是对应的计数。

# 判断level是否有缺失值 缺失值个人理解为未到达评级标准,那就用0填充
df['level'].isnull().sum()
.isnull():返回一个与原DataFrame同形状的布尔型DataFrame,其中元素为True表示原位置的值是缺失值,False表示非缺失值。
.sum():在布尔型DataFrame上使用时,True被当作1,False被当作0,因此sum()函数计算的是True值的总数,即缺失值的总数。
![]()
# 处理字符串,将A去掉,并将缺失值填充为0,整体转为格式为int
df['level'] = df['level'].str.replace('A','').fillna(0).astype(int)
df.head(5)
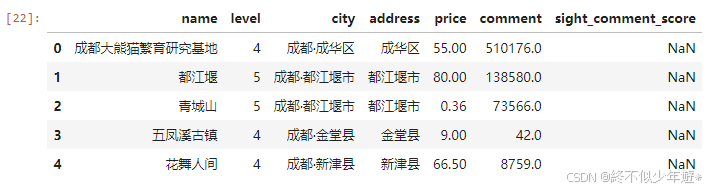
4.2.2查看一些最值
根据下图(上面通过describe函数得出)的数值查找
# 查看最高价格门票的景区
df[df['price']==11520]
df[df['列名'] == 整形数值] 是Pandas库中用于基于条件筛选数据的索引方式。
‘df['price']==11520’这里返回一个布尔值,为True时才会返回结果

# 获取评论数最多的景区
df[df['comment']==747348]

4.2.3查看景区等级分布
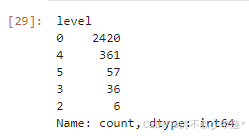
# 查看景区等级分布
df['level'].value_counts()
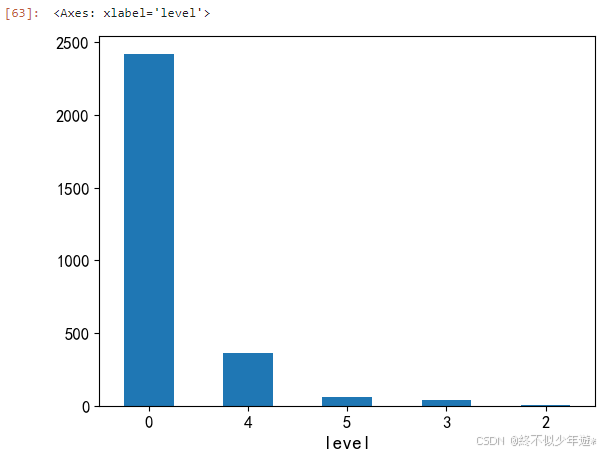
做可视化
df['level'].value_counts().plt(kind='bar',rot=0)
# 设置x轴的标签
plt.xlabel('景点级别')
# 设置y轴的标签
plt.ylabel('景点数量')
# 显示图标
plt.show()
从图中可以看出,不同等级的景区分布不均,可能与城市的旅游资源和开发程度有关。

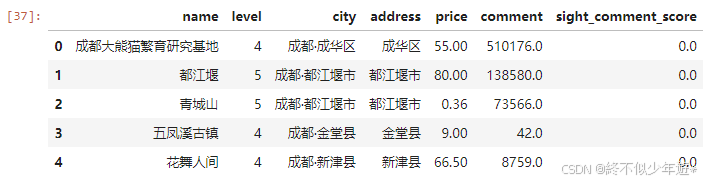
# 查看景区评星分布 缺失值用0填充
df['sight_comment_score'] = df['sight_comment_score'].fillna(0)
df.head(5)
导入seaborn辅助可视化效果增强
import seaborn as sns
# 查看景区评价数据的分布
sns.displot(df['sight_comment_score'],kde=True)
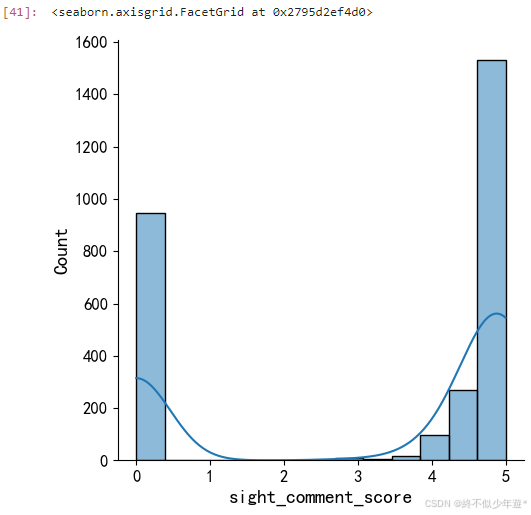
从图中可以看出评星等级为0、3.5-5居多
# 查看价格分布
df['price'].value_counts()
