







 本文介绍了如何导入并分析旅游景点数据,包括城市分布、评分与销量的关系以及景区价格的考察,通过数据清洗和可视化展示了各城市景点的特征和热门景点的评分情况。
本文介绍了如何导入并分析旅游景点数据,包括城市分布、评分与销量的关系以及景区价格的考察,通过数据清洗和可视化展示了各城市景点的特征和热门景点的评分情况。
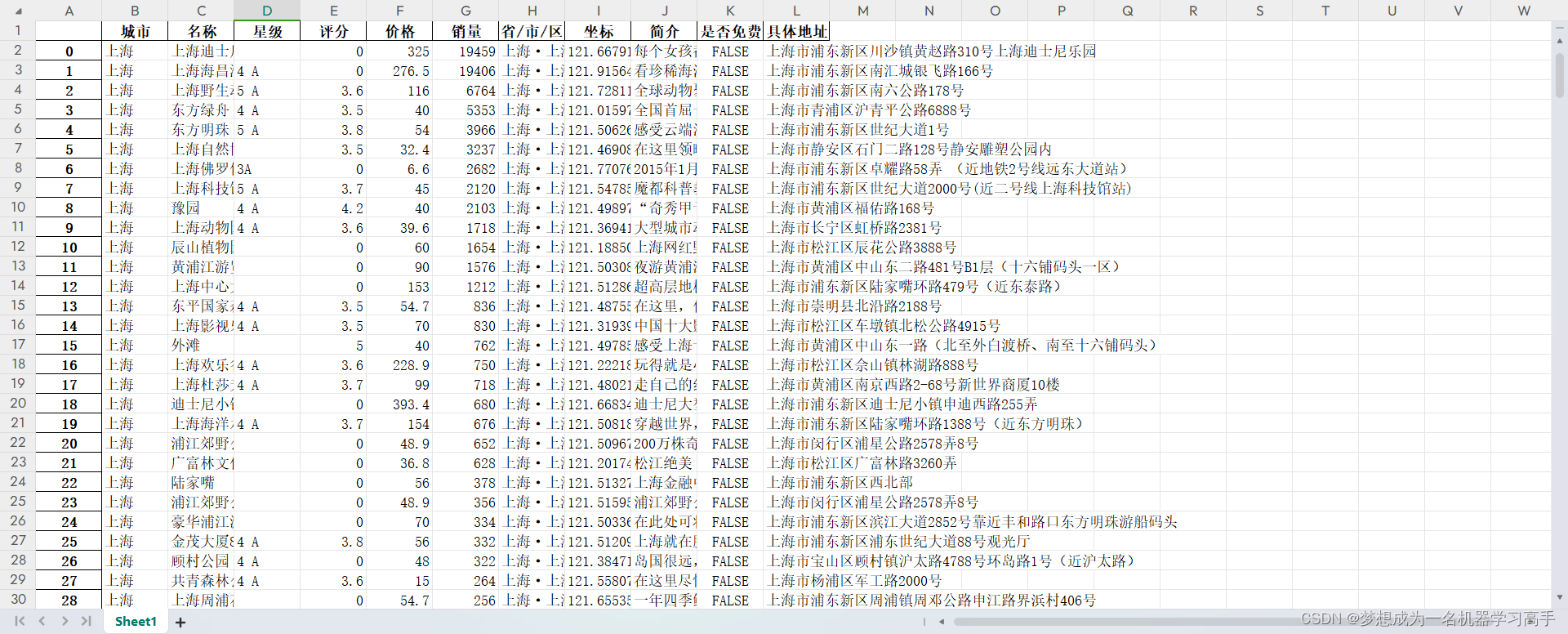
数据的截图,数据的说明:
# 字段 数据类型 # 城市 string # 名称 string # 星级 string # 评分 float # 价格 float # 销量 int # 省/市/区 string # 坐标 string # 简介 string # 是否免费 bool # 具体地址 string
拿到数据第一步我们先导入数据,查看一下数据的分布,类型等
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data = pd.read_excel("旅游景点.xlsx")
pd.set_option("display.max_columns",100)
# print(data.head())
print(data.info())
print(data.isnull().sum())接下来我们来看具体的问题:
# 问题(先大概分析一下) # 1、全国景点分布 (我们分析城市的分布即可) # 2、国民出游分析 (我们可以分析评分,城市,销量之间的关系 ) # 3、景区价格分析 (我们分析价格因素)
# 问题看完之后,我们开始对数据进行预处理 # 由于星级对我们问题的分析帮助很大,所以我们无法用删除,或者众数等方式填充,因此我们用无来填充,将其划分为一个新的类别
data["星级"] = data["星级"].fillna("无")
print(data["星级"].isnull().sum())至于简介和地址,缺失数据无关紧要,这里我们可以选择用无来填充,也可以用删除来处理,为了不破坏数据的完整性,这里我选择用无来填充
data = data.fillna("无")
# print(data.isnull().sum())
# 这样我们的数据就没有了缺失值
# print(data.info())# 1、全国景点分布 (我们分析城市的分布即可)
scenic = data['城市'].value_counts().sort_values(ascending=False)
plt.figure()
scenic.plot(kind='bar',stacked=False,colormap='viridis',figsize=(10,6) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 245
245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