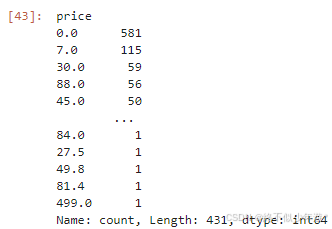
0是免门票景点
# 这里是不是用折线图好一点?
df['price'].hist(bins=20)
# 设置X轴标签
plt.xlabel('票价')
# 设置Y轴标签
plt.ylabel('频数')
# 显示图表
plt.show()
价格分布图显示了票价的多样性,免门票景点的存在可能吸引更多游客,但也可能影响景区的经济效益。
df['price'].sort_values(ascending=False).head(50)
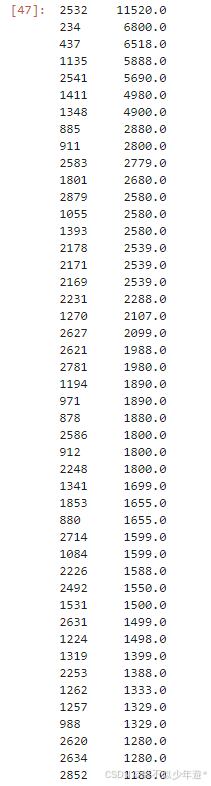
左边是景点编号
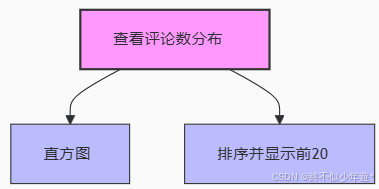
# 查看评论数分布
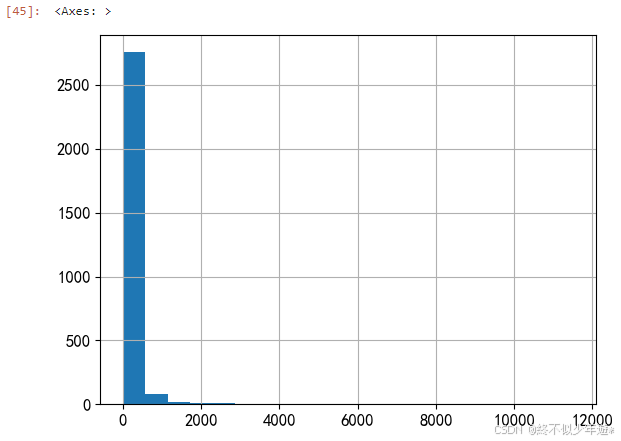
df['comment'].hist(bins=[0,100,1000,2000,5000,10000,20000,50000,100000,700000])
# 设置X轴标签
plt.xlabel('评论数')
# 设置Y轴标签
plt.ylabel('频数')
# 显示图表
plt.show()
评论数的分布可能揭示了游客对不同景区的关注度和满意度,高评论数的景区可能在市场营销和游客服务上做得更好。
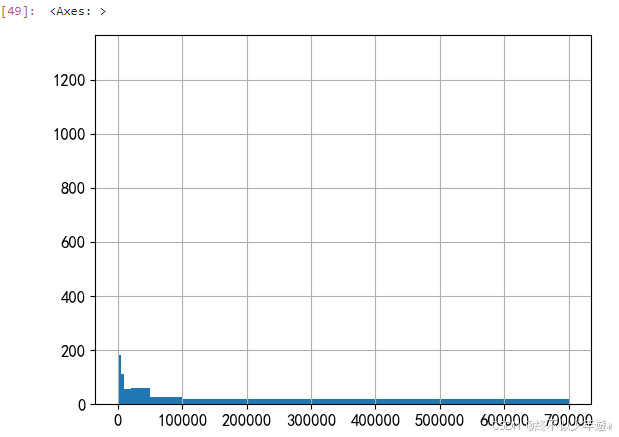
df['comment'].sort_values(ascending=False).head(20)
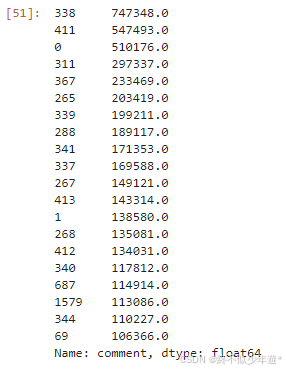
可以看到评论最多的景点高达70w条
4.3获取评论最多的前10个景点
识别出评论最多的景点,这些景点可能具有较高的人气和影响力。
高价值信息提炼:高评论数可能与高人气和良好的游客体验相关联,当然,符合这些特征的景区也可能在地理环境、气候、经济和人文等方面具有独到的韵味吸引游客前来观光。
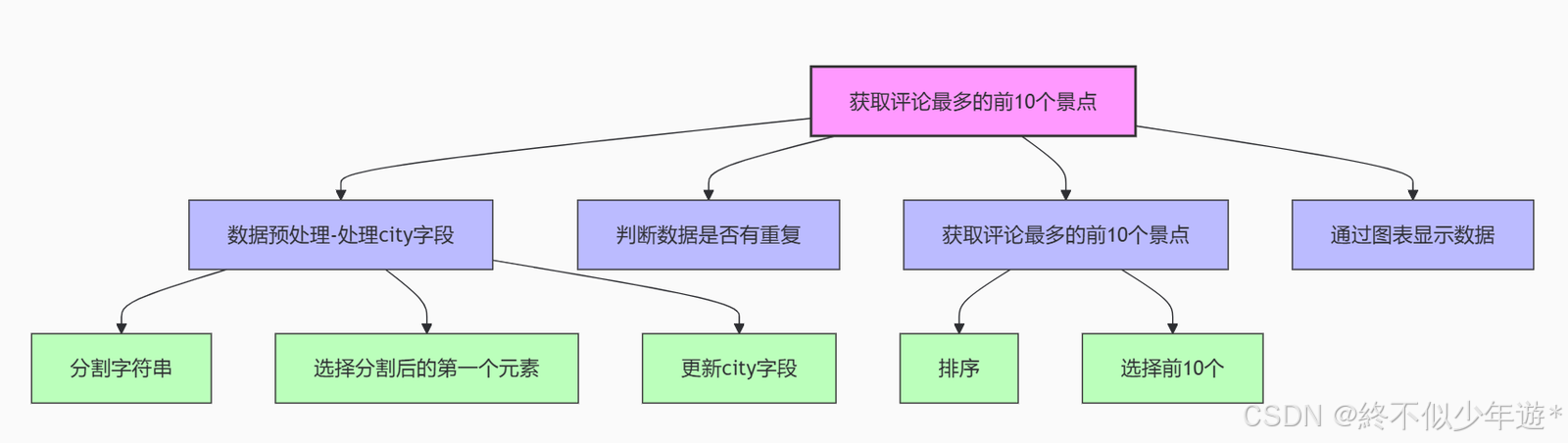
# 数据预处理-处理city字段
df['city'] = df['city'].apply(lambda x:x.split('·')[0])
1.apply函数:apply函数是Pandas中非常强大的一个函数,可以对DataFrame的某一列(或行)应用一个函数。
2.lambda函数:lambda是一个匿名函数,允许定义一个简短的函数。在这里,lambda x: x.split('·')[0]定义了一个函数,它接受一个参数x,然后使用split方法根据'·'(点)字符分割字符串,最后返回分割后的第一个元素。
3.分割字符串:x.split('·')将city字段中的字符串按照'·'字符分割成一个列表。例如,如果city字段的值是'北京·中国',那么split方法会将其分割成列表['北京', '中国']。
4.选择分割后的第一个元素:[0]表示选择分割后列表的第一个元素。在这个例子中,如果city字段的值是'北京·中国',那么x.split('·')[0]的结果就是'北京'。
5.更新city字段:通过df['city'] = ...,将处理后的结果重新赋值给city字段,从而更新整个city列。
# 判断数据是否有重复
df2 = df[~df.duplicated(subset=['name','city'])]
1.duplicated函数:duplicated函数用于识别DataFrame中的重复行。默认情况下,它会检查所有列,但可以通过subset参数指定特定的列。
2.参数subset=['name','city']:这里指定了duplicated函数只检查name和city这两列。如果这两列的组合在不同的行中完全相同,则认为这些行是重复的。
3.逻辑否定~:~是Python中的逻辑非操作符。在这里,~df.duplicated(subset=['name','city'])会返回一个布尔Series,其中重复的行标记为False,非重复的行标记为True。
4.创建新的DataFrame:df[~df.duplicated(subset=['name','city'])]使用上述布尔Series作为索引,选择出所有非重复的行,并将这些行组成一个新的DataFrame df2。
做数据去重
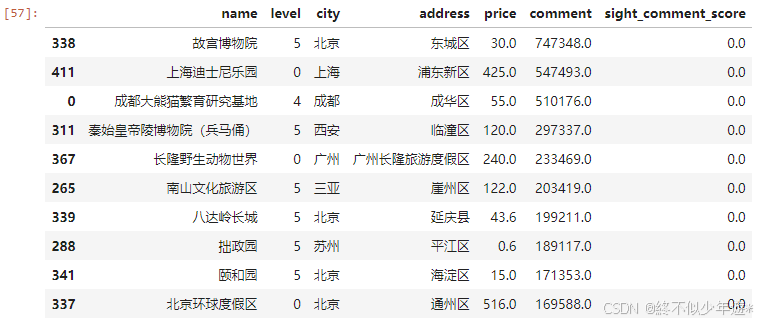
# 获取评论最多的前10个景点
comment_top10 = df2.sort_values(by='comment',ascending=False).head(10)
comment_top10
sort_values(by='comment', ascending=False):这个函数对df2按照comment列的值进行排序。by='comment'指定了排序依据的列,ascending=False表示降序排序,即评论数最多的排在前面。
# 通过图表显示数据
comment_top10.plot(kind='bar',x='name',y='comment',rot=90,fontsize=12)
# 设置X轴标签
plt.xlabel('景点名称')
# 设置Y轴标签
plt.ylabel('评论数')
# 显示图表
plt.show()
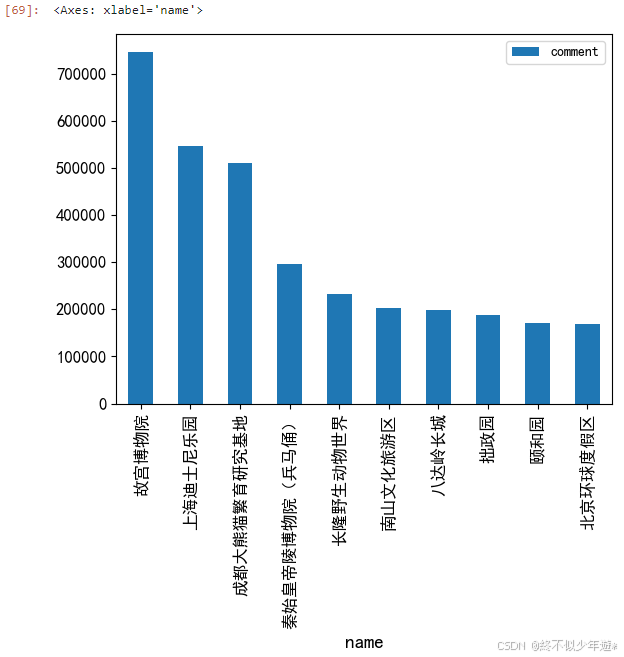
评论最多的前10个景点如图所示
4.4获取评论最多的前10个5A景点
筛选出5A级景区中评论最多的前10个,这些景区在质量和人气上都表现突出。
高价值信息提炼:5A级景区的高评论数可能反映了其卓越的服务和设施。
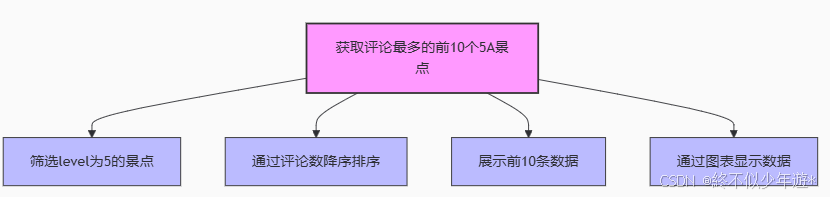
# 筛选level为5的景点,通过评论数来进行降序排序,最后展示前10条数据
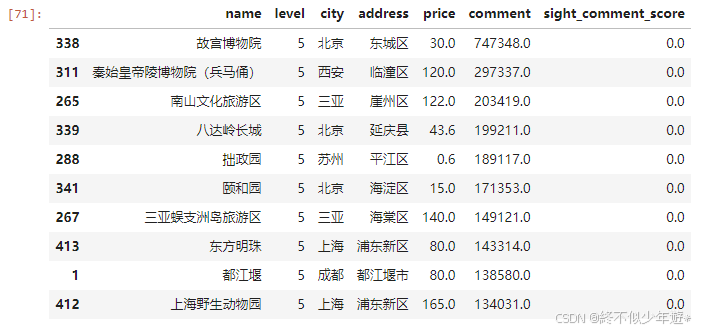
comment_5a_top10 = df2[df2['level']==5].sort_values(by='comment',ascending=False).head(10)
comment_5a_top10
# 通过图表显示数据
comment_5a_top10.plot(kind='bar',x='name',y='comment',rot=90,fontsize=12)
# 设置X轴标签
plt.xlabel('5A级景点名称')
# 设置Y轴标签
plt.ylabel('评论数')
# 显示图表
plt.show()

获取评论最多的前10个5A景点如图所示,可以看出,并非5A的景区就人气最高
4.5查看景区等级和市区的关系
分析景区等级与所在城市的关系,探索城市对景区等级的影响。
高价值信息提炼:城市的发展水平和旅游资源的丰富程度可能影响景区的等级评定。
# 获取每个城市对应等级景区的数量
lc_df = df.groupby(['city','level']).size()
# 转换数据格式
lc_df = lc_df.unstack().fillna(0)
lc_df
1.groupby(['city','level']):这个函数将DataFrame df按照city(城市)和level(等级)列的组合进行分组。每个唯一的city和level组合被视为一个分组。
2.size():这个函数计算每个分组的大小,即每个分组中的行数。在这里,它计算每个城市中每个等级景区的数量。
3.unstack():这个函数将groupby对象的多级索引(MultiIndex)转换为DataFrame的列。代码中,unstack()将level索引级别“展开”为DataFrame的列,每个等级成为一个列,城市名称成为行索引。
4.fillna(0):这个函数用于填充DataFrame中的缺失值。由于某些城市可能没有某个等级的景区,这会导致在展开后的DataFrame中出现缺失值(NaN)。fillna(0)将这些缺失值替换为0,表示该城市在该等级没有景区。
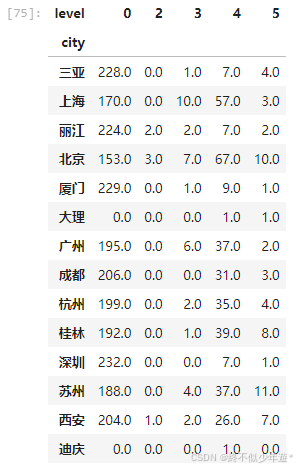
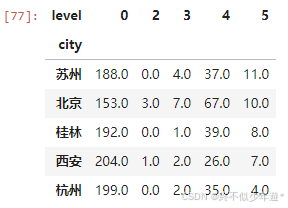
# 进行数据排序 排序规则是什么?
lc_sort_df = lc_df.sort_values(by=[5,4],ascending=False)
lc_sort_df.head(5)
# 通过图表显示数据
lc_sort_df.head(5).plot(kind='bar',rot=0,fontsize=12)

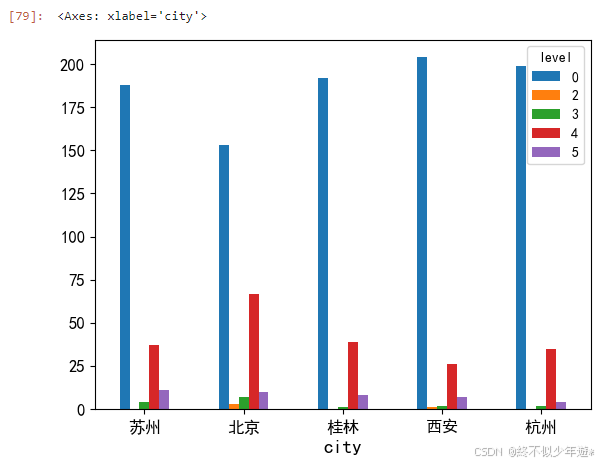
城市经济和基础设施对景区等级有显著影响,城市旅游资源丰富地区更可能拥有高等级景区。比如上述通过排序后得出的评级景区数量资源前5的城市,可以看到苏州、北京、桂林、西安和杭州这五个城市表现优异。
原因分析:
苏州以其古典园林和水乡风貌著称,得益于其深厚的历史文化底蕴和江南水乡的自然景观;
作为中国的首都,北京拥有丰富的历史遗迹和文化景观,如故宫、长城,政治地位和历史积淀使其成为旅游热点;
桂林的山水风光享誉世界,其独特的喀斯特地貌和清澈的漓江水构成了一幅幅自然画卷,吸引了无数游客;
西安是中国四大古都之一,拥有兵马俑、大雁塔等众多历史遗迹,其悠久的历史和丰富的文化遗产是其旅游资源丰富的关键;
杭州以其西湖美景和丝绸文化闻名,经济的繁荣和对自然景观的保护使其成为国内外游客向往的旅游目的地。
也可以绘制热力图来观察
# 绘制热力图
plt.figure(figsize=(10, 8))
sns.heatmap(lc_df, annot=True, fmt="d", cmap="YlGnBu")
plt.title('每个城市对应等级景区的数量')
plt.xlabel('景区等级')
plt.ylabel('城市')
plt.show()

















 6999
6999

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









